- 강의 목록
- Self_supervised Pre-training Models : GPT-1, BERT
- Advanced Self-supervised Pre-training Models
- 요약
강의
피어세션
- 학습정리
Pre-trained 모델의 최신 발전 동향
- Transformer와 Self-attention block은 범용적인 인코더와 디코더로써의 역할을 잘 수행해냈다.
- 그래서 자연어 처리 뿐 아니라 다른 분야에서도 활발히 활용 중에 있다.
- Transformer은 6개 정도의 self-attention block을 쌓아서 사용했는데, 최근에는 보다 많은 블럭들을 쌓아서 대규모 데이터의 학습 용도로 사용할 수 있는 Self-supervised Learning 프레임워크으로 학습한 후 다양한 작업에 대해 transfer learning한 형태로 좋은 형태를 보여주고 있다.
- Self-attention 모델은 신약 개발, 추천 시스템, 영상 처리 분야까지도 진출했다.
- 하지만 트랜스포머의 self-attention에 기반한 모델은 자연어 생성의 작업에서, 즉 <sos>부터 하나씩 단어를 생성하는 Greedy Decoding이라는 프레임워크에서 벗어나지 못하고 있다.
GPT-1

- Pre-training 모델의 시초격인 모델
- 테슬라의 창업자인 일론 머스크가 세운 비영리 연구 기관인 OpenAI 에서 출시했다.
- GPT-2,3 까지 이어지며 자연어 생성에서 놀라운 결과를 보여주고 있다.
- GPT-1은 기본적으로 다양한 스페셜 토큰을 제안해 심플한 작업 뿐 아니라 다양하고 많은 태스크를 동시에 커버할 수 있는 통합적인 모델을 제안했다.
- GPT-1의 구조는 입력값을 Text & Position 데이터로 받아 더해 임베딩을 만들고, 12개의 Self-attention 블록들을 쌓고 통과시킨다.
- 텍스트 생성의 경우, Text Prediction으로 보내 첫 단어부터 순차적으로 단어들을 예측하고,
- 문장 분류 혹은 감정 분석의 경우에는 Task Classifier으로 보내 분류를 진행한다.
- Classification : <sos> 문장 <extract token>을 입력으로 받아 인코딩된 <extract token>을 통해 아웃풋 레이어에서 분류를 진행한다.
- ex) 감정분석
- Entailment : <sos> 문장 <delim> 문장2 <extract token>을 입력받아 <extract token>을 통해 아웃풋 레이어에서 논리적으로 내포, 모순 관계인지를 분류한다.
- <delim> : 특수 문자로, 문장을 구분한다.
- ex) 문장들의 논리 확인 : 문장 1이 참이면 문장 2도 참이다 같은 문장의 논리를 확인하는 작업이다.
- Similarity : 문장 간 유사도 측정
- Multiple Choice :
- Classification의 경우 Self-Supervised-learning을 통해 미리 학습한 정보를 활용하는 Pre-trained 모델이다. 그래서 다음 학습부터 자동으로 레이블이 필요없어진다.
BERT

- 현재까지 가장 널리 사용되는 Pre-Trained 모델
- GPT와 마찬가지로 Language 모델링을 위한 용도이다.
- 기존의 pre train은 전후 문맥이 아닌 앞의 단어만으로 다음 단어를 예측했다.
- BERP는 앞의 단어 뿐 아니라, 뒤의 단어도 활용해 전체적인 문맥을 통해 단어를 예측한다. (양방향성)
Masked Language Model : BERT에서의 Pre-trained 모델

- BERT의 단어 레벨의 작업
- 문장 중 몇몇 단어를 <MASK>로 치환하고, 해당 <MASK>에 들어가야 할 값을 유추하는 모델이다.
- <MASK>로 치환하는 단어는 문장을 구성하는 단어 중 15% 정도이다.
- 만약 이보다 높으면 주어진 문장에서 너무 많은 <MASK>가 등장해 <MASK>의 식별을 위한 정보가 너무 부족하다.
- 그렇다고 이보다 낮으면 단어를 찾기 위해 전체 단어를 인코딩하는 과정이 너무 오래 걸린다.
- 그런데 문제가 발생하는데, 15%의 단어들을 전부 <MASK>로 치환하면 부작용들이 생길 수 있기 때문이다.
- PRE-TRAIN 당시에는 기존 문장 중 15%만이 <MASK> 처리 된 문장의 빈 칸을 예측하는 것에 익숙한데, 실제 문장에서는 <MASK>가 없고 그 패턴이 일정하지 못해서 차이가 발생한다.
- 그래서 <MASK> 로 치환하는 문장들을 다음과 같이 다른 형태로 치환한다.

