Hadoop

하둡은 빅데이터의 처리를 위한 자바 기반의 오픈소스 프레임워크로,
야후의 더그 커팅이 '넛치' 라는 검색 엔진을 개발하는 과정에서 대용량의 비정형 데이터를 철이하기 위해 구글의 GFS와 MapReduce 관련 논문을 참고하여 개발한 기술이다.
기존에는 데이터 처리를 하나의 고사양 컴퓨터에서 수행했다.
하지만 하둡은 빅데이터의 처리를 위해 하나의 컴퓨터가 아닌, 여러 컴퓨터를 사용하는 방식을 채택했다.
상세하게 말하자면 여러 대의 컴퓨터를 클러스터화 시켜 병렬로 연결하고, 이를 토대로 동시 처리 속도를 높이는 기술을 채택했다고 볼 수 있다.
하둡의 장점으로는 시스템을 중단하지 않고도 장비 추가가 가능하다. 병렬적으로 컴퓨터들을 이어놓았으니 당연한 일이다. 그리고 이러한 특징으로 인해 일부 장비에 장애가 발성하더라도 전체 시스템에 큰 영향을 끼치지 않는다.
하지만 동시에 HDFS에 저장된 데이터를 변경할 수 없고, 실시간 데이터 처리에는 적합하지 못하며, 설정이 어렵다는 단점이 있다.
Hadoop Ecosystem
하둡 에코시스템이란 하둡을 기반으로 제작된 서브 프로젝트들의 모음이다.
데이터 분석, 데이터 마이닝, 메타데이터 관리, 분산 데이터 처리 등 다양한 주제로 제작되어 활용되며, 현 포스팅에서는 HDFS, MapReduce, Yarn 등 기본적인 에코시스템을 포함하여 Hive, Flume, Tez, HBase, Hue등의 에코시스템이 포함된 하둡을 구성해볼까 한다.
목표 Hadoop 구성
두 개의 네임노드와 두 개의 데이터노드로 구성된 Hadoop을 설치하고자 한다.
목표하는 시스템 구성은 아래와 같이 잡았다.
설치
0. 사전 설정
위와 같이 네 개의 노드를 구성하기 위해 Oracle VM Virtualbox를 통해 네 개의 서버를 생성하였다.
로컬에서 여러 서버를 만들기에 사양은 다음과 같이 간단하게 맞추어 놓았다.
- OS: CentOS 7.9
- CORE: 2 Core
- RAM: 2Gib
- ROM: 32Gib
서버를 만드는 방법은 다음 포스팅을 참고한다.
서버 설치가 완료되었다면 각 서버를 켜고 하둡 설치를 시작하자.
Hadoop 설치에 앞서 몇 가지 사전에 설정해야할 사항들이 있다.
가장 먼저 해줘야 할 일은 yum을 최신화 하는 일이다.
모든 서버에 다음 명령어를 실행한다.
yum -y update
yum 최신화가 완료되었다면 다음으로 방화벽을 열어준다.
지금은 연습삼아 설치해보는 단계이기 때문에 개별 포트를 열어주지는 않고, 방화벽을 완전히 꺼버리는 방식으로 대체한다.
모든 서버에 다음 명령어를 실행한다.
systemctl disable firewalld
systemctl stop firewalld
다음으로 해야할 일은 JAVA 설치이다.
모든 서버에 다음 명령어를 실행하여 JAVA 1.8 버전을 설치하고, JAVA_HOME을 설정한다.
yum install -y java-1.8.0-openjdk-devel.x86_64
yum install -y vim
## /bin/java 앞까지 복사한 후 /etc/profile에 추가
readlink -f `which java`
vim /etc/profile
## readlink로 나온 디렉터리 붙여넣기
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.345.b01-1.el7_9.x86_64/jre/
export PATH=$PATH:$JAVA_HOME/bin
## :wq 로 vim 제거
source /etc/profile
이후 java -version 명령어를 통해 자바 1.8 버전이 정상적으로 설치되었는지 확인한다.

자바 설치가 완료되었다면 다음은 도커 차례이다.
하둡의 구성 요소 중에는 Zookeeper와, 각종 에코시스템들이 사용할 RDB (MariaDB, PostgreSQL 등)이 필요하다.
해당 프로그램들은 메뉴얼하게 설치해도 되지만, 도커를 이용하면 간편하게 설치가 가능하므로 굳이 메뉴얼하게 설치하지 않고 도커를 이용해 설치한다.
