728x90
반응형
- 강의 목록
- Generative Models1
- Generative Models2
- 요약
강의
Generative models에 대한 학습을 진행했다.
피어세션
어제의 내용을 복습하고, 파이썬 머신러닝 완벽 가이드 책을 바탕으로 분류 알고리즘의 종류를 학습했다.
- 학습정리
Generative Models
- Generative Model은 단순히 이미지, 문장 등의 데이터를 생성하는 것이 전부가 아니다.
- 단순 데이터 생성 (Generation) 뿐 아니라, 이상탐지 (Density estimnation)도 가능하다.
- implicit 모델 : 단순히 데이터를 생성할 수 있는 모델
- explicit 모델 : 데이터를 생성할 뿐 아니라 입력에 대한 확률값을 얻어내는 모델
Basic Discrete Distributions

- 베르누이 분포 : 나올 수 있는 경우가 2개인 경우의 확률분포
- 베르누이 분포는 파라미터 하나로 모든 확률을 표현할 수 있다.
- 카테고리 분포 : 나올 수 있는 경우가 n개인 경우의 확률분포
- 카테고리 분포는 n-1개의 파라미터가 전부 필요하다.
- 주어진 학습 데이터의 확률 분포를 찾아내기 위해 몇 개의 파라미터가 필요한지 먼저 찾아야 한다.
- 마르코브 체인은 원래 일정 기간의 상태에만 영향을 받는다.
- 그런데 거기에 이전의 분포에만 의존하는 것을 추가해 조건부 독립이 된다.
Conditional Independence (조건부 독립)
- 여러 개의 변수를 다루는 확률 문제에서 중요한 요소
- 아래의 세 가지 규칙이 중요하다.

- Chain rule은 확률변수간 의존성과 관계 없이 성립한다.
- Conditional Independence에서

- Markcov assumption에 의해 번째가 에만 종속인 것뿐만 아니라 번째가 1까지 종속인 것도 Auto-regressive model.
AR 모델의 종류
1) NADE (Neural Autoregressive Density Estimator)

- i번째 값이 모든 이전 값과 종속인 상태의 AR 모델
- NADE는 explicit model이기에 주어진 입력값들의 확률을 계산할 수 있다.
- 만약 continuous random variable이라면 Gaussian mixture 모델을 활용해 continuous distribution을 만들 수 있다.
2) Pixel RNN

- pixel을 생성하기 위한 AR 모델
- RNN을 통해 Generation을 수행한다.
- Row LSTM과 Diagonal BiLSTM을 활용한 모델들이 있다.
- Row LSTM은 해당 픽셀의 위쪽의 픽셀을 활용한다.
- Diagonal BiLSTM은 i 번째 이전의 정보를 활용한다.
Latent Variable Models
Variatonal Auto Encoder
- Variation Inference (VI)의 목적은 Posterior distribution을 찾는 것.
- Posterior distribution이란 나의 관찰값이 주어졌을 때 내가 관심이 있는 random variable에 대한 확률분포
- Variational distribution은 일반적으로 posterior distribution을 구하기 어려울 때가 많아 이 분포에 근사하는 분포를 말한다.
- VI에서는 KL divergence라는 매트릭으로 variational distribution과 posterior distribution을 줄인다.
- Variational Auto-Encoder는 explicit한 모델이 아니기에 가능도 추정이 어렵다. 또한 prior fitting term은 미분가능해야 하는데, 그래서 diverse latent prior distribution을 사용하기 어렵다.
- 모든 아웃풋 차원이 서로 독립인 isotropic Gaussian을 사용한다.
- posterior의 값을 모르는데 근사법을 구하기 위해 ELBO 트릭을 사용한다.
ELBO 트릭

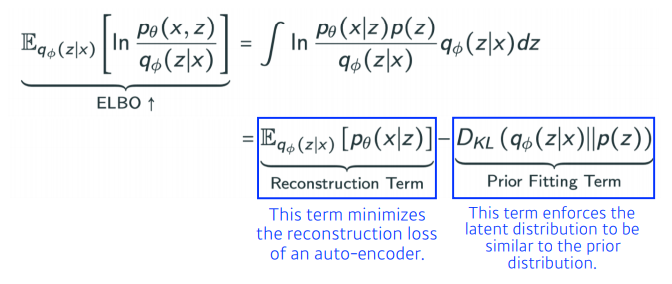
- 맨 마지막 수식의 첫번째 항을 Reconstruction Term이라 부르며, auto-encoder의 reconstruction loss에 해당된다.
- 두 번째 항은 Prior Fitting Term으로, latent distribution이 prior distribution과 비슷하도록 해주는 Term
- ELBO는 두 확률분포가 가우시안 분포를 따르기에 다양한 활용은 어렵다.
Adversarial Auto-encoder

- VAE의 경우 가우시안이 아닌 경우에는 활용이 어렵다.
- Adversarial Auto Encoder은 GAN을 활용해 latent distributions의 분포를 맞춰주는 방법.
Generative Adversarial Network
- Generator와 Discriminator을 설정하여, 생성자는 판별자를 속이기 위해 데이터 생성을 학습하고, 판별자는 생성자가 생성한 것을 판별하기 위해 학습한다.


- 피어세션 회의 내용
- GBM-XGBoost, lightGBM 에 대한 설명
- 또한 XGBoost 실습 코드 리뷰
- ligthGBM 균형 트리에 신경 x. → 이전의 방식과 다름.
- 불균형 분포를 가진 데이터에 대한 오버샘플링 → 정밀도 재현율의 트레이드 오프
- 스태킹 학습에서 test를 학습한 결과를 평균내어 테스트 데이터 생성..
- 해야할 일
모든 설명이 너무 수학적이어서 잘 이해가 되지 않았다.
여러 번 반복해서 읽고 여러 자료를 찾아봄으로써 더 깊은 이해를 가질 필요성을 느꼈다.
728x90
반응형
'BOOSTCAMP AI TECH > 3주차_Deep Learning Basics' 카테고리의 다른 글
| [BOOSTCAMP AI TECH] 14일차_Recurrent Neural Network (0) | 2021.02.04 |
|---|---|
| [BOOSTCAMP AI TECH]13일차_Convolution Neural Network (0) | 2021.02.03 |
| [BOOSTCAMP AI TECH] 12일차_최적화 & CNN (0) | 2021.02.02 |
| [BOOSTCAMP AI TECH] 11일차_딥러닝 기초 (0) | 2021.02.01 |