- 즉, 전체를 <MASK> 처리하지 않고 80% 정도의 단어는 <MASK>로 만들고, 나머지 중 50%는 랜덤한 다른 언어로 변경, 그리고 나머지는 원래대로 내버려둔다.
Next Sentence Prediction

- BERT의 문장 레벨에서의 작업
- 하나의 글에서 여러 문장을 추출해 각 문장을 <SEP> 토큰으로 나눈다.
- <CLS> 토큰은 <Extract> 토큰처럼 예측 태스크를 수행하는 토큰으로, Label 토큰이다.
- 여러 문장의 단어 중 몇 개를 <MASK>로 치환한다. 그리고 트랜스포머를 통해 인코딩을 진행한 후, <MASK> 토큰에서 있어야 할 단어를 예측한다. 또한 동시에 <CLS> 토큰을 활용해 Binary Classification을 수행해 해당 문장들이 인접한 문장인지를 예측한다.
BERT Summary
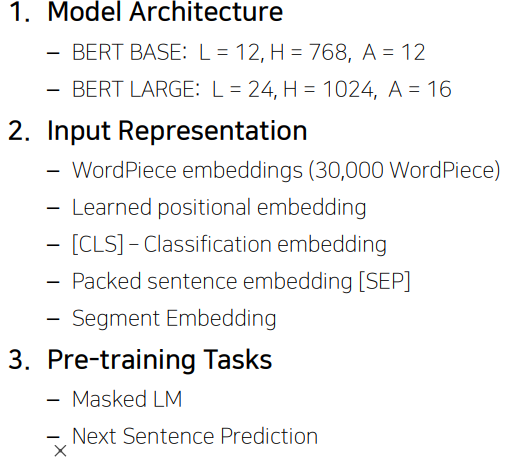
- 모델의 구조 자체는 트랜스포머의 셀프 어텐션 블록을 그대로 사용했다.
- 다만 두 가지 버전의 학습된 모델을 제안했다. (BERT BASE, BERT LARGE)
- L : 셀프 어텐션 블록 수
- H : 각 셀프 어텐션 블록에서 똑같이 유지하는 인코딩 벡터의 차원 수
- A : 각 레이어별 어텐션 헤드의 숫자 (클수록 많은 어텐션 헤드 사용)
- BERT에서는 입력 시퀀스를 워드 별로 자르는 것이 아니라, 보다 작은 단위로 쪼개서 사용한다. (서브워드)
- EX) Pre-trained 와 Pretrined 를 별개의 단어로 규정하던 방식에서 동일한 단어로 규정했다.
- Learned positional embedding : 포지셔널 임베딩 자체도 학습에 의해 결정된다. (추가 필요)
- Segment Embedding : BERT를 학습할 때 각각의 입력값에 해당하는 워드 임베딩 벡터의 포지션 임베딩이 추가적으로 더해지는데, 여러 문장을 넣을 때 문장의 구분은 불가능하다.
- 그래서 Segment Embedding을 추가해 문장을 구분한다.

BERT vs GPT-1

- 학습 데이터의 측면에서 BERT가 더 많은 학습 데이터를 사용했다.
- BERT는 <extract> 토큰이 아닌 <SEP> ,<CLS> 토큰을 통해 라벨을 추출하고 문장을 구분한다.
- 하이퍼 파라미터인 Batch size또한 BERT가 훨씬 많아졌다.
- 즉, 한 번에 학습할 수 있는 워드의 수가 많아졌다. 이로 인해 성능이 더 좋아지고 학습이 안정화 되었다.
- Task-specific fine-tuning : GPT는 lr을 5e-5로 사용하는데, BERT는 lr을 동적으로 유연하게 사용한다.
BERT vs GPT-2

- GPT-2는 주어진 시퀀스를 인코딩 할 때 특정 타임 스텝에서 다음에 나타나는 단어의 접근을 허용하면 안된다. 즉, 일방향성이다.
- 그에 비해 BERT는 MASK로 치환된 단어를 예측하고, 이를 예측하기 위해 모든 단어의 접근을 허용함으로써 양방향성이다.
BERT : Fine-tuning-Process

- 마스크드 언어 모델링과 넥스트 센텐스 프리딕션을 사전 학습한 모델을 여러 가지 다양한 태스크에 Fine-tuning 하는 모델 구조 확인
Machine Reading Comprehension (MRC, 기계 독해)

- BERT를 통해 더 높은 성능을 얻을 수 있는 대표적인 작업
- 질의응답의 한 형태로, 질문만 주어진 것이 아니라 문서가 주어지고, 기계가 독해한 정보에서 질문의 대답인 부분을 예측해 응답한다.
SQuAD 1.1

