- 강의 목록
-RNN 첫걸음
-Sequential Models - RNN
-Sequential Models - Transformer
- 요약
강의
이전의 CNN까지는 Sequential data를 다룰 수 없었다.
오늘의 강의에서는 Sequential data를 다루는 여러가지 모델에 대한 설명과, 그 활용법을 익혔다.
피어세션
어제의 학습을 복습하는 시간을 가졌고, 분류에 관한 각종 알고리즘 (랜덤 포레스트, 결정 트리 등)에 대해 학습했다.
- 학습정리
Sequential data (시퀀스 데이터)
- 독립동등분포 조건을 만족하지 않는 순차적 데이터
- 순서를 바꾸거나 과거 정보에 손실이 발생하게 되면 확률 분포도 변경되는 데이터
- 소리, 문자열, 주가, 동영상 등이 있다.
- 이벤트의 발생 순서가 중요한 요소이다.
- 과거 정보 또는 앞 뒤 맥락 없이는 예측이 불가능하다.
*시계열 데이터는 시간 순서에 따라 나열된 데이터로, 시퀀스 데이터에 속한다.
시퀀스 데이터를 다루는 법
1) 조건부 확률

- 조건부확률을 통해 이전 시퀀스의 정보로 앞으로 발생할 데이터의 확률분포를 다룰 수 있다.
- 단, 시퀀스 데이터를 분석할 때 모든 정보가 필요하지는 않다.
- 또한 조건부에 들어가는 데이터는 가변적일 수 있다.
- 그래서 시퀀스 데이터를 다루기 위해선 길이가 가변적인 데이터를 다룰 수 있는 모델이 필요하다.
2) AR 모델 (Autoregressive Model)


- 고정된 길이 t 만큼의 시퀀스만 사용하는 경우 AR 자기회귀 모델이라 부른다.
- 직전 정보를 제외한 나머지 정보들을 H라는 잠재변수로 인코딩해서 활용한다.
- 즉, 직전의 정보와 그 이전의 정보를 따로 묶어 모델을 만든다.
- 해당 방식 사용 시 가변적인 길이의 입력값을 고정된 길이의 시퀀스 데이터로 다룰 수 있고, 과거의 모든 데이터를 활용해 예측할 수 있다.
- 그러나 잠재변수 H를 어떻게 인코딩 할 것인가가 문제였다.
- 이를 해결해 잠재변수 H를 신경망을 통해 반복 사용해 시퀀스 데이터의 패턴을 학습하는 모델을 RNN이라 한다.
RNN

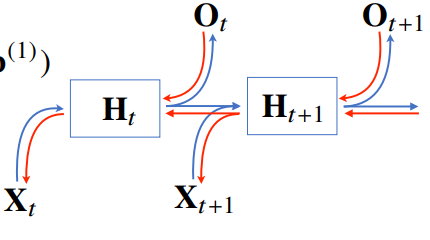
- 가장 기본적인 RNN 모형은 MLP와 유사한 모형이다.
- RNN은 이전 순서의 잠재변수와 현재의 입력을 활용하여 모델링한다.
- H를 계산할 때 새로운 가중치 행렬이 등장한다. 입력으로부터 전달되는 Wx 가중치 행렬과, 이전 잠재 변수로부터 전달받아 만든 Wh 행렬을 만든다.
- t 번째 잠재변수는 현재 들어온 입력 벡터인 Xt와 이전 시점의 잠재변수인 Ht1을 만들어내고, 이를 이용해 현재 시점의 Ot를 만들고, 이 잠재변수를 O(t+1)에 이용한다.
- 잠재변수인 H를 복제해 다음 순서의 잠재변수를 인코딩하는데 사용한다.
- RNN의 역전파는 잠재변수의 연결 그래프에 따라 순차적으로 계산하는데, 이를 Backpropagation Through Time (BPTT)라고 한다.
Backpropagation Through Time (BPTT)

