- 강의 목록
-Bag-of-words
-Word2Vec, Glove
-나이즈베이안 분류, Word2Vec 실습
-NLP 전처리 실습
- 요약
강의
자연어 처리의 동향을 학습했다.
자연어 처리를 위한 Bag of Words, Word2Vec, GloVe 알고리즘을 학습했다.
나이브 베이즈 분류와 word2vec 실습을 진행했고,
NLP 전처리를 실습을 통해 학습했다.
피어세션
파이썬 머신러닝 완벽가이드 책의 군집화와 자연어 처리 파트를 다 함께 학습했다.
- 학습정리
NLP (Natural Language Processing, 자연어처리)
- 컴퓨터와 인간 언어 사이의 상호 작용하는 기술로, 인공지능의 핵심 기능 중 하나이다.
- 크게 NLU (Natural Language Understanding), NLG (Natural Language Generation) 으로 구분된다.
- 비전 분야와 더불어 딥러닝 기술이 활발하게 적용되는 분야이다.
- 최신 딥러닝 기반 모델 및 작업을 포함한다.
- 저수준 구문 분석으로는 토큰화, 스테밍이 있다.
- Tokenization : 문장을 단어 단위로 나누는 것.
- Stemming : 어미의 변화 속에서 의미 변화를 없애고 원래의 의미인 어근을 추출하는 것.
- 단어 및 문장 분석으로는 NER, POS, 명사구 청킹, 종속성 구문 분석, 코어 참조 해상도 등이 있다.
- Named entity recognition (NER) : 단일, 혹은 여러 단어로 이루어진 고유 명사를 하나의 명사로 인식하는 것 (EX) 뉴욕타임즈
- POS Tagging : 품사나 성분이 무엇인지 알아내는 작업으로 기계 번역, 감정 분석, 구문 분석 등의 전처리 과정으로 사용된다.
- 문장 레벨은 감정 분석, 기계 번역 등이 있다.
- Sentiment analysis (감정 분석) : 문장이 어떤 의도나 감정을 나타내는지 자동으로 분류하는 기술
- Machine translation (기계 번역) : 다른 언어의 문장을 또 다른 언어로 번역해주는 기술
- 다중 문장과 문단 수준의 레벨은 수반 예측, 질문 답변, 대화 시스템, 요약 등이 있다.
- Entailment prediction : 두 문장 간 논리적인 내포 혹은 모순 관계 파악
- Question answering : 질문 속 키워드들이 포함된 문서를 검색하고, 문서를 독해해 주어진 질문에 대답
- Dialog systems : 대화를 수행할 수 있는 기술
- Summarization : 문서를 요약하는 기술
*Entailment prediction 예시
-존 또는 지니가 어제 결혼했다. / 지니는 어제 결혼하지 않았다. => 존은 어제 결혼했다.
-어제는 아무도 결혼하지 않았다. / 존은 어제 결혼했다. => 모순
Text Mining
- 텍스트 및 문서 데이터에서 유용한 정보 및 통찰을 추출하는 것.
- ex) 대규모 뉴스 데이터에서 AI 관련 키워드의 동향 분석
- 문서 군집화, 토픽 모델링
- ex) 뉴스 데이터를 클러스터링하고 다른 주제와 그룹화
- 컴퓨터 사회과학과 높은 관련이 있다.
- ex) SNS의 데이터를 기반으로 한 사람들의 정치적 경향의 진화 분석
Information retrieval (정보 검색)
- 컴퓨터 사회과학과 높은 관련이 있다.
- 사실 검색 성능이 충분히 고도화되어 어느 정도 진화한 상태이기에 활발히 연구되지는 않는다.
- 아직도 활발한 연구분야인 추천 시스템으로 발전하였다.
*추천 시스템 : 수동으로 하는 검색을 자동화해서 사용자의 취향에 맞는 것을 추천
NLP의 동향
- 텍스트 데이터는 기본적으로 단어의 시퀀스로 볼 수 있으며, 각 단어는 Word2Vec 또는 GloVe와 같은 기술을 통해 벡터로 표현될 수 있다.
- 이러한 단어 벡터를 시퀀스를 입력으로 사용하는 RNN 관련 모델은 NLP 작업의 주요 아키텍처였다.