Namenode01, Datanode01, Datanode02 서버에 다음 명령어를 입력하여 Docker를 설치하고 실행한다.
yum install -y yum-utils device-mapper-persistent-data lvm2
yum-config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo
yum install -y docker-ce
systemctl enable docker
systemctl start docker
그 후 Datanode01, Datanode02 서버에 zookeeper 컨테이너를 설치해본다.
docker network create app-tier --driver bridge
docker run \
--restart unless-stopped \
--name zookeeper \
--network app-tier \
-d \
-p 2181:2181 \
-e ALLOW_ANONYMOUS_LOGIN=yes \
bitnami/zookeeper:latest
그리고 Namenode01 서버에는 postgresql을 설치한다.
docker run \
-p 5432:5432 \
--restart always \
--name postgres \
-e POSTGRES_PASSWORD=password \
-e TZ=Asia/Seoul \
-d \
postgis/postgis
마지막으로 각 노드들이 서로 통신할 때 비밀번호를 입력하지 않고도 ssh에 진입할 수 있도록 설정한다.
먼저 모든 서버의 /etc/hosts 파일을 열어 각 서버의 정보를 저장한다.
(자기 자신의 서버도 빠짐없이 입력한다.)
192.168.*.* Namenode01
192.168.*.* Namenode02
192.168.*.* Datanode01
192.168.*.* Datanode02
그리고 각 서버에 hadoop 계정을 생성하고 각 서버간 통신이 가능하도록 설정한다.
adduser hadoop
## 비밀번호 설정
passwd hadoop
su hadoop
## 키 생성 시 입력하는 값들은 전부 엔터 (default)
ssh-keygen
ssh-copy-id hadoop@Namenode01
ssh-copy-id hadoop@Namenode02
ssh-copy-id hadoop@Datanode01
ssh-copy-id hadoop@Datanode02
이제 아무 서버에서나 또 아무 서버로 ssh를 시도하면 패스워드 없이 ssh 로그인이 정상적으로 수행됨을 확인할 수 있다.
여기까지 했으면 Hadoop을 설치할 수 있는 기본 설정은 모두 끝이났다.
1. Hadoop 설치
아래 서술되는 과정 중 설치 및 설정 과정은 모든 서버에 적용해준다.
Hadoop과 에코시스템들은 /opt 폴더에 모두 저장을 할 생각이다.
그러므로 /opt 폴더를 먼저 만들어준다. 아래 작업은 root 계정을 이용한다.
mkdir /opt
mkdir /opt/hadoop
그 후에는 tmp에 들어가 다음 명령어를 실행하여 hadoop을 다운로드 받아 /opt/hadoop 폴더에 압축을 해제한다.
cd /tmp
yum -y install wget
wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
tar -xzf hadoop-3.3.4.tar.gz -C /opt/hadoop --strip-components 1
chown -R hadoop:hadoop /opt/hadoop
여기까지 했다면 hadoop이 설치되었으니, hadoop을 설치 위치를 지정하기 위해 HADOOP_HOME을 설정한다.
vim /etc/profile
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source /etc/profile
이후 hadoop version 명령어를 입력하면 아래와 같이 하둡이 정상 설치되었음을 확인할 수 있다.
물론 여기서 끝이 아니고, 시작 전에 여러 설정 파일들을 수정해주어야 하둡이 정상적으로 작동할 수 있다.
이 밑에서부터의 작업은 root가 아닌 hadoop 계정으로 수행하도록 한다.
su hadoop
수정해야할 주요 파일은 core-site.xml, httpfs-env.sh, hdfs-site.xml, yarn-default.xml, mapred-site.xml이며, 다음과 같이 설정한다.