- RNN의 역전파는 잠재변수의 연결 그래프에 따라 순차적으로 계산
- 다음 시점인 t+1 에 들어오는 경사도와 출력에서 들어오는 경사도를 입력과 그 이전의 잠재변수로 전달하고 이를 통해 학습이 이루어진다.
- BPTT를 통해 각 가중치 행렬을 미분하면 위의 PRODUCT TERM에서 I+1부터 t 시점까지 모든 잠재변수의 미분값이 곱해진다.
- 이 때 시퀀스의 길이가 길어지면 곱해지는 term들이 불안정해진다. 미분값이 1보다 크면 발산하고, 작으면 수렴한다. (경사도 손실, 발산)
- 그래서 관찰된 모든 데이터를 고려하는 것보다, 너무 길어지지 않게 하는 것이 중요하다.
Truncated BPTT

- 시퀀스 길이가 길어지는 경우 BPTT를 통한 역전파 알고리즘의 계산이 불안정해져 길이를 끊어야 한다. 이를 Truncated BPTT라 한다.
Sequential Model
- 입력의 차원을 알 수 없는 Sequential Data들이 모델에 들어올 때, 모델은 입력의 개수에 관계없이 동작해야 한다.
- 기존의 MLP, CNN 등의 모델은 고정적인 차원을 가지지 않는 Sequential data의 처리가 어렵다.
Naive Sequential model

- 가장 간단한 시퀀스 모델. 이전의 데이터들을 받아 다음의 데이터를 예측한다.
- 입력값의 길이가 가변적이기 때문에 일반화가 어렵다.
- 시간이 지날수록 고려해야 하는 과거의 정보가 점점 늘어난다.
Autoregressive model

- 참조하려는 과거의 데이터를 제한해 차원을 고정시키는 방법
- AR-n 모델은 과거 n개의 시점까지만 고려하는 모델이다.
- 현재는 과거 n개의 step에만 dependent 하다고 가정하는 것이다.
Markov Model (first-order autoregressive model)

- Markovian assumption을 따르는 모델.
- 현실적으로 매우 많은 정보의 손실이 일어나지만, 결합 분포를 매우 간단히 표현할 수 있다.
*Markovian assupmption : 현재는 바로 직전의 과거에만 영향을 받는다.
Latent autoregressive model

- Markov model의 단점인, 과거의 정보를 너무 많이 잃어버리는 상황을 극복
- Latent AR 모델은 중간에 Hidden state(h),가 과거의 정보를 요약하여 담고 있다.
- 겉으로 보기에는 하나의 과거 상태 h(t)에만 의존하지만, 여기서 어떻게 latent state을 만드느냐에 따라 많은 종류로 나뉜다.
Recurrent Neural Networks (RNN)

- 구조 자체는 MLP와 유사하나, 자기 자신에게 돌아오는 구조가 추가되었다.
- t 시간에서의 hidden state ht는 xt에만 의존하는 것이 아니라, 그 이전의 hidden state ht-1에도 의존한다는 것이 요지이다.
- RNN을 시간순으로 풀어 표현하면, 중간의 가중치를 공유하고 입력이 굉장히 많은 완전 연결층의 형태로 표현할 수 있다.
- 하지만 RNN은 Long-term dependency가 어렵다.
Long short term memoty (LSTM)

- RNN의 Long-term dependency 문제를 극복한 모델이다.
- LSTM은 3개의 게이트를 통해 경사도 손실 문제를 방지하고 경사도가 효과적으로 흐르게 한다.
- Forget gate : 과거 정보를 잊기 위한 게이트로, sigmoid 결과가 0이면 버린다.
- input gate : 현재 정보를 업데이트하기 위한 게이트이다. sigmoid와 tanh 결과로 음수가 출력될 수 있다.
- outpuy gate : 최종 결과 h(t)를 위한 게이트
Gated Recurrent Unit (GRU)