- 하지만 attention module과 Transformer 모듈의 등장으로 자연어 처리가 RNN 위주에서 트랜스포머 위주로 바뀌었다.
- Transformer 모델의 경우 대부분의 고급 NLP 모델은 원래 기계 번역 작업을 개선하기 위해 개발되었다.
- 초기에는 다양한 NLP 작업에 대한 맞춤형 모델이 별도로 개발되었으나, Transformer의 도입 이후 기본 모듈인 self-attention을 쌓은 대형 모듈이 출시되었으며, 이러한 모델은 특정 작업에 추가 레이블이 필요하지 않은 self-supervised 트레이닝을 가능하게 만들었다. ex) BERT, GPT-3
- 즉, 단순히 한 분야에 대한 기능에 국한되지 않고 범용 인공지능 기술로 발전했기에 각 영역에 대한 맞춤형 모듈을 능가했다.
- 이러한 모델은 많은 NLP 작업에서 필수적인 부분이 되었지만, 높은 GPU 성능과 그에 따른 자본력을 요구하게 되었다.
Bag of words (BOW)
- 기존의 텍스트 전처리는 다음과 같다.
- 텍스트 데이터셋에서 중복을 제거하고 단어들을 모아 사전(vocabulary) 구축
- 각 워드를 원 핫 벡터로 변경
- Bag of words는 원 핫 벡터로 나타낸 문서나 문장을 확장한 것으로, 각 워드 벡터를 모두 더한 벡터이다.
- 모든 단어를 가방에 넣고, 단어의 총 개수와 각 단어의 빈도수를 추출하는 방법이다.
ex) John really really loves this movie / Jane really likes this song
=> {John, really, loves, this, movie, Jane, likes, song}
=> {1, 0, 0, 0, 0, 0, 0, 0}, ... ,{0, 0, 0, 0, 0, 0, 0, 1}
=> John really really loves this movie = {1, 2, 1, 1, 1, 0, 0, 0},
Jane really likes this song = {0, 1, 0, 1, 0, 1, 1, 1}
NaiveBayes Classifier (나이브 베이즈 분류)
- BOW로 나타낸 문서를 정해진 카테고리로 분류하는 대표적인 방법.
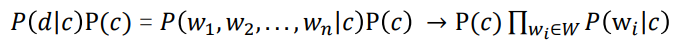
- P(d|c)는 특정 카테고리 c가 고정되었을 때 D가 나타날 확률이다.
- d는 워드 w1, w2, ... , wn 들이 나타나는 동시 사건이다.
- 각 단어가 등장할 확률 c가 고정이고 서로 독립일 경우 모두 곱한 형태로 나타난다.
- 그러면 우리는 여기서 p of c, 즉 어떤 문서가 주어지기 이전에 각 클래스가 나타날 확률과 특정 클래스가 고정되어 있을 때 각 워드가 나타날 확률을 추정해 나이브 베이즈 분류에서 필요로 하는 파라미터를 추정할 수 있다.
나이브 베이즈 분류 예시

- cv 문서가 나타날 확률은 1/2, nlp 문서가 나타날 확률도 1/2이다.

- 목표인 'Classification task uses transformer'을 구성하는 각 단어에 대한 각 클래스의 빈도는 다음과 같다.
(해당 단어 출현수) / (해당 카테고리 문서의 모든 단어 수)

- 나이브 베이즈 분류를 이용해 모든 확률을 곱했을 때의 결과이다.
*위의 추정 방식은 MLE 유도과정을 통해 도출이 되는 과정이다.
*그런데 실제에서는 학습 데이터에 특정 데이터가 특정 카테고리의 문서에 한 번도 포함이 되지 않았는데,
테스트 데이터에서 해당 데이터가 들어간 카테고리를 데이터로 줄 수도 있다.
이미 테스트 데이터에서 해당 클래스에 대한 해당 단어가 0/N 이므로 0을 가지고 있는데, 이러면 어떻게 해도 분류가
안된다.