- 고수준의 MRC를 수행하기 위한 데이터셋
- BERT는 입력으로 지문과 질문을 받는다. 두 문장을 <SEP>으로 구분하고, 인코딩을 진행한다.
- 각각의 지문 상에서의 단어 별 워드 인코딩 벡터가 나오면 그 벡터들로 정답에 해당할만한 위치를 예측하기 위해 공통된 아웃풋 레이어를 통해 스칼라의 결과 값을 얻는다.
- 이 아웃풋 레이어의 파라미터가 랜덤 이니셜라이셜부터 파인 튜닝되는 대상이 되는 파라미터
- 스칼라 값을 얻었으면 답의 시작 위치를 지정한다. 이 과정은 모든 단어의 스칼라 값을 softmax loss를 통해 구한다.
SQuAD 2.0
- 먼저 답이 있는지 없는지를 판단한다.
- 문단과 질문을 종합적으로 보고 판단하는데, 이 때 <CLS> 토큰을 사용해 하나로 합친 후 답이 있는지 없는지 찾는다.
BERT : On SWAG

- 다수 문장을 다루어야 하는 태스크에 BERT를 활용한 예시
- 위의 예시와 같이 주어진 문장 다음에 나와야 하는 문장을 예측한다.
- [CLS] 토큰을 사용하고, 가능한 선택지들을 하나씩 CONCAT해서 아웃풋 레이어를 통해 스칼라 출력 값을 예측한다.
- 모든 스칼라 값을 softmax를 통해 가장 확률이 높은 정답을 예측한다.
BERT : Ablation Study

- 모델의 파라미터와 레이어가 많아지면 성능이 계속 좋아진다.
- 이는 모델 사이즈가 키울 수 있는 만큼 키웠을 때도 개선이 끝없이 좋아진다.
Advenced Self-supervised Pre-training Models
GPT-2
- GPT-1의 후속 버전
- 모델 구조의 측면에서는 1과 크게 다를 바가 없다. 다만 트랜스포머의 레이어를 더 많이 쌓아 모듈을 키웠고, 여전히 LM(Language Modelling)으로 학습을 진행한다.
- 트레이닝 데이터가 40GB로 증가했다.
- 데이터의 용량이 많아진만큼 다양한 지식을 배울 수 있게 했다.
- 언어 생성에서 down-stream 태스크를 zero-shot setting 으로써 전부 다룰 수 있게 했다.
- Motivation은 Multitask Learning as Question Answering이다.
- 기존에는 주어진 문장의 긍정/부정 여부를 판단할 때 문장을 인코딩하고 cls 토큰을 뽑하 바이너리 분류를 하거나, 혹은 대화 시스템에서 문장을 생성한 경우 입력 문장과 출력 문장은 구조상으로 다르다. 하지만 위의 논문에서는 모든 자연어에 관한 태스크들이 질의응답으로 바뀔 수 있다라는 통합된 자연어 생성의 형태로 다양한 태스크들을 학습한 연구 사례이다.
- 요약하면 모든 자연어 처리 태스크는 질의응답 형태로 바뀔 수 있다.
GPT-2 Datasets
- Reddit에서 3개 이상의 좋아요를 받은 게시물들을 크롤링해서 데이터를 구축했다.
GPT-2 Preprocess
- Byte Pair Encoding (BPE)이라고 불리는 서브 워딩으로 단어를 처리한다.
GPT-2 Model
- 레이어가 특정 위치에서 위로 가거나 아래로 가거나, 즉 학습이 진행되도록 선형 변환의 값들이 0에 가까워지게 만들어 뒤에 나오는 레이어들의 역할을 줄인다.
GPT-2 Question Answering
- 앞서 설명했듯 모든 자연어 처리 태스크는 질의응답 형태로 바뀔 수 있다.
- 대화형의 질의응답 데이터로 답을 예측해보았을 때, F1 스코어로 55점이 나왔다. Fine-tuned BERT 학습 결과에는 미치지 못하지만 가능성을 확인할 수 있었다.
GPT-2 Summarization
- TL;DR ( Too long, didn't read) 를 마지막에 추가했다.
- TL;DR이 나오면 앞쪽의 글들을 한 줄 요약하는 형태로 변화한다.
GPT-3
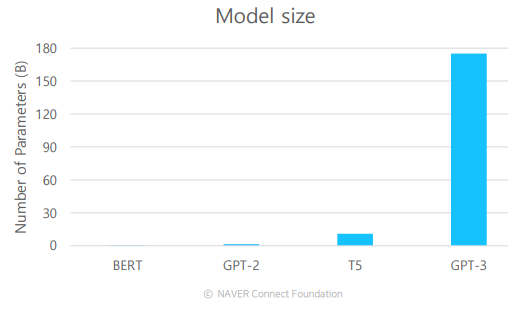
- GPT-2의 파라미터 숫자에 비해 훨씬 많은 파라미터를 가지고 있다.
- 그에 따라 많은 데이터와 큰 배치 사이즈를 통해 학습을 수행할 수 있게 되었다.
- GPT-2에서 가능성을 본 Zero-shot의 성능을 올렸다.
- 번역에 대한 데이터를 직접적으로 전혀 학습에 활용하지 않은 글자를 넣어도 번역이 되는 것.