core-site.xml (참고: https://hadoop.apache.org/docs/r3.3.4/hadoop-project-dist/hadoop-common/core-default.xml )
vim $HADOOP_HOME/etc/hadoop/core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://Namenode01:9000</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>Datanode01:2181,Datanode02:2181</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>Namenode01:8021</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
https-env.sh
vim $HADOOP_HOME/etc/hadoop/httpfs-env.sh
export HTTPFS_HTTP_PORT=9870
hdfs-site.xml (참고: https://hadoop.apache.org/docs/r3.3.4/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml )
vim $HADOOP_HOME/etc/hadoop/hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.rpc-bind-host</name>
<value>0.0.0.0</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/tmp/hadoop/dfs/journalnode</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>Namenode</value>
</property>
<property>
<name>dfs.ha.namenodes.Namenode</name>
<value>Namenode01,Namenode02</value>
</property>
<property>
<name>dfs.namenode.rpc-address.Namenode.Namenode01</name>
<value>Namenode01:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.Namenode.Namenode02</name>
<value>Namenode02:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.Namenode.Namenode01</name>
<value>Namenode01:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.Namenode.Namenode02</name>
<value>Namenode02:9870</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://Namenode01:8485;Namenode02:8485/Namenode</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.Namenode</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(/bin/true)</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!--property>
<name>dfs.namenode.http-address</name>
<value>Namenode01:50070</value>
</property-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Namenode01:9869</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/hadoop_data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/hadoop_data/hdfs/datanode</value>
</property>
<property>
<name>dfs.namenode.checkpoint.dir</name>
<value>file:/home/hadoop/hadoop_data/hdfs/namesecondary</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
yarn-default.xml (참고 : https://hadoop.apache.org/docs/r3.3.4/hadoop-yarn/hadoop-yarn-common/yarn-default.xml )
vim $HADOOP_HOME/etc/hadoop/yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>Namenode01:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>Namenode01:8031</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>Namenode01:8032</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>Namenode01:8033</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Namenode01</value>
<!-- Namenode02 서버에서는 Namenode02 -->
</property>
<property>
<name>yarn.web-proxy.address</name>
<value>Namenode01:8880</value>
<!-- Namenode02 서버에서는 Namenode02 -->
</property>
mapred-site.xml (참고 : https://hadoop.apache.org/docs/r3.3.4/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml )
vim $HADOOP_HOME/etc/hadoop/mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobtracker.hosts.exclude.filename</name>
<value>$HADOOP_HOME/etc/hadoop/exclude</value>
</property>
<property>
<name>mapreduce.jobtracker.hosts.filename</name>
<value>$HADOOP_HOME/etc/hadoop/include</value>
</property>
masters, slaves 파일 생성
vim $HADOOP_HOME/etc/hadoop/masters
Namenode01
Namenode02
vim $HADOOP_HOME/etc/hadoop/slaves
Datanode01
Datanode02
hadoop-env.sh
vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.345.b01-1.el7_9.x86_64/jre/
위의 작업을 마쳤으면 이제 각 노드별로 실행되어야 할 서비스들을 실행한다.
아래 명령어를 순서대로 실행한다.
# Namenode01
hdfs zkfc -formatZK
hdfs --daemon start journalnode
# Namenode02
hdfs --daemon start journalnode
# Namenode01
hdfs namenode -format
hdfs --daemon start namenode
hdfs --daemon start zkfc
# Namenode02
hdfs namenode -bootstrapStandby
hdfs --daemon start namenode
hdfs --daemon start zkfc
# Namenode01, Namenode02
yarn --daemon start resourcemanager
yarn --daemon start proxyserver
hdfs --daemon start httpfs
# Namenode01
mapred --daemon start historyserver
# Datanode01, Datanode02
hdfs --daemon start datanode
yarn --daemon start nodemanager
만약 위 과정 중 에러가 발생했거나 켜지지 않은 프로그램이 존재한다면 $HADOOP_HOME/sbin/stop-all.sh 파일을 실행하여 모든 프로그램을 종료한 후 /tmp 폴더와 /home/hadoop 폴더 내 모든 데이터를 지우고 처음부터 재실행할 수 있다.
모든 실행이 끝났다면 jps 명령어로 각 시스템들이 정상적으로 켜졌는지 확인한다.