그래서 일정한 값을 추가로 부여해서 모든 단어에 대해 값이 0이 되지 않도록 유지할 필요가 있다.
class NaiveBayesClassifier():
def __init__(self, w2i, k=0.1):
self.k = k
self.w2i = w2i
self.priors = {}
self.likelihoods = {}
def train(self, train_tokenized, train_labels):
#학습 데이터를 통해 prior 확률과 likelihoods 세팅
self.set_priors(train_labels) # Priors 계산.
self.set_likelihoods(train_tokenized, train_labels) # Likelihoods 계산.
def inference(self, tokens):
#토큰화된 데이터를 받아 클래스 별로 나이즈 베이지안 분류 실행
#그런데 조건부 확률을 계속 거듭해서 곱할건데, 조건부 확률은 당연히 0~1
#그런데 계속 거듭해서 곱하다보면 0에 너무 가까워져서 컴퓨터가 0으로 인식해
#클래스간 비교가 불가능해질 수 있음.
#이를 방지하기 위해 확률을 곱셈하지 말고, 덧셈한 후 로그를 취한다.
log_prob0 = 0.0 #라벨이 0인 경우
log_prob1 = 0.0 #라벨이 1인 경우
for token in tokens:
if token in self.likelihoods: # 학습 당시 추가했던 단어에 대해서만 고려.
log_prob0 += math.log(self.likelihoods[token][0])
log_prob1 += math.log(self.likelihoods[token][1])
# 마지막에 prior를 고려.
log_prob0 += math.log(self.priors[0])
log_prob1 += math.log(self.priors[1])
if log_prob0 >= log_prob1:
return 0
else:
return 1
def set_priors(self, train_labels):
#train_labels를 받아
class_counts = defaultdict(int)
for label in tqdm(train_labels):
class_counts[label] += 1 #라벨들을 보며 각 클래스가 얼마나 등장했는지 count
for label, count in class_counts.items():
self.priors[label] = class_counts[label] / len(train_labels) #다시 돌면서 전체 라벨 갯수에 대해 각 클래스의 등장 확률 측정
def set_likelihoods(self, train_tokenized, train_labels):
# c = argmax p(x1, x2, ... ,xn | c)p(c)
token_dists = {} # 각 단어의 특정 class 조건 하에서의 등장 횟수.
class_counts = defaultdict(int) # 특정 class에서 등장한 모든 단어의 등장 횟수.
for i, label in enumerate(tqdm(train_labels)):
count = 0
for token in train_tokenized[i]:
if token in self.w2i: # 학습 데이터로 구축한 vocab에 있는 token만 고려.
if token not in token_dists:
token_dists[token] = {0:0, 1:0}
token_dists[token][label] += 1
count += 1
class_counts[label] += count
for token, dist in tqdm(token_dists.items()): #k는 스무딩
#라이브 베이지안 분류를 단순히 분류하면 어떤 단어가 특정 분류의 문서 안에 단 한 번도 등장하지 않는 경우가 있음.
#이로 인해 테스트 데이터 안의 특정 분류에 해당 단어가 있어도 0이 될 수 있음.
#이걸 방지하기 위해 스무딩 수행
#count가 0이 되는 것을 방지하기 위해 임의의 상수 k를 넣어줌으로써 최소 count를 맞춰줌.
#이를 Laplace smoothing 이라고 한다.
#즉 확률이 극단적인 값이 되지 않도록 하기 위해 사용
if token not in self.likelihoods:
self.likelihoods[token] = {
0:(token_dists[token][0] + self.k) / (class_counts[0] + len(self.w2i)*self.k),
1:(token_dists[token][1] + self.k) / (class_counts[1] + len(self.w2i)*self.k),
}Word Embedding
- 단어를 벡터로 표현하는 것.
- 풀어 설명하면, 단어들을 특정 공간상의 점(벡터)로 나타내는 것이다.
- 워드 임베딩은 그 자체로 딥러닝 기술인데, 학습 데이터로 텍스트 데이터와 좌표 공간의 차원수를 입력하면, 해당 좌표 공간 안에 나타난 각각의 최적의 좌표값을 출력으로 준다.
- 워드 임베딩은 비슷한 의미의 단어가 비슷한 위치에 매핑되게 함으로써 유사도를 잘 반영한 벡터 표현을 다양한 자연어 처리 알고리즘에 제공한다.
