이전 포스팅에서 이어진다.
https://123okk2.tistory.com/400
멀티노드에 Hadoop 설치해보기
Hadoop 하둡은 빅데이터의 처리를 위한 자바 기반의 오픈소스 프레임워크로, 야후의 더그 커팅이 '넛치' 라는 검색 엔진을 개발하는 과정에서 대용량의 비정형 데이터를 철이하기 위해 구글의 GFS
123okk2.tistory.com
이전 포스팅에서 확인할 수 있다시피 멀티노드에 Hadoop을 설치하는 작업을 수행해보았다.
겉보기에는 정상적으로 설치가 완료되긴 했으나, 그렇다고 장담할 수도 없었다. 이유라면 아래와 같았다.
- 메뉴얼이 별도로 명확하게 존재하지 않아 인터넷의 여러 글들을 종합해 설치했으므로 정상적으로 설치가 된 것인지 확신할 수 없다.
- 각 에코시스템을 테스트하는 방법을 몰라 확실하게 설치가 완료되었다고 확신할 수 없다.
- 설치가 정상적으로 되었더라도 추후 문제 발생 시 유지보수를 하는 방법을 명확하게 알 수 없다.
물론 위의 이유들은 막연한 불안감일 수도 있으나, 어쨌든 이런 불안감을 가지고 싶지 않았다.
그러던 중 우연히 Apache Bigtop이라는 프로그램에 대한 존재를 알게되었다.
Apache Bigtop은 하둡의 간편한 설치를 지원하고, 모니터링이 가능한 UI를 통해 유지보수도 지원해주는 오픈소스 툴이었다.
Apache Bigtop을 사용하면 위의 문제점들을 전부 해결할 수 있을 것 같아 한 번 설치 실험을 해보았고, 언제든 사용할 수 있도록 해당 경험을 작성해놓고자 한다.
사전준비
Apache Bigtop을 활용한 하둡 설치도 이전 포스팅에서와 같은 사전 준비가 필요하다.
다만 Apache Bigtop을 이용한 설치는 이전 포스팅에서 만든 네 개의 노드 서버에서 하둡&에코시스템만 삭제해버린 환경이기에, 사전준비 설정이 이미 완료된 상태이므로 별도로 기재하진 않겠다.
필요 시 이전 포스팅의 사전 준비 부분을 참고하길 바란다.
(단, Docker를 활용한 Zookeeper 설치는 생략해야 한다. Apache Bigtop을 이용한 설치 과정에서 설치되기 때문이다.)
이전 포스팅에서 서술한 사전준비 사항 외에 설정해야 할 사항은 아래와 같다.
먼저 필요 패키지들과 maven을 설치한다.
yum install -y rpm-build
yum install -y python-devel
yum install -y git
yum install -y gcc
yum install -y gcc-c++
cd /opt
wget https://archive.apache.org/dist/maven/maven-3/3.6.3/binaries/apache-maven-3.6.3-bin.tar.gz
tar -xvf apache-maven-3.6.3-bin.tar.gz
mv apache-maven-3.6.3 /opt/maven
maven 설치가 끝났다면 /etc/profile에 MAVEN_HOME을 설정한다.
vim /etc/profile
export MAVEN_HOME=/opt/maven
export PATH=$PATH:$MAVEN_HOME/bin
source /etc/profile
설정까지 끝났다며 mvn -version 명령어를 통해 정상 설치 여부를 확인한다.
Apache Bigtop 설치 및 실행
Apache Bigtop은 github에 올라온 버전을 설치한다.
cd /opt
git clone https://github.com/apache/bigtop.git
이제 /opt/bigtop으로 진입하여 다음 명령어를 순차적으로 입력한다.
cd bigtop
## Namenode01
./gradlew task --all
./gradlew task ambari-pkg
./gradlew task bigtop-ambari-mpack-pkg
./gradlew task bigtop-utils-pkg
## 나머지 노드
./gradlew task --all
./gradlew task ambari-pkg
*ambari-pkg 설치는 몇 시간이 소요된다.
*ambari-pkg 설치 시 HBase에서 진도가 넘어가지 않을 수 있는데, 에러가 난 게 아니라 그냥 오래 걸릴 뿐이므로 기다리도록 한다.
위의 작업이 모두 완료되었다면 /opt/bigtop/build 내부에 ambar, bigtop-ambari-mpack, bigtop-utils 폴더가 생성된다. 그리고 각 폴더 내에는 rpm 파일들이 생성될 것이다.