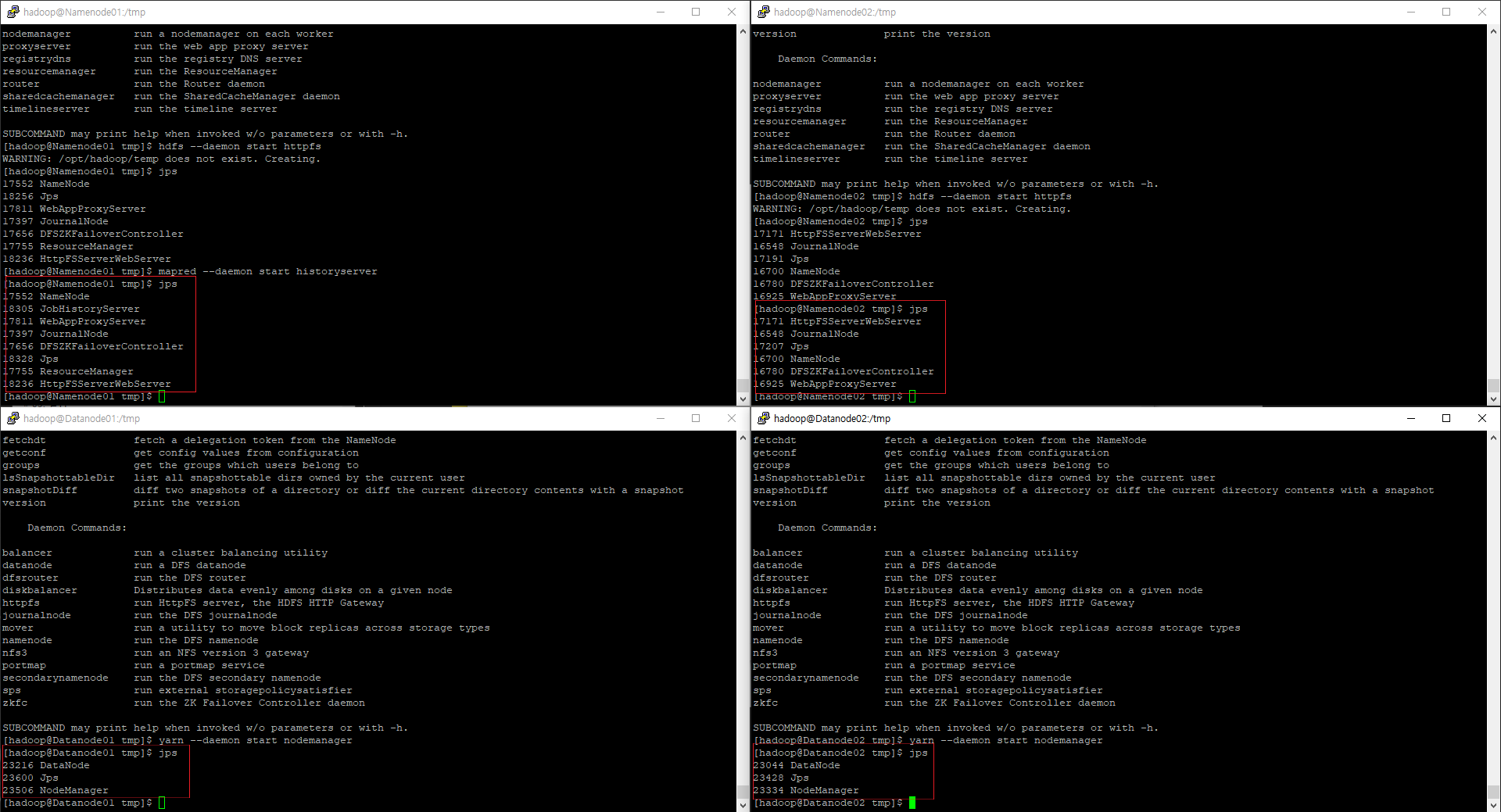
2. ATS & TEZ2
이제 Namenode01에 Tez를, Namenode02에 ATS를 설치해보자.
먼저 Namenode01에 Tez와, Tez를 보여주기 위한 apache-tomcat을 설치한다.
## 여기부터는 root 혹은 sudo 옵션으로 실행
mkdir /opt/tez
cd /opt/tez
wget https://repo1.maven.org/maven2/org/apache/tez/tez-ui/0.9.2/tez-ui-0.9.2.war
wget http://archive.apache.org/dist/tomcat/tomcat-8/v8.5.9/bin/apache-tomcat-8.5.9.tar.gz
tar -xvf apache-tomcat-8.5.9.tar.gz
ln -s /opt/tez/apache-tomcat-8.5.9 /usr/local/tomcat8
vim /etc/profile
export CATALINA_HOME=/usr/local/tomcat8
export CLASSPATH=$JAVA_HOME/lib:$JAVA_HOME/lib/tools.jar:$CATALINA_HOME/lib-jsp-api.jar:$CATALINA_HOME/lib/servlet-api.jar
source /etc/profile
## Namenode02에 설치될 History Server와 연결
yum install -y unzip
mkdir /usr/local/tomcat8/webapps/tez-ui
cp /opt/tez/tez-ui-0.9.2.war /usr/local/tomcat8/webapps/tez-ui/tez-ui.war
cd /usr/local/tomcat8/webapps/tez-ui
unzip tez-ui.war
rm -rf tez-ui.war
cd config
vim configs.env
## 다음 부분들 작성
timeline: "http://Namenode02:8188",
rm: "http://Namenode02:8088",
rmProxy: "http://Namenode02:8088",
위의 설치 과정 중 언급되었듯, Namenode02의 ATS와 연결될 것이기 때문에 톰캣 시작에 앞서 Namenode02에 ATS를 설치한다.