- 즉, 단순 토큰화에 비해 단어간의 유사성과 관계의 표현이 가능하다.
Word2Vec
- 워드 임베딩의 가장 유명한 알고리즘 중 하나.
- 같은 문장에서 나타난 인접한 단어들 간의 의미가 비슷할 것이라고 가정하여 비슷한 의미의 단어들을 가깝게 매핑한다.
- 예를 들어 the cat purrs, the cat hunts mice 문장들이 있을 때, 같은 단어인 cat을 기준으로 앞 뒤의 단어들이 cat과 연관이 있다고 가정한다.
- 따라서 한 단어가 주변에 등장하는 단어들을 통해 의미를 알 수 있다고 생각한다.
- 위의 경우에는 cat 단어를 입력으로 주고 주변 단어를 예측하게 하는 방식으로 학습을 진행한다.
Word2Vec은 크게 두 가지 모형으로 나뉜다.
1) CBOW (Continuous BOW) : 주변 단어를 통해 중심 단어를 예측
2) Skip-gram : 중심 단어를 통해 주변 단어 예측
ex) I am going to school을 윈도우 사이즈를 2로 학습을 하면,
CBOW는 I, AM, TO, SCHOOL을 통해 GOING을 예측하고,
Skip-gram은 GOING으로 나머지를 예측한다.
Word2Vec의 동작 방식
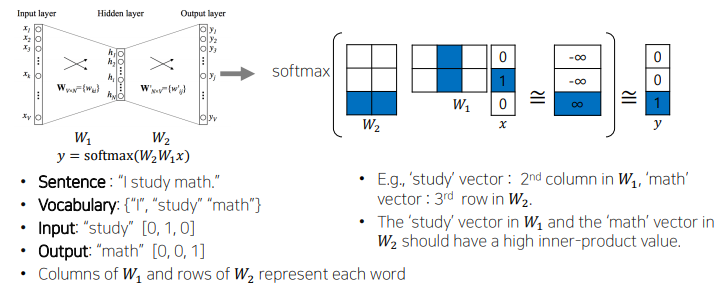
- 문장을 워드별로 분리한다. (Tokenize)
- 유니크한 단어들을 모아 사전을 구축한다.
- 사전의 각 단어를 Vocablary size 만큼의 디멘션을 가지는 원 핫 벡터로 변환한다.
- 슬라이딩 윈도우 기법으로 한 단어를 중심으로 앞뒤로 나타난 단어들과 입출력 단어 쌍을 구성한다.
*슬라이딩 윈도우 방법
예를들어 슬라이딩 윈도우가 1이면,
1) 첫 단어 w1를 중심으로 다음 단어 w2예측
2) w2와 w1을 중심으로 w3 예측
3) 이렇게 반복하여 wk와 w(k-1)을 중심으로 w(k+1) 예측
*히든 레이어는 사용자가 정하는 하이퍼 파라미터로, 위드 임베딩을 수행하는 좌표 공간의 차원 수와 동일한 값으로 설정된다. 위의 경우 임베딩 디멘전을 2로 설정해서 히든 레이어는 2차원, 입력과 출력 노드는 3차원이 되었다.
*마지막에는 소프트맥스를 통해 확률분포로 전환한다.
Word2Vec의 장단점
- 의미론적 관계를 2차원 공간의 벡터의 값을 통해 나타내기에 Analogy Reasoning(유추 추론)을 할 수 있다.
- ex) 한국-서울+일본 = 도쿄
- 여러 단어가 있을 때 가장 의미가 다른 단어를 찾아내는 Intrusion Detection도 가능하다.
- 기계 번역, 키워드 태깅, 고유명사 인식, 감정 분석, 이미지 캡션 등 여러 분야에서 활용이 가능하다.
- 사용자가 지정한 주변 단어의 개수(슬라이딩 윈도우 수)에 대해서만 학습이 이루어지기에 데이터 전체에 대한 정보를 담기 어렵다.
