- 강의 목록
- Recurrent Neural Networks(RNNs)
- LSTM and GRU
- 요약
강의
시퀀셜 데이터를 다루는 모델인 RNN, LSTM, GRU의 개념과 학습법에 대해 학습했다.
그리고 실습을 통해 각 모델의 사용법을 학습했고, 과제를 통해 전처리를 학습했다.
피어세션
어제 배운 실습 코드를 복습하며 Word2Vec과 네이브 베이즈 분류를 재학습했다.
- 학습정리
Recurrent Neural Networks (RNNs)

- 다양한 길이를 가진 시퀀스 데이터에 특화된 유연한 구조의 딥러닝 구조
- Vanilla RNN은 구조가 매우 간단하지만 경사도 손실, 폭주 문제가 존재한다.
- 시퀀스 데이터가 입력, 출력으로 주어진 상황에서 히든 스테이트의 출력값을 저장하고, 다음 학습의 입력으로 받아 활용한다.
- 타임스탭에서의 h(t)는 입력 x(t)와 이전 학습의 결과를 이용해서 결과를 예측한다.
- 서로 다른 타임스탭에서의 입력 데이터를 처리할 때 동일한 파라미터를 가지기에 반복적으로 등장하는 모듈이다.
- 매 타임 스텝에서 히든 스테이트 벡터를 계산한 후 하고자 하는 태스크에 맞는 출력값 y를 계산해야 한다.
RNN의 구성요소

- h(t-1) : 이전 학습 결과인 히든 스테이트 벡터
- x(t) : 타임스텝 t에서의 입력 벡터
- h(t) : 현재 학습 결과인 히든 스테이트 벡터
- f(w) : w를 파라미터로 받는 RNN 함수
- y(t) : 최종 예측값. h(t)를 바탕으로 계산할 수 있다.
*y(t)는 매 스텝마다 계산해야 할 수도 있고, 맨 마지막에만 예측해야 할 수도 있다.
ex) 문장 내 모든 단어의 품사 예측 : 매 스텝마다 계산 / 문장의 감정 분석 : 맨 마지막에 예측
Types of RNNs

1) One-to-one
- 일반적인 구조의 뉴럴 네트워크.
- 입력과 출력이 하나이다.
- 타임 스텝으로 이루어진 데이터가 아닌 일반적인 형태를 도식화
- ex) 키, 몸무게, 혈압 => 2차원 벡터의 은닉층 => 혈압 상태(고혈압, 정상혈압, 저혈압) 출력
2) One-to-many
- 이미지 캡션 분야에서 많이 사용된다.
- 입력이 하나의 타임 스탭, 출력이 여러 타임 스탭
- 입력으로 하나의 이미지를 받아 이미지에 대한 설명을 타임스탭별로 순차적으로 생성한다.
- 구조상 첫 번째 타임스탭의 은닉층에만 입력값이 들어가는데, 두 번째 타임스탭의 은닉층에서는 0으로 이루어진 같은 사이즈의 벡터, 행렬, 텐서가 들어간다.
3) Many-to-one
- 감정 분석에 많이 사용된다.
- 입력으로 여러 타임 스탭의 시퀀스 데이터를 받아, 하나의 결과 값을 출력한다.
- 은닉층의 층 수는 고정된 것이 아니라, 입력 타입 스탭의 시퀀스 길이만큼 생성된다.
- ex) 입력으로 문장을 받아 감정 상태(긍정, 부정) 출력
4) Many-to-many
- 입력과 출력이 전부 시퀀스 구조이다.
- 기계 번역에 많이 사용된다.
- 입력 문장을 끝까지 다 읽은 후 각 단어에 대한 번역 결과를 순차적으로 내놓는다.
- 그래서 위와 같이 입력이 3이면 3부터 출력이 나오기 시작한다.
5) Many-to-many
- 딜레이 없이, 문장을 전부 읽지 않고 읽자마자 예측 수행
- pos 태깅으로 문장의 성분을 유추하거나, 프레임 레벨의 비디오 분류 (해당 프레임이 어떤 장면인가?) 수행
- 실시간성이 요구되는 경우 사용하는 구조이다.
Character-level Language Model
- 자연어 데이터에 할 수 있는 가장 간단한 태스크
- 주어진 문자열에서 다음 단어를 예측하는 태스크가 가능한데,
- 캐릭터 레벨은 주어진 문자열에서 다음 문자를 예측한다. ex) hell => o
순서
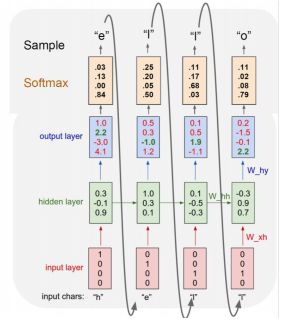
- 사전을 구축한다. hello => [h e l o]
- 원 핫 벡터로 표현. [h e l o] => [1 0 0 0]. [0 1 0 0], [0 0 1 0]. [0 0 0 1]
- 은닉층에서 ℎ𝑡 = tanh(𝑊ℎℎ*ℎ𝑡−1 + 𝑊𝑥ℎ*𝑥𝑡 + 𝑏) 공식에 따라 계산 수행
- 출력값으로 Logit = 𝑊ℎ𝑦*ℎ𝑡 + 𝑏 계산 수행
- softmax로 분류하고 다음 입력으로 활용하여 순차적으로 다음 글자 예측
*위의 예시는 softmax 값이 sample 값과 다른데, softmax loss를 적용하여 네트워크를 학습시켜야 한다.
캐릭터 레벨의 언어 모델링의 학습 과정