• Zero-shot: 아무 예시 없이 곧바로 번역 수행
• One-shot: 하나의 예시를 주며 번역을 수행
• Few-shot: 몇 개의 예시를 주며 번역을 수행
*셋 다 별도의 FINE TUNNING이 필요 없이 곧바로 수행이 가능하다.
*모델의 사이즈를 키우면 키울수록 각 SHOT에서의 성능이 올라간다.
ALBERT : A Lite BERT for Self-Supervised Learning of Language Representations
- 앞의 pre-trained 모델들은 대규모의 메모리 용량과 많은 학습이 필요한 파라미터를 가진 형태로 발전했다.
- 이 때문에 점점 더 많은 GPU 메모리, 학습 시간 등을 필요로 했다.
- ALBERT는 기존의 BERT 모델에서 모델 사이즈를 줄여 학습 시간을 줄이고, 성능을 더 좋게 만들었다.
ALBERT의 Factorized Embedding Parameterization

- 기존의 셀프 어텐션 층을 쌓으며 만들어지는 모델은 스킵 연결을 통해 워드 임베딩 벡터의 차원 수를 끝까지 유지해야 했다.
- 그런데 이 차원이 너무 작으면 정보를 담는 공간이 너무 작아지고, 너무 크면 필요한 메모리와 연산량이 너무 많았다.
- 기존 BERT는 각 단어별로 임베딩을 만들어 임베딩 파라미터를 가졌는데, 이를 두 개의 행렬로 나누어 만들었다. 이를 통해 Wordpiece 임베딩과 히든 레이어 사이즈의 크기를 분리하고, 히든 레이어를 크게 만들 수 있었다.
- 큰 임베딩 매트릭스를 작은 두 개의 매트릭스로 나누는 방법으로, V*H인 파라미터를 V*E + E*H인 파라미터로 줄인다.
ALBERT : Cross-layer parameter sharing

- 파라미터의 효율성을 높이기 위해 파라미터를 전부 공유한다.
- 피어세션 회의 내용
어제 말했던 강의 ppt 내 그림(8페이지)
- single self-attention 기준으로는 틀린 말이고, Encoder-Decoder 구조와 같이 서로 다른 input이 들어오는 attention으로 구성된 self-attention기준으로는 맞는 말이다.
Multihead attention
- 병렬연산이 안되는 환경이라면?
- 일단은 Multihead attention을 사용함으로써 얻는 이점이 적어질 것 같다.
- 각 head가 원하는 정보만을 뽑아올 수 있는가?
- 각 head가 내놓는 정보의 domain은 다를 수 있지만, 애초부터 그 domain을 정해놓고 그것에 대한 정보만 뽑아오는건 어려울 것 같다.
positional encoding
- positional encoding이 없으면 문장 내 같은 단어가 두번 등장했을 때 같은 context vector를 output으로 내놓는가?
- 단어 embedding vector가 동일하면 동일하게 내놓을 듯하다.
torch.Tensor의 contiguous()
- 컴퓨터가 연산하기 좋도록 텐서의 메모리 위치를 재배열하는 함수.
- 언제 어떻게 쓰는건지에 대한 내용은 추가적인 질문이나 토론이 필요할 것 같음.
- 해야할 일
'BOOSTCAMP AI TECH > 4주차_자연어 처리' 카테고리의 다른 글
| [BOOSTCAMP AI TECH] 19일차_Transformer (0) | 2021.02.18 |
|---|---|
| [BOOSTCAMP AI TECH] 18일차_Seq2Seq with attention, BLEU (0) | 2021.02.17 |
| [BOOSTCAMP AI TECH] 17일차_RNN, LSTM, GRU (0) | 2021.02.16 |
| [BOOSTCAMP AI TECH] 16일차_BOW, Word2Vec, Glove (0) | 2021.02.15 |



