- 강의 목록
- Pandas 1
- 딥러닝 학습방법 이해하기
- 요약
강의
1강에서는 앞으로 사용하게 될 파이썬의 판다스 라이브러리에 대해 학습했다.
2강에서는 딥러닝의 학습방법에 대한 설명을 들었다.
피어세션
몇 차례 프로젝트에 활용한 경험이 있는 CNN과 RNN 중 조금 더 이해도가 있는 CNN에 대해 설명했다.
CNN의 탄생 배경과 간략한 개념을 설명했고, LeNet-5, AlexNet, VGGNet, ResNet에 대해 설명했다.
시간관계상 GoogleNet은 생략했다.
- 학습정리
Pandas
- 구조화된 데이터의 처리를 지원하는 라이브러리
- 엘셀같은 테이블형 데이터를 처리하는 데 효율적이다. (데이터 테이블)
- numpy와 통합하여 강력한 스프레드시트 처리 기능 제공
- 인덱싱, 연산용 함수, 전처리 함수 제공
- 데이터 처리 및 통계 분석
import pandas as pd
import numpy as np
data_url = 'http://archive.ics.uci.edu/ml/machine-learning-databases/housing/housing.data'
df_data = pd.read_csv(data_url, sep='\s+', header = None) #csv 타입 데이터 로드, separate는 빈공간으로 지정하고 칼럼없음
print(df_data.head())
df_data.columns = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV']
print(df_data.head())
Pandas 데이터 구성
- DataFrame : 데이터 테이블 전체
- Series : 하나의 열에 해당하는 데이터들
- Index : 행
- Numpy와의 차이점은 index값을 지정할 수 있다는 점이다.
- 인덱스 값을 기준으로 Series가 생성된다. Value 범위를 넘어서면 NaN이 값
#series : 데이터프레임 중 하나의 칼럼에 해당하는 데이터 모음 (열)
l = [1,2,3,4]
lname = ['one', 'two', 'three', 'four'] #인덱스 지정 가능
#만약 인덱스 값이 value의 범위를 초과하면 value에는 NaN입력
df_data = pd.Series(data = l, index=lname)
print(df_data)
df_data = pd.Series(data = l) #인덱스 미지정시 0~
print(df_data)
print(df_data[0]) #1 접근은 설정한 인덱스로 접근
df_data[0] = 10
print(df_data)
#이름 지정 가능
df_data.name = 'name'
df_data.index.name = 'indName'
print(df_data)
#DataFrame : 데이터테이블 전체를 포함하는 객체
#사실 DataFrame()으로 선언하는 경우는 거의 없고 csv 파일을 읽어오면 자동으로 됨
raw_data = {"first_name" : ['Lee', 'Park', 'Cho', 'Kim'],
"last_name":["L", "P", "C", "K"],
"age" : [10, 30, 50, 20],
"city" : ["경기","서울","대전","인천"]}
df = pd.DataFrame(raw_data)
print(df)
#loc : index location
#iloc : index position
print(df.loc[:2]) #index num이 2인 데까지
print(df.iloc[:2]) #그냥 두 개
#Boolean 값의 리스트 만들기.
df.debt = df.age > 20
print(df.debt)
#열 추가
values = pd.Series(data=["M","F","M"], index=[0,1,3])
df["sex"] = values
print(df) #열이 지정되지 않은 값을 NaN
#열 삭제
del df["sex"]
print(df)
values = pd.Series(data=["M","F","M"], index=[0,1,3])
df["sex"] = values
print(df) #열이 지정되지 않은 값을 NaN
df.drop("sex", axis=1, inplace=True)
print(df)
#조회
print(df["first_name"])
print(df[["first_name", "last_name"]].head(2))
#만약 [] 로 하면 시리즈로 뽑히는데, [[]]로 하면 데이터프레임으로 뽑힘
print(df.head(2).T)
print(df["first_name"][:3])
print(df[["first_name", "last_name"]][:3])
print(df[df["age"]<21])
#행 삭제
df = df.drop(1) #안에 list로 하면 여러 개 삭제
print(df)
df = df.reset_index() #list index 재정렬
print(df) #근데 이렇게 하면 원래의 index로 index 열이 새로 생김
#df = df.reset_index(drop='True') 하면 안생김
#inplace=True 하면 df = 을 붙이지 않아도 원본 변화
#df.T : Transpose
#df.values : array형식으로 값 출력
#to_csv() : csv 변환
Pandas 기본 함수들
#연산
#add, sub, div, mul 다 가능.