ATS는 기본적으로 hadoop yarn 내에 있기 때문에 별도로 wget등을 통해 다운받을 필요는 없고, 다음과 같은 항목들을 수정해주면 된다.
vim $HADOOP_HOME/etc/hadoop/yarn-site.xml
<property>
<description>Indicate to clients whether Timeline service is enabled or not.
If enabled, the TimelineClient library used by end-users will post entities
and events to the Timeline server.</description>
<name>yarn.timeline-service.enabled</name>
<value>true</value>
</property>
<property>
<description>The hostname of the Timeline service web application.</description>
<name>yarn.timeline-service.hostname</name>
<value>Namenode02</value>
</property>
<property>
<description>Enables cross-origin support (CORS) for web services where
cross-origin web response headers are needed. For example, javascript making
a web services request to the timeline server.</description>
<name>yarn.timeline-service.http-cross-origin.enabled</name>
<value>true</value>
</property>
<property>
<description>Publish YARN information to Timeline Server</description>
<name> yarn.resourcemanager.system-metrics-publisher.enabled</name>
<value>true</value>
</property>
수정이 끝났으면 다음 명령어를 통해 ATS를 실행한다.
yarn --daemon start timelineserver
그 후 jps를 통해 정상실행 여부를 확인하고,

다시 Namenode01로 돌아가 톰캣을 실행한다.
cd /usr/local/tomcat8/bin
./startup.sh
이제 크롬 등을 통해 Namenode01:8080/tez-ui 로 들어가보면 tez-ui가 정상적으로 출력됨을 확인할 수 있다.
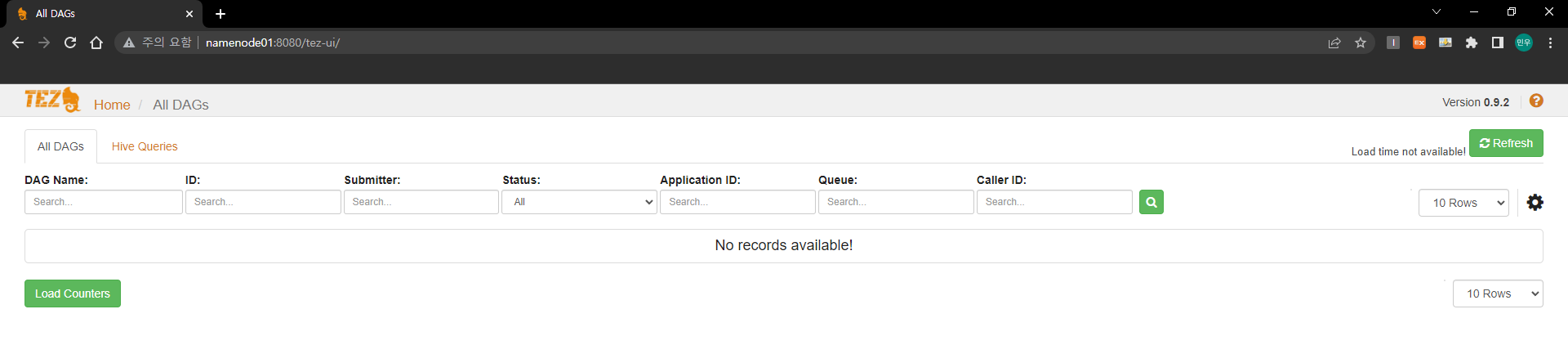
- 참고로 윈도우의 hosts 파일에도 Namenode01과 Namenode02의 주소가 올바르게 들어가 있어야 위와같이 출력된다. 만약 hosts 파일을 바꾸고 싶지 않다면 tez-ui 설정 시 Namenode02의 호스트명을 IP주소로 변경하면 된다.