이제 생성된 rpm 파일들을 이용해 패키지들을 설치한다.
- 아래 명령어는 버전에 따라 계속해서 달라지므로 복사-붙여넣기를 하기보단 TAB을 쳐가며 직접 찾아 사용하는 것을 권장한다.
## Namenode01
yum install -y /opt/bigtop/build/ambari/rpm/RPMS/noarch/ambari-server-2.7.5.0-1.el7.noarch.rpm
yum install -y /opt/bigtop/build/ambari/rpm/RPMS/noarch/ambari-agent-2.7.5.0-1.el7.noarch.rpm
yum install -y /opt/bigtop/build/bigtop-utils/rpm/RPMS/noarch/bigtop-utils-3.2.0-1.el7.noarch.rpm
yum install -y /opt/bigtop/build/bigtop-ambari-mpack/rpm/RPMS/noarch/bigtop-ambari-mpack-2.7.5.0-1.el7.noarch.rpm
## 나머지 노드
yum install -y /opt/bigtop/build/ambari/rpm/RPMS/noarch/ambari-agent-2.7.5.0-1.el7.noarch.rpm
여기까지 수행했다면 밑의 남은 포스팅은 오직 Namenode01에서만 수행한다.
이제 설치에 앞서 DB설정을 해주어야 한다.
bigtop을 이용한 설치 시 hive, ambari 이름의 데이터베이스가 필요하다.
이미 Namenode01에 Docker 기반의 Postgresql이 설치되어 있으므로, 해당 컨테이너에 진입해 사전에 생성한 hive 데이터베이스를 삭제하고 두 개의 데이터베이스를 생성한다.
docker exec -it postgres bash
su postgres
psql
drop database hive;
create database ambari;
create database hive;
\l
마지막 명령어까지 마쳤다면 다음과 같은 화면이 출력됨을 확인할 수 있다.

이제 컨테이너에서 나와 bigtop이 Postgresql과 연동될 수 있도록 JDBC Driver를 설치한다.
cd /opt
wget https://jdbc.postgresql.org/download/postgresql-42.5.0.jar
설치가 완료되었다면 ambari-server 세팅을 통해 DB를 설정한다.
ambari-server setup --jdbc-driver=/opt/postgresql-42.5.0.jar --jdbc-db=postgres
그리고 상세 설정을 시작한다.
ambari-server setup
아래 정보에서 다른 건 그냥 엔터만 쳐도 되지만, DB 정보 입력 시에는 정확하게 적어주도록 한다.


설정이 완료되었다면 DB에 테이블을 입력한다.
/var/lib/ambari-server/resources/Ambari-DDL-Postgres-CREATE.sql 파일 내 내용을 복사하여 ambari 데이터베이스에 붙여넣으면 된다.
docker exec -it postgres bash
su postgres
psql
\c ambari
## sql 붙여넣기
테이블 생성이 끝났다면 다음 명령어를 통해 mpack을 지정하고, ambari-server를 시작한다.
ambari-server install-mpack --mpack=/usr/lib/bigtop-ambari-mpack/bgtp-ambari-mpack-1.0.0.0-SNAPSHOT-bgtp-ambari-mpack.tar.gz --verbose
ambari-server start
암바리 UI기반 설치
이제 Namenode01:8080으로 접속하면 다음과 같은 화면이 출력됨을 확인할 수 있다.

별도의 설정 과정을 거치지 않았으므로 admin/admin 계정으로 로그인한다. 설치된 Hadoop을 관리할 때 해당 아이디와 비밀번호가 사용되니 유실되지 않도록 유의한다.
로그인이 완료되면 아래와 같은 화면이 떠오르는데, LAUNCH INSTALL WIZARD 버튼을 클릭해 다음 단계로 넘어간다.

원하는 CLUSTER NAME을 입력한다.

다음 단계에서는 URL을 알 수 없다며 에러가 발생하는데, 그냥 Skip Repository Base URL validation 체크박스를 체크하고 넘어가도 무방하다.