s1 = pd.Series(range(1,6), index=list('abcde'))
s2 = pd.Series(range(5,11), index=list('bcdeef'))
print(s1.add(s2)) #겹치는 걸 반환하는데, 겹치지 않는 index는 NaN 반환
print(s1.add(s2, fill_value=0)) #NaN이 싫으면 이렇게 하면 원래 값으로 가져옴.
#데이터프레임이면 axis = 0으로 기준값을 결정하면 row broadcasting 가능. (모든 열에 더함)
print(s1+s2)
#map : 선언 혹은 일부 변경
s1 = pd.Series(np.arange(10)) #0~9
s2 = s1.map(lambda x : x**2) #0 1 4 9 ... 81
print(s2)
s1 = s2.map(s1) #s1의 같은 index 값에 s2 입력. 일부분 변경시 사용.
print(s2)
values = pd.Series(data=["M","F","M"], index=[0,1,3])
df["sex"] = values
print(df) #열이 지정되지 않은 값을 NaN
#map으로 열 추가
df["sex_code"] = df.sex.map({"M" : 0, "F" : 1})
print(df)
del df["sex_code"]
df.sex.replace(["M","F"], [0,1], inplace=True)
print(df)
print(df.sum()) #열별 합. maen, std도 가능.
#직접 람다나 함수를 만들어 df.apply(함수명)으로 해도 됨.
#pandas 함수
#df.describe() : 숫자형 값들에 대해 요약 정보 출력 : count, mean, std 등
#df.열이름.unique() : 해당 열의 값 목록 출력
#df.sum(axis = 0) : 열별 합, 1이면 행별 합
#mean, sub, min, max, count, median, mad, var 등도 가능
#df.isnull() : null이면 True, 아니면 False
#df.isnumm().sum() 으로 응용하면 null의 갯수 출력 가능
#df.sort_values(["열이름1","열이름2"], ascending=True) #정렬, ascending : 오름
#df.열이름.corr(df.열이름) #특정 열과의 상관계수
#df.corrwith(df.열이름) #전체 열과의 상관계수
#df.열이름.cov(df.열이름) #특정 열과의 공분산
Softmax

- 모델의 출력을 확률로 해석할 수 있게 변환해주는 연산
- 분류 문제를 풀 때 선형모델과 소프트맥스 함수를 결합해 예측한다.
- 추론 문제를 풀 때는 원-핫 벡터로 최대값을 가진 주소만 1로 출력하는 연산 사용.
#--softmax--#
def softmax(vec) :
denumerator = np.exp(vec - np.max(vec, axis=-1, keepdims=True))
numerator = np.sum(denumerator, axis = 1, keepdims = True)
val = denumerator / numerator
return val
vec = np.array([[1,2,0], [-1,0,1], [-10,0,10]])
print(softmax(vec))
#--one hot encoder--#
def one_hot(val, dim) :
return [np.eye(dim)[_] for _ in val]
def one_hot_encoding(val) :
vec_dim = vec.shape[1]
vec_argmax = np.argmax(vec, axis=1)
return one_hot(vec_argmax, vec_dim)
vec = np.array([[1,2,0], [-1,0,1], [-10,0,10]])
print(one_hot_encoding(vec)) #추론
print(one_hot_encoding(softmax(vec))) #분류
신경망
- 신경망은 선형모델과 활성함수를 합성한 함수
- 활성함수는 비선형함수로 잠재벡터의 각 노드에 개별적으로 적용해 새로운 잠재벡터를 만든다.
- 다층 퍼셉트론 (MLP)는 신경망이 여러층 합성된 함수로, L개의 가둥치 행렬로 이루어져 있다.
- 이론적으로 2층 신경망으로도 임의의 연속 함수 근사가 가능하다. (universal approximation theorem)
- 그런데 층이 깊을수록 목적함수를 근사하는데 필요한 뉴런의 숫자가 줄어 효율적 학습이 가능하다. 그래서 2층 이상의 신경망을 쌓는다.