- 매 타임스텝마다 주어진 캐릭터가 있고, 거기서 발생된 히든 스테이트 벡터를 통해 아웃풋레이어를 통과한 후 나온 예측값과 각 타임스텝에서 나와야 하는 다음 캐릭터에 대한 비교값의 loss function을 통해 학습이 진행된다.
- 입력값이 히든 스테이트 벡터로 들어갈 때 사용되는 w(xh)와 이전 타임스텝의 데이터가 활용되는 w(hh), 아웃풋으로 가는 w(hy)가 Backpropagation에 의해 학습이 된다.
- 그런데 입력 시퀀스 길이가 너무 길면 한정된 리소스(cpu, gpu)를 오버할 수 있다.
- 그래서 Truncation으로 한 번에 모든 시퀀스를 넣지 않고, 잘라서 넣는다.

RNN의 한계

- RNN은 구조상 동일한 매트릭스를 매 타입스텝마다 곱할 수 밖에 없다.
- 이로 인해 역전파가 기하급수적으로 커지거나, 작아짐으로써 경사도가 소실되거나 폭주한다.
- 경사도가 소실되거나 폭주되면 여러 타임스텝 전의 정보를 제대로 기억할 수 없다.
- 이러한 문제 때문에 사실상 Vanilla RNN(Basic RNN)은 잘 사용되지 않고, LSTM과 GRU가 많이 사용된다.
*BPTT(BackPropagation Through Time) : RNN에서의 역전파 방법
*Teuncated BPTT : BPTT의 문제를 해결하기 위해 타임 스텝을 일정 구간으로 나누어 역전파 계산
*하지만 Truncated BPTT는 장기간의 패턴이 발생하면 학습할 수 없다.
PyTorch에서의 RNN
- torch.nn.RNN(*args, **kwargs)
| input_size | 입력 x의 길이 | hidden_size | 은닉층의 수 (이만큼 출력) |
| num_layers = 1 | 반복 레이어 수 (몇 층) | nonlinearity = tahn | tahn or relu |
| bias=True | False이면 가중치 사용 안함 | batch_first=False | True면 입력 및 출력 텐서가 (batch, seq, feature) |
| dropout = 0 | 드롭 아웃 비율 | bidirectional=False | True이면 양방향 RNN |
- RNN(input_size=100, hidden_size=10) => Linear(hidden_size, num_classes) : 히든 사이즈의 shape 데이터를 받아 정해진 클래스로 분류
- 출력은 output, h_n
LSTM & GRU
- RNN의 또 다른 구조로써, 기존의 RNN을 대체하는 모델이다.
- 경사도 손실 및 폭주, Long term dependency 측면에서 훨씬 더 좋은 효율을 보인다.
- Cell state 벡터 (Hidden State 벡터)의 연산을 RNN은 곱셈을 사용했지만 LSTM과 GRU는 덧셈을 사용함으로써 경사도 손실, 폭주 문제를 해결했다.
LSTM (Long Short-Term Memory)
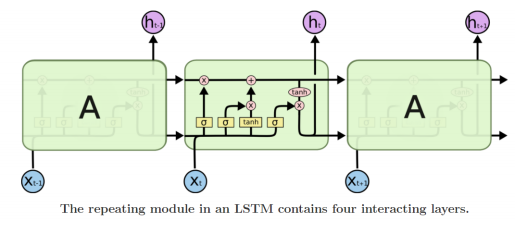
- RNN에서의 Long term dependency 문제를 해결한 구조이다.
- 매 타입스텝마다 변화하는 히든 스테이트 벡터를 단기 기억을 담당하는 소자로 볼 수 있다.
- 이 단기 기억을 시퀀스가 타임 스텝이 진행되어도 길게 기억할 수 있게 개선한 모델이다.
LSTM의 구조