- Reset gate, update gate로 구성된다.
- LSTM을 간소화한 것으로, cell state를 없애고 hidden state로 역할을 수행한다.
- LSTM보다 GRU가 파라미터 수가 적기에 성능을 더 좋게 내기도 한다.
Transformer

- RNN의 재귀적인 구조를 사용하지 않는다.
- attention이라는 구조에 기반을 둔 모델이다.
- 입력과 출력 데이터의 길이가 다를 수 있다. (CNN/RNN 은 동일했음)
- 입력과 출력의 차원(도메인)이 다를 수 있다.
*주변 입력값에 따라 출력값이 변경되므로 훨씬 많은 것을 표현할 수 있다.
*다만 그만큼 연산이 길어진다. RNN의 경우는 길이가 아무리 길어도 입력이 한 개씩 들어오기에 시간만 있으면 학습이 가능. 그런데 트랜스포머는 한 번에 모든 단어를 넣어 공간복잡도가 O(n^2)으로 매우 긴 길이의 시퀀스에 대해서는 computational bottleneck 현상이 발생한다.
Transformer 구조

- Transformer는 크게 보면 같은 갯수로 stack된 인코딩 파트와 디코딩 파트로 나눌 수 있다.
- RNN 모델은 단어를 시간에 따라 하나씩 넣었지만, Transformer는 단어 시퀀스를 한 번에 받는다.
- 인코딩 파트 : 들어온 단어 시퀀스에서 특징 추출
- 디코딩 파트 : 추출한 특징들로 새로운 시퀀스 표현
*결과적으로 Sequence-Sequence 모델이다.
*Stack된 각 인코더와 디코더는 동일한 구조를 가지지만, 파라미터는 다르게 학습된다. (별개의 모델)
Encoder의 구조

- 먼저 단어 시퀀스를 input으로 넣기 위해 각 단어를 특징 벡터로 표현한 Embedding Vector로 변환한다.
- Embedding vector는 self-attention층을 거쳐 새로운 벡터로 변환된다.

- 인코더와 디코더 모두 self-attention 구조가 포함된다.
- self-attention 구조는 Transformer 모델의 핵심 구조이다.
- self-attention 층에서는 입력값들이 서로 의존적이다.
- 즉, z1을 도출하는 데 x1 뿐 아니라 x2, x3의 정보도 함께 활용한다.
Encoder의 동작

- 각 임베딩 벡터를 각각의 가중치와 곱하여 Query vector, key vector, value vector를 뽑는다.
- 한 임베딩 벡터 당 세 개의 벡터가 나온다.
- 참고로 모든 단어에서 각 벡터를 뽑아내기 위한 행렬이 똑같다.
- 작동 과정은 다음과 같다.

- 쿼리 벡터와 벨류 벡터를 이용해 score를 계산한다.
- 그 벡터의 쿼리 벡터를 n개 임베딩 벡터의 키 벡터에 각각 내적해 값을 구한다.
- 두 임베딩 단어 간 유사도를 구할 수 있는데, 내적 값이 클수록 유사도가 큼을 의미한다.
- 소프트맥스 함수를 거쳐 확률로 나타낸다. (attention weight)
- attention weight과 벨류 벡터를 곱한다.
- 벨류 벡터의 차원과 키/쿼리 벡터의 차원은 달라도 된다.
- 모든 임베딩 벡터에 대한 소프트맥스 * 밸류 값을 모두 더한 값이 출력이 된다. (weight sum)
*1에서 self-attention의 의미가 스코어링을 통해 어떤 단어를 주의깊에 보아야 하는가를 찾아내는 작업임을 알 수 있다.
Multi-headed attention