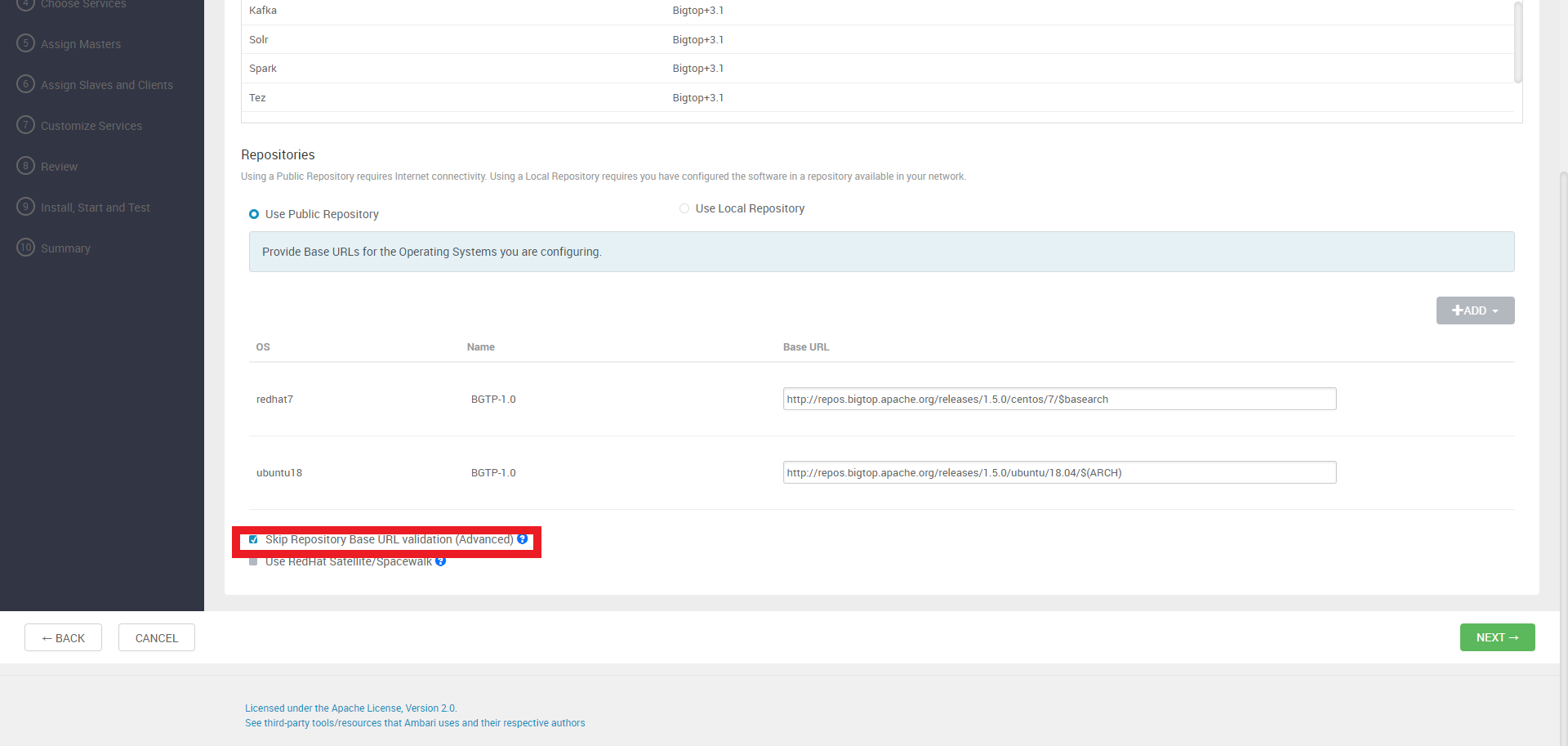
hostname들을 입력한다. 이 때 hostname은 한 줄에 하나씩 입력한다.
그리고 이전 포스팅과 마찬가지로 ssh-keygen을 수행하고 각 노드(자기자신을 포함)에 ssh-copy-id를 수행한다.
## 키 생성 시 입력하는 값들은 전부 엔터 (default)
ssh-keygen
ssh-copy-id root@Namenode01
ssh-copy-id root@Namenode02
ssh-copy-id root@Datanode01
ssh-copy-id root@Datanode02
그리고 /home/hadoop/.ssh 내에 id_rsa 파일의 내용을 Host Registration Information에 붙여넣는다.
마지막으로 User는 root으로 지정하고 녹색 버튼을 눌러 다음 단계로 넘어간다.