- C(t-1) : 이전 타임 스텝의 셀 스테이트 벡터
- H(t-1) : RNN의 히든 스테이트 벡터
- X(t) : 입력 벡터
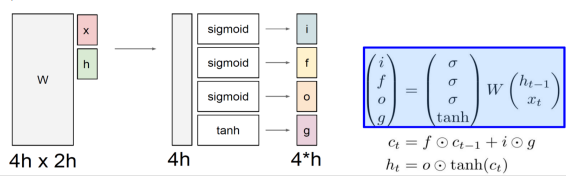
- x : 입력 벡터 / h : 이전 스텝의 히든 스테이트 벡터 / w : 선형 변환 시켜서 4h의 형태로 출력해주는 함수
- i : input gate : 현재 정보를 저장할지 결정하는 과정
- f : forget gate : 과거 정보를 버릴지 말지 결정하는 과정
- o : output gate : 어떤 값을 출력할지 결정하는 과정
- g : gate gate : tanh의 특성상 -1~1이 나오게 된다. : 유의미한 정보를 담는 역할
LSTM 게이트
1) Input gate

- 새로 추가되는 정보가 얼마나 중요한지 결정하는 게이트
- g로부터 만들어진 값을 조정하므로 시그모이드 함수를 사용하며, 원소별 곱을 통해 g의 값을 조정한다.
2) Forget gate

- 이전 셀까지의 기억 c(t-1)중 필요하지 않은 기억을 얼마나 지울지 결정
- 시그모이드 함수를 통해 작동한다.
3) output gate

- 다음 계층에 얼마나 허용해줄 것인지, 즉 얼마나 영향을 미치게 할 것인지 결정
- 시그모이드 함수로 작동한 후 tanh을 씌워 원소별로 곱해 최종 출력값을 구할 수 있다.
4) Gate gate
- 망각 게이트만 있다면 새로운 토큰 x(t)로부터 오는 값은 영향을 많이 주지 못하게 된다.
- 때문에 새로운 정보를 만들어내기 위해 tanh를 사용해 새로운 정보를 만들어낸다.
LSTM의 문제점
- OUTPUT 게이트가 출력을 담당해 LSTM의 블록별 cell state가 output 게이트에 따라 달라진다.
- 그래서 output 게이트가 계속 닫혀있으면 (시그모이드 결과가 0이 되면) cell state에 접근할 수 없다.
- 이를 해결하기 위해서는 핍홉 연결 (peephole connections)를 사용한다.
- cell state에 각 게이트를 연결하여 cell state를 각 게이트에 전달하는 것이다.
PyTorch 의 LSTM
- torch.nn.LSTM(*args, **kwargs)
| input_size | 입력 x의 길이 | hidden_size | 은닉층의 수 (이만큼 출력) |
| num_layers = 1 | 반복 레이어 수 (몇 층) | bias=True | False이면 가중치 사용 안함 |
| batch_first=False | True면 입력 및 출력 텐서가 (batch, seq, feature) | dropout = 0 | 드롭 아웃 비율 |
| bidirectional=False | True면 양방향 LSTM |
- 출력은 output, (h_n, c_n)
GRU (Gated Recurrent Unit)

- LSTM의 모델 구조를 정형화해서 메모리를 적게 소모하고, 빠른 계산이 가능하도록 한 모델
- LSTM의 Cell state 벡터와 Hidden State 벡터를 일원화해서 Hidden State 벡터만 사용한다.
- 전체적인 동작 원리는 LSTM과 비슷하다.
- LSTM은 forget gate와 input gate를 사용했지만, GRU는 이 둘을 합쳐 input gate만을 사용한다. forget gate는 (1 - input gate)
- input gate를 z(t), forget gate를 (1-z(t))로 표현한다.
LSTM과 GRU에서의 역전파
- 정보를 담는 주된 벡터인 Cell state 벡터가 업데이트 되는 과정이 RNN과 다르다.
- RNN은 계속해서 곱해주지만, LSTM과 GRU는 계속해서 서로 다른 값인 forget gate를 곱하여 중요하지 않은 건 잊고, 곱셈이 아닌 덧셈을 사용하기에 경사도 손실, 폭주 문제를 해결했다.
- 덕분에 경사도가 변동이 없어 더 긴 타임스텝의 시퀀스 데이터를 다룰 수 있다.
PyTorch에서의 GRU
- torch.nn.GRU(*args, **kwargs)
| input_size | 입력 x의 길이 | hidden_size | 은닉층의 수 (이만큼 출력) |
| num_layers = 1 | 반복 레이어 수 (몇 층) | bias=True | False이면 가중치 사용 안함 |
| batch_first=False | True면 입력 및 출력 텐서가 (batch, seq, feature) | dropout = 0 | 드롭 아웃 비율 |
| bidirectional=False | True면 양방향 LSTM |
- 출력은 output, h_n
- 피어세션 회의 내용
- nn.embedding layer의 input이 one-hot-encoding이 아닌가?
- -> 해당 vocab index를 input으로 받는다.
- Fully connected layer의 경우 3차원 이상의 tensor에 대해서 어떻게 연산이 진행되나?
- -> Pytorch 공식 문서의 shape 부분을 참조해보면 알 수 있다.
- 해야할 일
핍홉 연결