- 층을 낮게 만들려면 필요한 뉴런의 숫자가 더 늘어서 넓은 신경망이 되어야 한다.
활성함수
- R 위에 정의된 비선형 함수
- 활성함수를 쓰지 않으면 딥러닝은 선형모형과 차이가 없다
- 선형모델은 and와 or은 해결이 가능하나 xor을 해결할 수 없다.
- 활성함수는 선형분류기를 비선형 시스템으로 만들 수 있다.
- 시그모이드 함수나 tanh 함수는 전통적으로 많이 쓰이던 활성함수지만 딥러닝에선 ReLU 함수를 많이 사용한다.
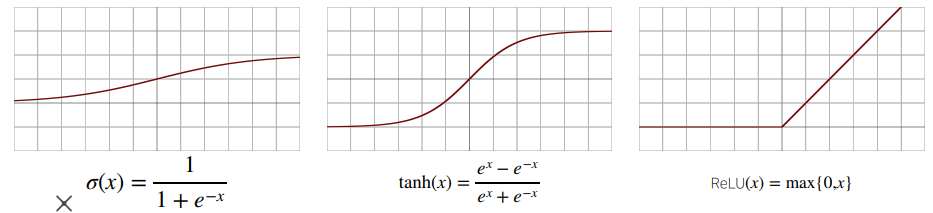
역전파 알고리즘
- 딥러닝은 역전파 알고리즘을 이용해 각 층에 사용된 패러미터를 학습한다.
- 각 층 패러미터의 그레디언트 벡터는 윗층(출력층)부터 역순으로 계산한다.
- 역전파 알고리즘은 합성함수 미분법인 연쇄법칙 기반 자동미분을 사용한다.
- 연쇄법칙을 통해 합성함수의 미분 계산이 가능하다.
- 각 노드의 텐서 값을 컴퓨터가 기억해야 미분 계산이 가능하다.
- 피어세션 회의 내용
CNN의 간략한 개념과 대표적인 모델들을 설명하는 시간을 가졌다.
사실 해본지 1년이 넘어 거의 다 까먹은 상태였는데, 설명을 위해 다시 한 번 공부함으로써 나 또한 공부할 수 있는 기회를 가졌다.
또한 피어 소개를 위한 발표자료를 만들었다.
- 해야할 일
대학교에 재학하며 CNN, GAN, RNN을 다루어 프로젝트를 진행해보았다. 물론 GAN을 활용한 프로젝트 당시에는 인공지능 파트를 완전히 다른 팀원에게 양도하고 나는 오직 안드로이드 파트 개발에만 몰두했기 때문에 GAN은 사용했다고 말하기도 애매한 수준이다.
하지만 CNN과 RNN (특히 LSTM)은 분명 한 번씩 활용했으며, (LSTM은 학습 데이터 부족으로 실패) 활용을 위해 공부한 기억이 있다. 하지만 발표를 위해 CNN을 다시 공부함으로써 CNN에 대한 지식들을 대부분 까먹었음을 인지했다.
Convolutional Neural Network (합성곱 신경망, CNN)
*주의 : 개인 공부용으로 작성한 글이라 틀린 내용이 존재할 수 있음. 1) Why was CNN developed? 기존에는 DNN (Deep Neural Networks)를 사용했다. 그러나 DNN은 1차원 형태의 데이터를 사용하는 모델로..
123okk2.tistory.com
RNN도 마찬가지일 것이고, RNN도 다시 공부를 해서 개념을 기억해낼 필요성을 느꼈다.
'BOOSTCAMP AI TECH > 2주차_AI를 위한 수학' 카테고리의 다른 글
| [BOOSTCAMP AI TECH] 10일차_시각화 도구, 통계학 맛보기 (0) | 2021.01.29 |
|---|---|
| [BOOSTCAMP AI TECH] 9일차_Pandas 2, 확률론 (0) | 2021.01.28 |
| [BOOSTCAMP AI TECH] 7일차_경사하강법 (0) | 2021.01.26 |
| [BOOSTCAMP AI TECH] 6일차_Numpy/벡터/행렬 (0) | 2021.01.25 |