3. Hive 설치
다음으로 설치해야할 에코시스템은 Hive이다.
Hive는 Namenode01과 Namenode02에 설치하도록 한다.
Hive는 메타데이터를 RDB에 저장하는데, 해당 포스팅에서는 사전 준비 사항에서 이에 사용하기 위한 Postgresql을 사전에 설치해놓았다.
그러면 Namenode01의 Postgresql에 접속하여 Hive 설치를 위한 세팅을 시작한다.
먼저 Postgresql에 접속한다.
docker exec -it postgres bash
su postgres
psql
Postgresql에서 해야할 일은 단순하게 Hive 데이터베이스를 만들어주는 것이다. 원래는 Hive 전용 사용자도 생성해주어야 하나, 이 포스팅에서는 root로 대체한다.
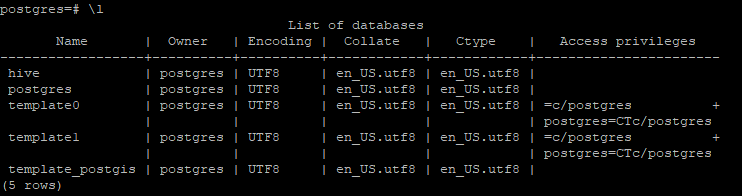
create database hive;
이제 \l 명령어를 쳐보면 hive 데이터베이스가 생성되어 있음을 확인할 수 있다.
이제 원래 서버로 돌아가 hadoop 계정으로 전환한 후 Hive 설치를 재개한다.
앞서 언급했듯, Hive는 Namenode01과 Namenode02에 설치되기에 두 노드에서 동일하게 작업한다.
su hadoop
cd /tmp
wget https://dlcdn.apache.org/hive/hive-3.1.3/apache-hive-3.1.3-bin.tar.gz
mkdir /opt/hive
tar -xzf apache-hive-3.1.3-bin.tar.gz -C /opt/hive --strip-components 1
여기까지 했으면 Hive 설치는 끝이났으니, 설정 작업을 수행한다.
설정작업은 크게 할 것은 없고, DB 정보 정도만 수정해주면 된다.
cd /opt/hive/conf
cp hive-default.xml.template hive-site.xml
vim hive-site.xml
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>org.postgresql.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>postgres</value>
<description>Username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>password</value>
<description>password to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:postgresql://Namenode01:5432/hive</value>
<description> JDBC connect string for a JDBC metastore. To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL. For example, jdbc:postgresql://myhost/db?ssl=true for postgres database. </description>
</property>
추가로 ${}로 인해 에러가 발생할 수 있으니, ${}의 내용을 추가한다.
<property>
<name>system:java.io.tmpdir</name>
<value>/home/hadoop/hive/tmp</value>
</property>
<property>
<name>system:user.name</name>
<value>hadoop</value>
</property>
또한 이대로 실행하면 Illegal character entity: expansion character 라는 이름의 에러가 발생할 수 있는데, hive-site.xml의 3225번째 줄에 있는  로 인해 발생하는 에러이다. 이 부분을 제거해준다.

이제 /etc/profile에 HIVE_HOME을 지정해주고, PostgreSQL 드라이버를 설치해주면 설치는 마무리된다.
su root
vim /etc/profile
export HIVE_HOME=/opt/hive
export HIVE_CONF_DIR=/opt/hive/conf
export PATH=$PATH:$HIVE_HOME/bin
source /etc/profile
su hadoop
cd /opt/hive/lib
wget https://jdbc.postgresql.org/download/postgresql-42.5.0.jar
설치 후에는 DB 초기화를 수행해준다.
초기화는 Namenode01에서만 진행한다.
cd /opt/hive/bin
./schematool -dbType postgres -initSchema
DB 초기화가 완료되었다면 hiveserver2를 실행한다.
서버는 Namenode01, Namenode02 둘 다에서 실행하도록 한다.
cd /opt/hive/bin
nohup ./hive --service hiveserver2 --hiveconf hive.server2.thrift.port=10000 --hiveconf hive.root.logger=INFO,console &
그리고 jps와 ps 명령어를 통해 hiveserve2의 정상 작동 여부를 확인한다.