- 헤드를 여러 개 두어 하나의 임베딩 벡터에 대해 여러 개의 쿼리, 키, 밸류 벡터를 만든다.
- 원논문에서는 8개의 헤드에서 별대로 인코딩하여 8개의 인코딩 벡터를 언든다.
- 병렬처리의 이점을 가지며 여러 관점에서 연관도를 찾아내는 방법.
- 그런데 인코더는 stack 되어 있기에 input과 output의 차원이 같아야 한다.
*100차원 input이 있다면 헤드가 8개인 MH를 통과하면 800차원이 된다. 하지만 input과 output을 같게하기 위해 100차원 임베딩 벡터를 10차원 10개로 쪼개 10개 head에서 학습하면 인코딩 후 concatenation을 해 다시 100차원으로 돌아오게 한다. 이럼으로써 linear mapping을 해주지 않아도 된다.
Positional Encoding
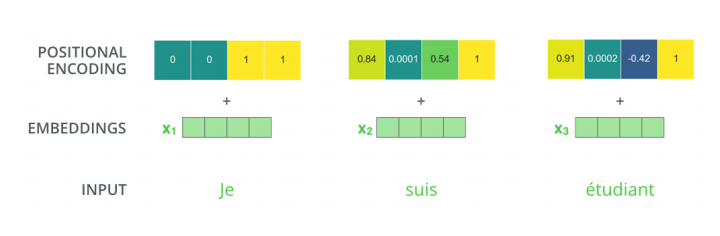
- 위 과정에서 sequence 정보에 대한 이야기를 하지 않았다.
- sequence 정보에서 데이터의 순서에 대한 정보를 넣기 위해 Positional encoding이라는 과정을 거친다.
- 위치 정보에 일종의 bias를 넣어 더해주는 과정.
Noramalize

- ResNet의 Skip connection과 비슷한 역할을 한다.
- 역전파에 의해 positional encoding이 손실될 위험이 있어 위와 같은 처리를 한다.
- 이를 Layer Norm (Add & Normalize)라 표현한다.
Decoder

- Encoder와 구조는 거의 똑같으나, 작동 방식이 다르다.
- 작동 순서는 다음과 같다.
- 최하단의 mask attention을 수행한다. 아직 출력되지 않은 미래의 단어에 대한 attention을 적용하지 않기 위함
- 여기는 self attention으로 인코더의 출력과는 관계가 없다.
- 여기서 미래 정보들은 모두 masking out 된다.
- 다음 단에서 encoder stack의 최종 출력의 key, value 벡터와 현재 디코더에 들어온 입력 벡터를 query 벡터로 사용하는 Encoder-Decoder Attention을 수행한다.
- 최종적으로 Feed Forward를 거쳐 최종값을 벡터로 출력
- 디코더 또한 stack되어 있어 위의 과정을 반복한다.
- 매 첫단계에는 넣어줄 입력값이 없기에 일반적으로 special token을 넣어주고, 다음부터는 이전의 출력값을 입력값으로 넣는다.
- 디코더에서도 multi-headed attention과 positional encoding 사용
- 최종 레이어에서는 디코더의 출력 벡터를 학습한 단어의 갯수만큼의 차원으로 linear mapping 후 sofrmax를 통해 최종 출력 단어 예측
- 이 떄 원 핫 인코더가 아닌 라벨 인코딩을 사용해 한쪽으로 편향되는 학습을 방지한다.
- 피어세션 회의 내용
Prameter가 많으면?
1) 오버피팅이 발생할 수 있다.
2) 그라디언트 소실/폭주로 인한 학습 저하가 발생할 수 있다.
Semantic Segmentation heat map을 생성하기 위해 결과적으로 output이 1*1*c 가 아닌 w*h*c가 나와야 한다.
(w, h > 1)
- 해야할 일
'BOOSTCAMP AI TECH > 3주차_Deep Learning Basics' 카테고리의 다른 글
| [BOOSTCAMP AI TECH] 15일차_Generative model (0) | 2021.02.07 |
|---|---|
| [BOOSTCAMP AI TECH]13일차_Convolution Neural Network (0) | 2021.02.03 |
| [BOOSTCAMP AI TECH] 12일차_최적화 & CNN (0) | 2021.02.02 |
| [BOOSTCAMP AI TECH] 11일차_딥러닝 기초 (0) | 2021.02.01 |