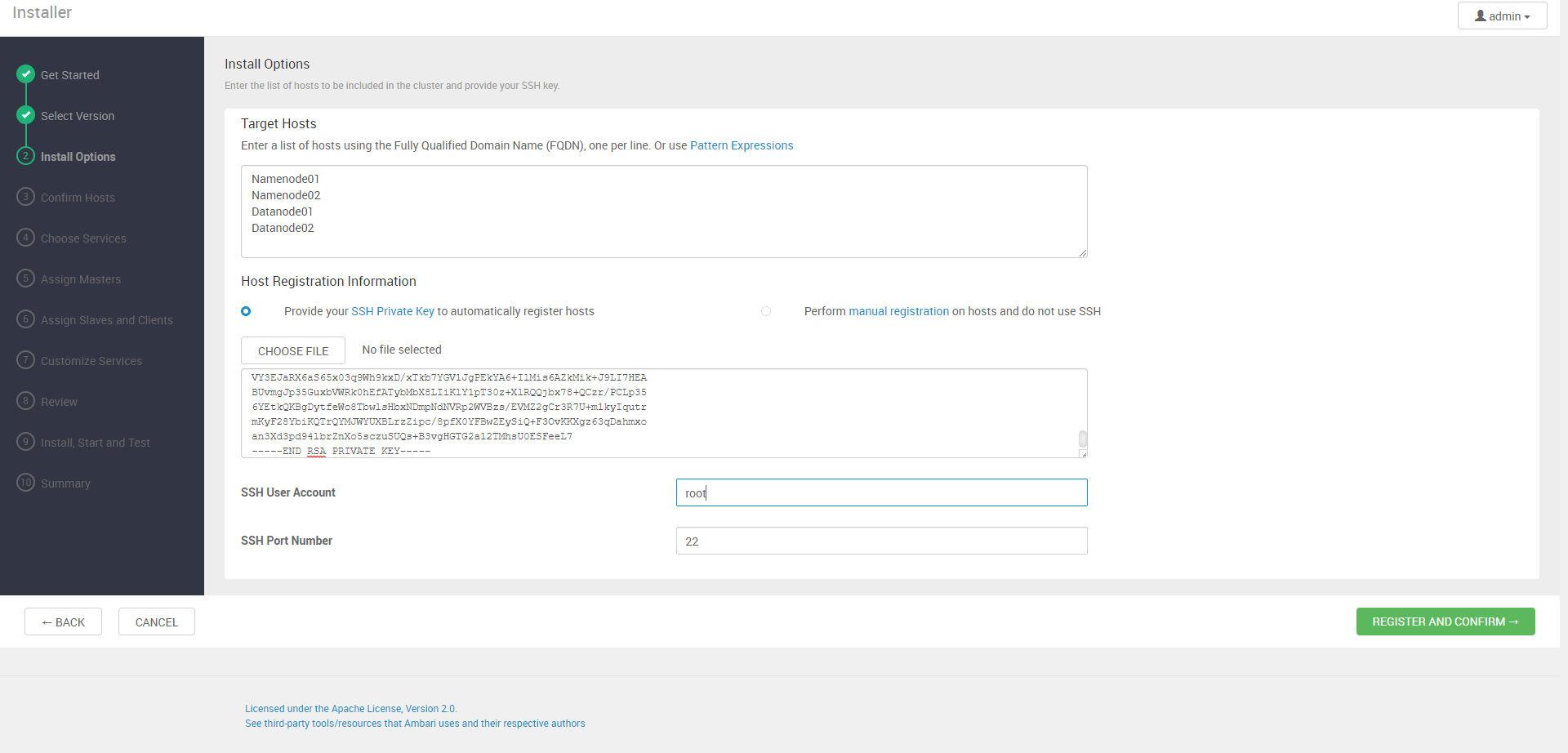
이 단계에서는 호스트들에 SUCCESS가 뜨면 성공한 것이니 넘어간다.

이 단계에서는 설치를 원하는 에코시스템들을 선택한다. 앞선 포스팅에서 언급한 에코시스템들을 체크하고 넘어간다.