4. Flume
다음은 Flume이다. Flume은 Namenode01에서만 설치하도록 한다.
cd /tmp
wget https://dlcdn.apache.org/flume/1.10.1/apache-flume-1.10.1-bin.tar.gz
mkdir /opt/flume
tar -xzf apache-flume-1.10.1-bin.tar.gz -C /opt/flume --strip-components 1
설치가 완료되었다면 flume은 FLUME_HOME 정도만 설정하고 설치를 마친다.
su root
vim /etc/profile
export FLUME_HOME=/opt/flume
export PATH=$PATH:$FLUME_HOME/bin
export CLASSPATH=$CLASSPATH:$FLUME_HOME/lib/*.jar
source /etc/profile
su hadoop
5. HBase
다음은 Hadoop의 NoSQL인 HBase이다.
HBase는 Hive와 마찬가지로 Namenode01, Namenode02에 설치하도록 한다.
cd /tmp
wget https://apache.mirror.gtcomm.net/hbase/2.5.0/hbase-2.5.0-bin.tar.gz
mkdir /opt/hbase
tar -xzf hbase-2.5.0-bin.tar.gz -C /opt/hbase --strip-components 1
설치가 완료되었다면 이제 HBASE_HOME을 지정한다.
su root
vim /etc/profile
export HBASE_HOME=/opt/hbase
export PATH=$PATH:$HBASE_HOME/bin
source /etc/profile
su hadoop
HBase는 별도로 설정을 해주어야할 것은 없고, 곧바로 start-hbase.sh 스크립트 파일을 통해 켜주기만 한다.
cd $HBASE_HOME/bin/
./start-hbase.sh
이제 jps로 hbase가 정상적으로 켜졌는지 확인한다.
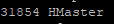
6. Hue
마지막으로 Hadoop내 데이터에 UI기반으로 접근할 수 있는 Hue를 설치하고자 한다.
마찬가지로 Namenode01, Namenode02에 동일하게 설치하도록 한다.
Hue는 파이썬을 기반으로 동작하므로 python과 관련 패키지들의 설치가 필요하다.
su root
rpm -Uvh --replacepkgs https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpm
yum install -y https://dl.fedoraproject.org/pub/epel/epel-release-latest-7.noarch.rpm
yum -y install http://mirror.centos.org/centos/7/os/x86_64/Packages/libedit-devel-3.0-12.20121213cvs.el7.x86_64.rpm
yum groupinstall 'development tools'
## 복사-붙여넣기 시 위에까지만 하고 여기부터는 따로
yum install -y python-devel
yum install -y python-pip
yum install -y python-psycopg2.x86_64
yum install -y rsync
yum install -y ant asciidoc cyrus-sasl-devel cyrus-sasl-gssapi cyrus-sasl-plain gcc gcc-c++ krb5-devel libffi-devel libxml2-devel libxslt-devel make mysql mysql-devel openldap-devel python-devel sqlite-devel gmp-devel
yum install -y centos-release-scl-rh
yum install -y postgresql11-devel.x86_64
- 사실 위의 게 전부 필요하진 않은데, 뭐가 필수고 뭐가 선택인지 잘 모르겠어서 전부 설치해두었다.
필요 패키지 설치가 끝났다면 이제 wget으로 Hue를 설치한다.
su hadoop
cd /tmp
wget https://cdn.gethue.com/downloads/hue-4.0.1.tgz
mkdir /opt/hue
tar -xzf hue-4.0.1.tgz
cd /tmp/hue-4.0.0
다음으로 Namenode01에 설치된 Postgres에 Hue가 사용할 Database를 생성한다.
docker exec -it postgres bash
su postgres
psql
create database hue;
이제 Hue 실행에 앞서 hue 사용자를 만들고, DB에 연동될 수 있도록 설정을 수행한다.
vim /tmp/hue-4.0.0/desktop/conf/hue.ini
server_user=hadoop
server_group=hadoop
default_user=hadoop
default_hdfs_superuser=hadoop
resourcemanager_api_url=http://Namenode02:8088
[[database]]
host=Namenode01
port=5432
engine=postgresql_psycopg2
user=postgres
password=password
name=hue
전부 완료되었다면 Hue설치를 시작한다.
cd /tmp/hue-4.0.0
export PREFIX=/opt
make install
만약 위 과정을 그대로 따라했다면 발생하지 않을 에러인데, 전부 따라하지 않고 기존 PostgreSQL DB를 사용했다면 아래 에러가 발생할 수 있다.