*이미지 캡션 : 주어진 사진의 상황을 자연어로 표현하는 기술
class CBOWDataset(Dataset):
def __init__(self, train_tokenized, window_size=2):
#주변단어 INPUT, 중심단어 OUTPUT
#INPUT 데이터는 2*WINDOWSIZE+1
self.x = []
self.y = []
for tokens in tqdm(train_tokenized):
token_ids = [w2i[token] for token in tokens] #각 토큰을 인덱스로 바꾸고
for i, id in enumerate(token_ids):
if i-window_size >= 0 and i+window_size < len(token_ids): #윈도우 사이즈 주변에 있는 것들을 가져옴
self.x.append(token_ids[i-window_size:i] + token_ids[i+1:i+window_size+1]) #주변단어
self.y.append(id) #중심단어 (전체 데이터)
self.x = torch.LongTensor(self.x) # (전체 데이터 개수, 2 * window_size)
self.y = torch.LongTensor(self.y) # (전체 데이터 개수)
def __len__(self):
#전체 데이터 수
return self.x.shape[0]
def __getitem__(self, idx):
#각 인덱스의 값 리턴
return self.x[idx], self.y[idx]
class CBOW(nn.Module):
def __init__(self, vocab_size, dim):
super(CBOW, self).__init__()
self.embedding = nn.Embedding(vocab_size, dim, sparse=True) #원핫인코딩 된 입력값 크기를 특정 크기의 임베딩 데이터로 변환
self.linear = nn.Linear(dim, vocab_size) #임베딩된 벡터를 다시 원핫인코딩 된 입력값의 크기로
# B: batch size, W: window size, d_w: word embedding size, V: vocab size
def forward(self, x): # x: (B, 2W)
embeddings = self.embedding(x) # (B, 2W, d_w)
embeddings = torch.sum(embeddings, dim=1) # (B, d_w)
output = self.linear(embeddings) # (B, V)
return output
class SkipGramDataset(Dataset):
def __init__(self, train_tokenized, window_size=2):
#INPUT이 중심단어, OUTPUT이 주변단어
self.x = []
self.y = []
for tokens in tqdm(train_tokenized):
token_ids = [w2i[token] for token in tokens]
for i, id in enumerate(token_ids):
if i-window_size >= 0 and i+window_size < len(token_ids):
self.y += (token_ids[i-window_size:i] + token_ids[i+1:i+window_size+1])
self.x += [id] * 2 * window_size
self.x = torch.LongTensor(self.x) # (전체 데이터 개수)
self.y = torch.LongTensor(self.y) # (전체 데이터 개수)
def __len__(self):
return self.x.shape[0]
def __getitem__(self, idx):
return self.x[idx], self.y[idx]
class SkipGram(nn.Module):
def __init__(self, vocab_size, dim):
super(SkipGram, self).__init__()
self.embedding = nn.Embedding(vocab_size, dim, sparse=True)
self.linear = nn.Linear(dim, vocab_size)
# B: batch size, W: window size, d_w: word embedding size, V: vocab size
def forward(self, x): # x: (B)
embeddings = self.embedding(x) # (B, d_w)
output = self.linear(embeddings) # (B, V)
return outputGlove
- Word2Vec과 더불어 워드 임베딩 분야에서 자주 사용되는 방법.
- 각 입력-출력 단어쌍에 대해 학습 데이터에서 주 단어가 한 윈도우 내에서 총 몇 번 동시에 등장했는지 사전에 미리 계산을 하고 입력 워드의 임베딩 벡터 Ui와 출력 워드의 임베딩 벡터 Uj의 내적값이 한 윈도우 안에서 두 단어가 동시에 나타난 횟수인 Pij에 가까워 질 수 있도록 한다.
- Word2Vec은 특정한 입출력 단어쌍이 자주 등장한 경우 여러 번에 걸쳐 학습함으로써 내적값이 커짐으로써 학습이 빈번하기 될수록 더 연관을 주는 학습 방식이다.
- 그에 비해 Glove는 애초에 어떤 단어쌍이 동시에 등장한 횟수를 미리 계산하고 이에 대한 로그값을 두 단어간의 내적값과 큰 차이가 없도록 하는 방식으로, 중복된 계산을 방지한다.
- 이러한 계산상의 차이로 인해 학습이 빠르며 적은 데이터 셋에 대해서도 잘 동작한다.