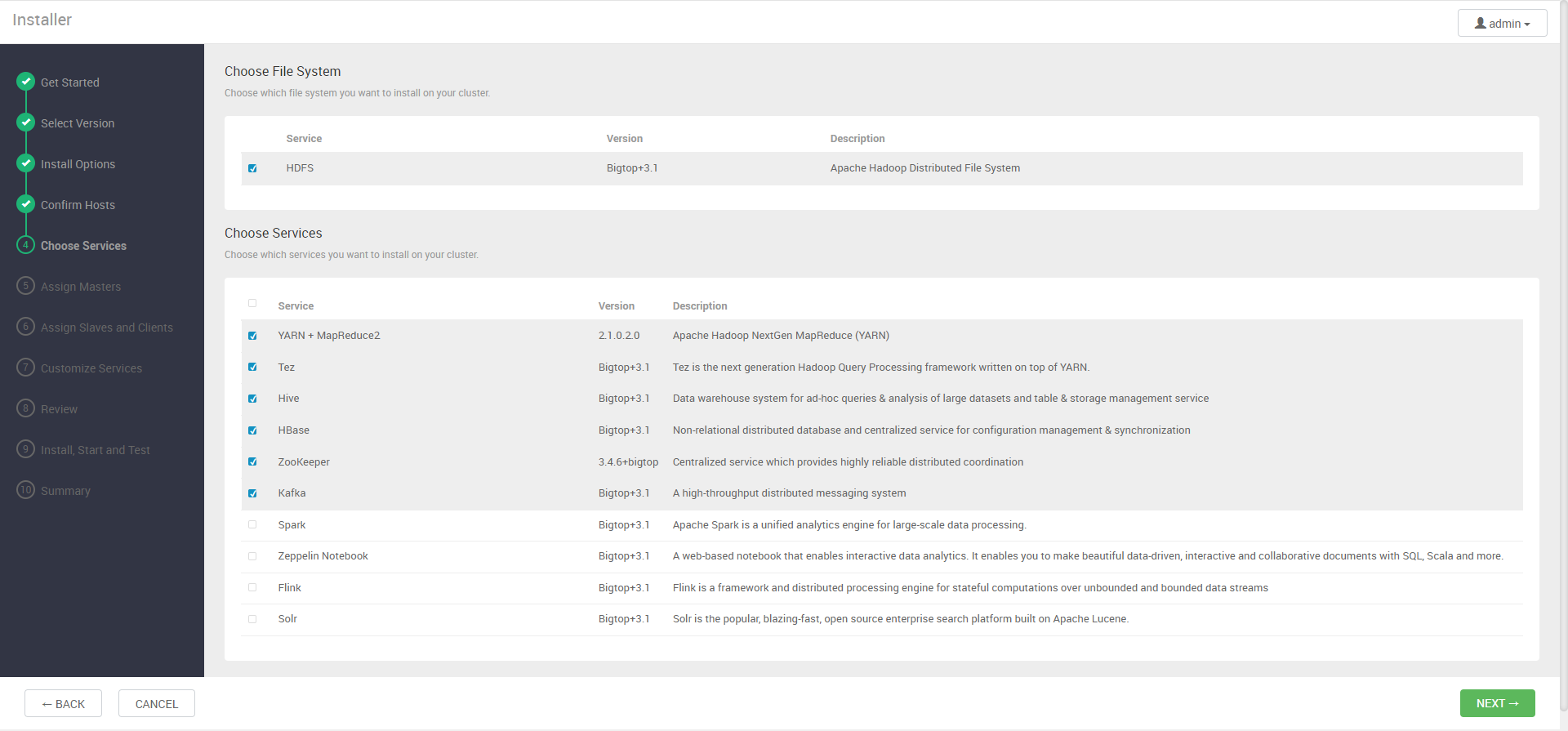
다음 두 단계에서는 각 패키지가 어느 노드에 설치될지 결정한다.

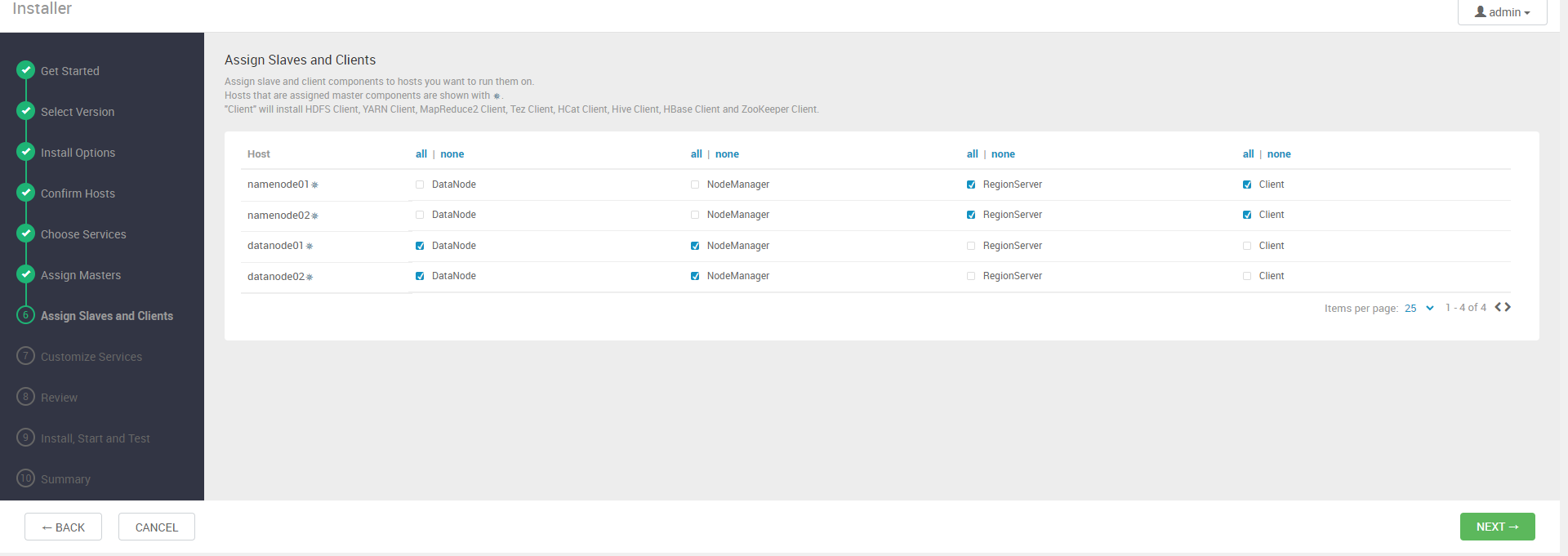
다음 단계에서는 DB와 각 에코시스템의 설정을 설정한다. DB를 제외하고는 디폴트로 진행한다.
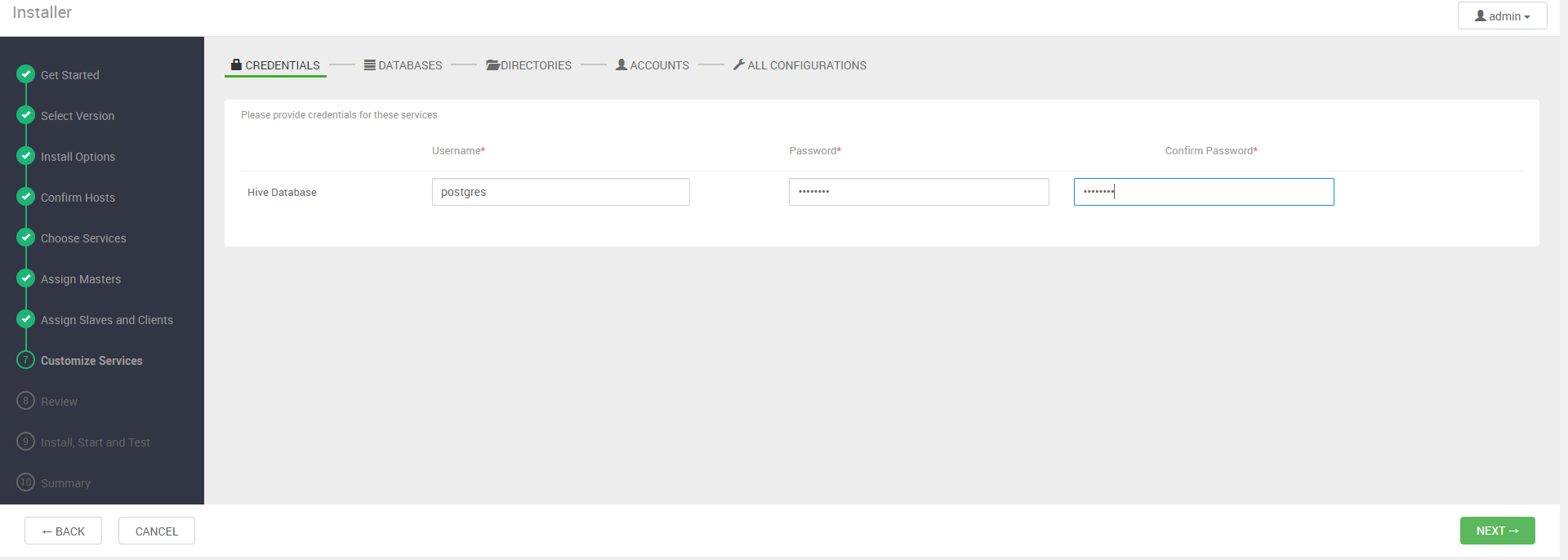
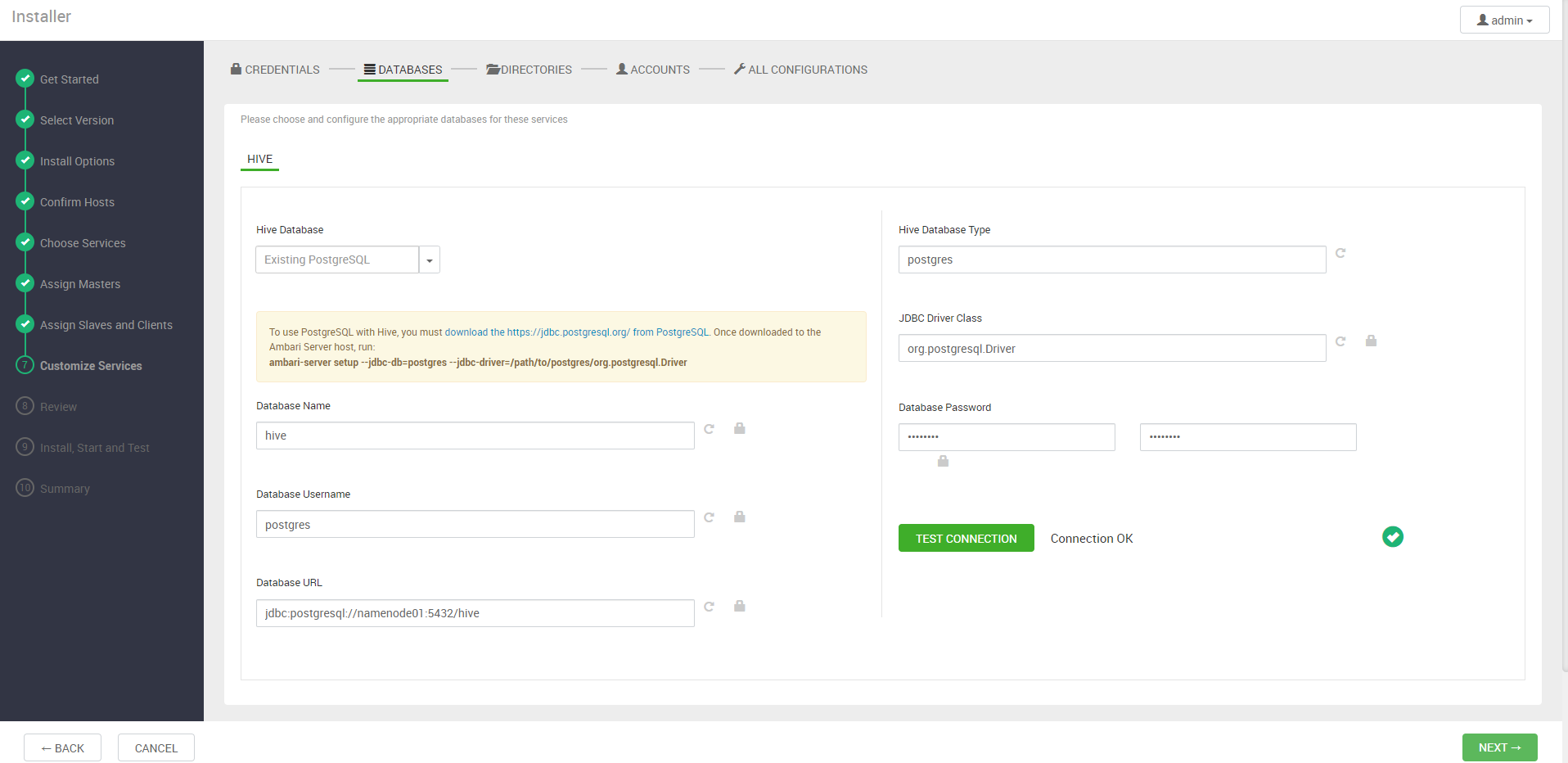