- LSTM에서 gate controller는 입력 x(t)와 이전 타임스텝의 단기 상태인 h(t-1)만 입력으로 받는다.
- 이를 대체하여 핍홉 연결은 이전 타임스텝의 장기 상태 c(t-1)이 입력으로 추가되어, 좀 더 많은 맥락을 인식할 수 있다.
- 텐서플로에서는 핍홉 연결을 구현하기 위해 LSTMCell을 사용하고 use_prrphomes 인자를 True로 설정한다.
PackedSequence
| I | love | dog | => | I | love | dog | <pad> | |
| No | way | No | way | <pad> | <pad> | |||
| I | need | your | help | I | need | your | help |
- NLP에서 매 배치마다 고정된 문장의 길이로 만들어주기 위해 <pad> 토큰을 넣는다.
- 그러나 이를 통해 연산을 진행하면 쓸모 없는 <pad>까지 계산을 해야한다. 그래서 <pad>를 계산하지 않고 효율적인 학습의 진행을 위해서 병렬 처리를 해야 한다.
- 예를 들어 타임스텝이 2인 걸 계산하려면, <dog, <pad>, your>을 계산해야 하는데, pad가 포함되어 있다.
- 이를 위해서는 RNN의 히든 스테이트가 이전 타임스텝에 의존해서 최대한 많은 토큰을 병렬적으로 처리해야 하고, 각 문장의 마지막 토큰이 마지막 타임 스텝에서 계산을 멈춰야 한다.
- 즉, 1번 문장은 2, 3번 문장은 1 타임 스텝에서 계산이 멈춰야 한다.
- 그래서 문장의 길이를 기준으로 모든 문장들을 내림차순으로 정렬한 후, 하나의 통합된 배치로 만들어준다.
| I | need | your | help | => | I | need | your | help |
| I | love | dog | I | love | dog | <pad> | ||
| No | way | No | way | <pad> | <pad> |
- 이렇게 놓고 계산하면 <pad> 토큰을 계산하지 않는다. 즉, 타임스텝 2부터는 1, 2번 문장만 보고 3부터는 1번 문장만 본다. 그래서 더 빠른 연산이 가능하다.
- PyTorch에서 활용하는 방법은 torch.nn.utils.rnn.pack_padded_sequence를 사용하면 된다.
- 파라미터로 내림차순으로 정렬된 데이터를 nn.Embedding으로 임베딩하고 transpose 한 행렬과, 각 행의 길이가 담긴 텐서 리스트를 넣어주면 된다.
참고 : simonjisu.github.io/nlp/2018/07/05/packedsequence.html
Teacher Forcing
- Seq2Seq을 기반으로 한 모델에서 많이 사용하는 기법이다.
- 티처 포싱은 target word(Ground Truth)를 디코더의 다음 입력으로 넣어주는 기법이다.
- Seq2Seq 모델은 디코더의 출력을 다음 인코더의 입력으로 넣는다. 하지만 한 지점의 디코더의 출력이 잘못 되었다면, 그 이후에는 계속해서 잘못된 출력이 나온다.
- ex) 입력 : 식사는 / 예상 : 식사는 맛있게 하셨습니까? / 출력 : 식사는 잘 모르겠어요.
- 이러한 단점을 해결하기 위해 티처포싱을 적용한다.
- 2번째부터의 인코더 입력 값에 Ground Truth를 별도로 넣어주는데, 학습시 더 정확한 예측을 가능하게 해 초기 학습 속도를 빠르게 올릴 수 있다.
- 물론 마냥 좋은 기술은 아닌 것이, 추론 과정에서는 사용이 불가능해서 학습 단계와의 차이가 발생한다. 이는 모델의 성능과 안정성을 떨어뜨리고, 노출 편향 문제라고 한다.
*다만 노출 편향 문제는 모델에 큰 문제를 일으키지 않는다.
'BOOSTCAMP AI TECH > 4주차_자연어 처리' 카테고리의 다른 글
| [BOOSTCAMP AI TECH] 20일차_Self-supervised Pre-training Models (0) | 2021.02.19 |
|---|---|
| [BOOSTCAMP AI TECH] 19일차_Transformer (0) | 2021.02.18 |
| [BOOSTCAMP AI TECH] 18일차_Seq2Seq with attention, BLEU (0) | 2021.02.17 |
| [BOOSTCAMP AI TECH] 16일차_BOW, Word2Vec, Glove (0) | 2021.02.15 |