- 또한 단어 간의 문법적인 의미와 관계들까지 효과적으로 학습히 가능하다.
Glove의 수식

- ui : 입력 워드의 임베딩 벡터
- uj : 출력 워드의 임베딩 벡터
- pij : 윈도우 안에서 두 단어가 동시에 나타난 횟수
Glove의 장단점
- 학습이 빠르다.
- 적은 데이터 셋에서도 잘 동작한다.
- 단어 간의 문법적인 의미와 관계들까지 효과적으로 학습이 가능하다.
- 오픈 소스로 공개되어 있어 얼마든지 사용이 가능하고, 사전에 학습된 워드 벡터들도 사용이 가능하다.
- 피어세션 회의 내용
군집화
K 평균 군집화
- 초기에 군집 중심점을 잡는 방법 : K-means++
- K-means++ : k개의 군집을 설정하기 위해, 임의의 한 데이터를 선정하여 군집 중심점으로 선정하고, 이전에 선정한 데이터들에서 가장 멀리 떨어진 다른 데이터를 군집 중심점으로 선정하며 k개의 군집 중심점을 선정한다.
- Sklearn.cluster.KMeans 함수 사용 시 init 파라미터로 설정할 수 있는데, 디폴트 값이 K-means++ 라서 변경할 건 없다.
- 초기에 군집의 개수를 정하는 것도 중요한데, 그 방법에는 Elbow Method, 손실함수, 실루엣 계수 등이 있다. steadiness-193.tistory.com/285
평균 이동
- 평균 이동의 KDE는 적절한 대역폭 h를 구하는 것이 중요하다.
- 이 대역폭은 평균 이동에서 군집 중심점이 밀도를 판단할 범위와 같다.
차원의 저주
- 차원이 늘어남에 따라 계산량과 메모리 사용량이 빠르게 증가하여 계산 불가 상태에 빠지는 현상.
- 차원이 늘어남에 따라 데이터의 거리가 멀어져 밀집도가 작아지는 현상
- 이 외에도 차원이 늘어남에 따라 나타나는 다양한 문제점들을 통틀어 차원의 저주라 부른다.
- 저차원의 데이터는 문제가 되지 않지만, 고차원의 데이터에서는 문제가 된다.
- PCA, LDA, LLE 등의 차원 축소 알고리즘으로 해결할 수 있다.
토픽 모델링
LSA(Latent Semantic Analysis) ... 잠재 의미 분석
- 토픽 모델링을 위해 설계된 알고리즘은 아니지만, 토픽 모델링을 위한 아이디어를 제공한 알고리즘
- 앞서 본 DTM(Document-Term Matrix), TF-IDF는 counting을 기반으로 하지만, 이것으로 주제를 파악하기에는 한계가 존재
- 앞서 배운 SVD(특이값 분해)를 이용한 방법.
- V^T 행렬에서 임베딩된 단어 벡터를 확인 가능.
- 기존에 쓰던 TF-IDF 행렬을 그냥 SVD하면 되는거라 쉽고 빠름
- SVD는 새로운 데이터를 추가했을 때 또 분해를 처음부터 다시 해야된다는 단점이 있음
LDA(Latent Dirichlet Allocation) - 잠재 디리클레 할당
- 각 문서는 여러 토픽의 혼합으로 이루어져있다고 가정.
- 이 여러 토픽들은 확률분포에 기반하여 단어들을 생성한다고 가정.
- LDA는 문서가 생성되는 과정을 역추적하여 토픽을 찾아냄.
- 어떤 문서의 각 단어 w 자신은 잘못된 토픽에 할당되어져 있지만, 다른 단어들은 전부 올바른 토픽에 할당되어져 있는 상태라고 가정, 이에 따라 단어 w는 아래의 두 가지 기준에 따라서 토픽이 재할당됨.
- p(topic t | document d) : 문서 d의 단어들 중 토픽 t에 해당하는 단어들의 비율
- p(word w | topic t) : 단어 w를 갖고 있는 모든 문서들 중 토픽 t가 할당된 비율
- 이에 따라 각 단어를 반복하여 할당하면 두가지 기준 각각에 단어들이 알맞게 수렴됨.