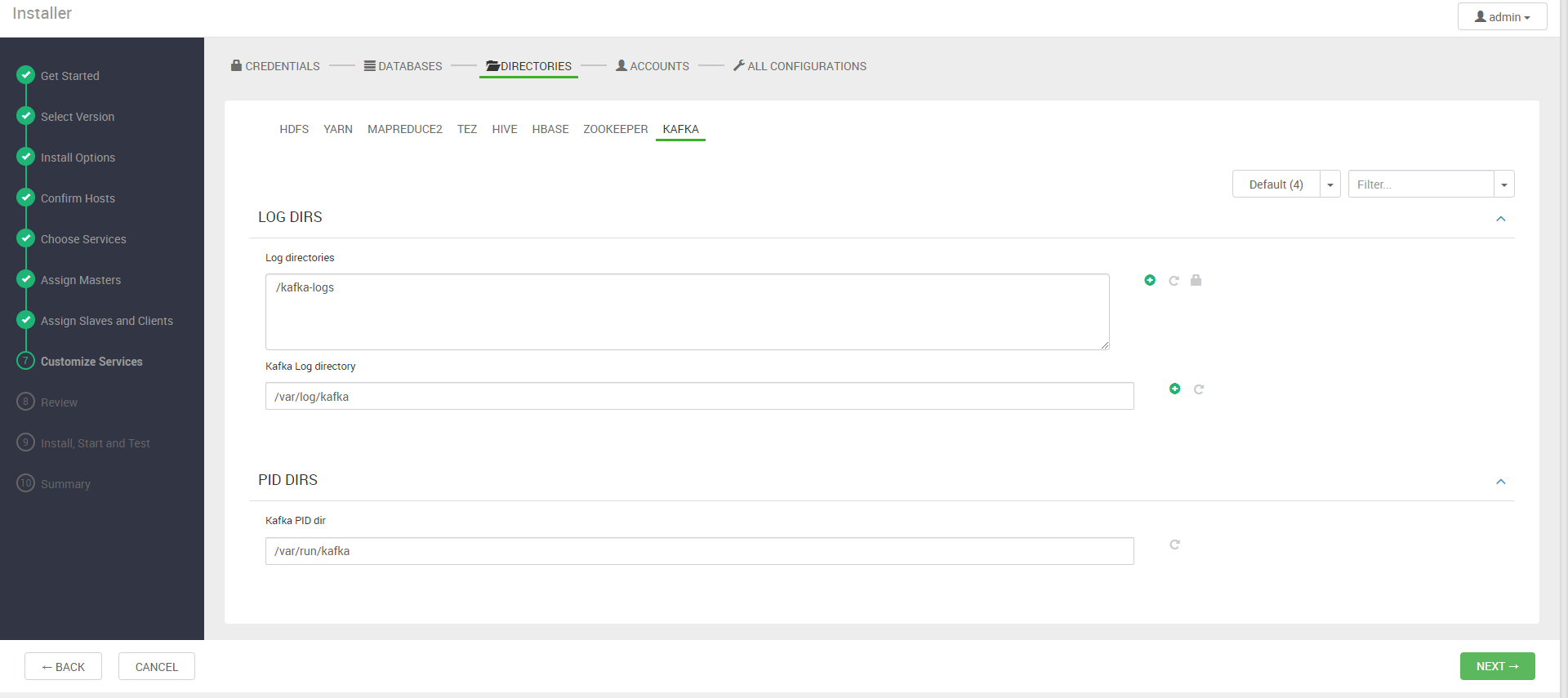
*Accounts에서 아무것도 안나오면 그냥 Next를 눌러도 된다.
아래의 hadoop.proxyuser.*에는 가능하면 *를 입력한다.

마지막으로 설정을 확인하고 설치를 시작한다.

잠시 기다려보면 설치가 완료되며, Hadoop이 정상적으로 설치되었음을 확인할 수 있다.

다시 Namenode01:8080으로 돌아가보면 이제 해당 페이지는 더 이상 설치 페이지로 작동하지 않고, Hadoop과 관련 에코시스템들을 모니터링 및 관리할 수 있는 페이지로 변한다.

- 이미 hadoop이 깔려있던 서버에 임의로 hadoop을 지우고 한 탓에 port가 겹치는 등의 문제로 YARN과 MapReduce, Hive가 정상적으로 실행되지 않았다. 아예 새로운 서버에서 설치 시 해결될 것으로 예상한다.
'IT 지식 > 빅데이터 & 분석' 카테고리의 다른 글
| JAVA-HIVE/HBASE 간 통신_Hive 통신 (0) | 2023.01.22 |
|---|---|
| JAVA-HIVE/HBASE 간 통신_Hadoop/HIVE/HBase 설치 (1) | 2023.01.21 |
| 멀티노드에 Hadoop 설치해보기 (0) | 2022.10.23 |
| [시계열 분석 모델] AR, MA, ARIMA (2) | 2021.10.12 |
| [빅데이터] 빅데이터 분석 단계 (0) | 2021.08.08 |