문서 군집화
- 목적 : 비슷한 텍스트 구성의 문서를 군집화
- 앞선 것과의 차이: 지도학습 vs 비지도학습 (앞에서는 라벨을 주고 로지스틱 회귀를 하였음)
- 방법(순서대로)
- 피처 벡터화(TF-IDF 등)
- 군집화(K-Mean 등)
- KMeans 객체의 clusters_centers_ 속성을 이용하여 각 단어의 중요도 파악
문서 유사도
- 목적 : 두 문서 간의 유사도 측정
- 코사인 유사도는 두 벡터 간의 유사도를 측정하기 위해 사용됨.
- 문서(단어)를 벡터화했다면 코사인 유사도 방법 적용 가능
한글 텍스트 처리
- 한글은 라틴어 계열 언어보다 구조가 단순화시키기 어렵기 때문에 처리가 어려움.
- 그렇지만 아무튼, 기존처럼 피처 벡터화만 잘 하면 기존 모듈들을 사용할 수 있음.
- 다음과 같은 모듈 종류가 있음(참고 사항으로, Mecab은 2/15 오늘 실습에서 사용해봤습니다~)
- KoNLPy
- Mecab(리눅스 기반에서만 돌아가도록 설계되었으나 현재는 윈도우에서도 사용 가능한 방법이 있긴 함)
Mercari Price Suggestion Challenge 실습에서 짚고 넘어갈 점
- 어떻게 보면 그냥 회귀 문제인데, 피처값들을 분석하기 위해 여기에 피처벡터화를 적용, 텍스트 분석.
- 가격에 log를 씌워 왜곡된 가격 분포를 정규분포에 근사하게 만듦
- 짧은 텍스트는 Count기반 벡터화, 긴 텍스트는 TF-IDF 기반 벡터화
- 앞에서 배웠던 각종 기법들을 함께 적용(LightGBM 모델, 앙상블 기법 등)
- 해야할 일
희소표현, 밀집표현, 워드 임베딩
원핫 인코등의 출력값인 원핫 벡터들은 표현하고자 하는 단어의 인덱스 값만 1이고 나머지는 0이다. 이러한 행렬을 희소 벡터, 희소 표현이라고 한다.
희소 표현은 단어의 개수가 늘어나면서 벡터의 차원이 한없이 커진다. 이는 곧 공간적 낭비로 직결된다.
밀집 표현은 희소 표현과 반대되는 표현이다. 밀집 표현은 벡터의 차원을 단어 집합의 크기로 상정하지 않고, 사용자가 설정한 값으로 모든 단어를 벡터 표현의 차원에 맞춘다.
즉, [0 0 0 0 0 1 ... 0]으로 표현되던 희소 표현을 [0.2 0.4 .0.8 ... -2.4] 등으로 맞추며 벡터의 차원을 조밀하게 바꾼 것이다.
단어를 밀집 벡터의 형태로 표현하는 것이 바로 워드 임베딩이다. 즉, 밀집 벡터는 워드 임베딩 과정을 통해 나온 결과물인 임베딩 벡터이다.
워드 임베딩 방법에는 LSA, Word2Vec, Glove, FastText 등이 있다.
불용어 (Stopword) : 의미 분석에 크게 상관이 없지만, 언어의 특성상 자주 등장하는 단어들.
#영어 불용어
import spacy
spacy.lang.en.stop_words.STOP_WORDS
자연어 처리에 대한 이해를 높이기 위해 간단한 프로그램을 만들었다.
github.com/123okk2/Naver_News_title_classification
'BOOSTCAMP AI TECH > 4주차_자연어 처리' 카테고리의 다른 글
| [BOOSTCAMP AI TECH] 20일차_Self-supervised Pre-training Models (0) | 2021.02.19 |
|---|---|
| [BOOSTCAMP AI TECH] 19일차_Transformer (0) | 2021.02.18 |
| [BOOSTCAMP AI TECH] 18일차_Seq2Seq with attention, BLEU (0) | 2021.02.17 |
| [BOOSTCAMP AI TECH] 17일차_RNN, LSTM, GRU (0) | 2021.02.16 |