SCRAM authentication requires libpq version 10 or above
이는 PostgreSQL이 10 버전 밑이라 발생하는 문제이니, 10버전 이상으로 재설치를 하거나 아니면 그냥 아예 DB 관련 세팅을 빼서 자체 DB를 구성하도록 하면 된다.
조금 시간이 걸리고 hue 설치가 완료되면 아래 명령어를 수행한다.
cd /opt/hue/build/env/bin/
./supervisor -d
./hue syncdb --noinput
./hue migrate
위 작업이 완료되었다면 Namenode02에서도 아래 명령어를 통해 hue를 실행한다.
cd /opt/hue/build/env/bin/
./supervisor -d
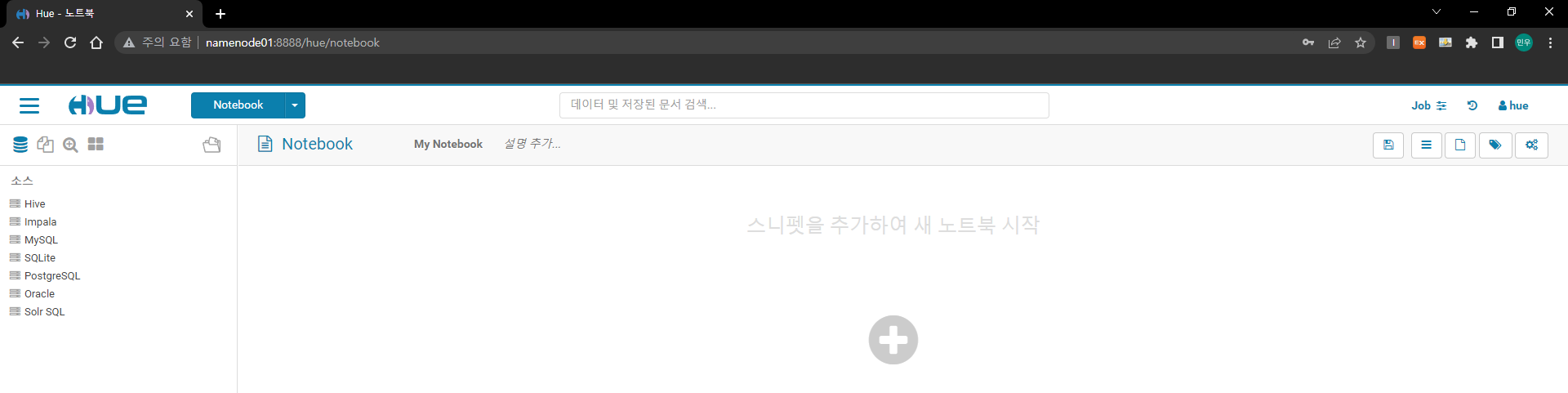
이제 Namenode01:8888에 접속하여 hue가 정상적으로 동작하는지 확인한다.
계정은 아까 만든 hue 계정을 사용한다.
Failed to open new session: java.lang.RuntimeException: org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.authorize.AuthorizationException): User: root is not allowed to impersonate hue
에러 발생 시 hive-site.xml에 hive.server2.enable.doAS를 false로 바꾸고 hiveserver2 재실행
jobs 페이지에서
'ascii' codec can't encode characters in position 7-8: ordinal not in range(128)
에러 발생 시 /opt/hue/build/env/lib/python2.7/site.py 파일 수정 아래 빨간 항목 (원래는 ascii)을 utf-8로 저장하고 재실행하면 됨.
def setencoding():
"""Set the string encoding used by the Unicode implementation. The
default is 'ascii', but if you're willing to experiment, you can
change this."""
encoding = "utf-8" # Default value set by _PyUnicode_Init()
'IT 지식 > 빅데이터 & 분석' 카테고리의 다른 글
| JAVA-HIVE/HBASE 간 통신_Hadoop/HIVE/HBase 설치 (1) | 2023.01.21 |
|---|---|
| Apache Bigtop을 이용한 Hadoop 설치 (0) | 2022.10.24 |
| [시계열 분석 모델] AR, MA, ARIMA (2) | 2021.10.12 |
| [빅데이터] 빅데이터 분석 단계 (0) | 2021.08.08 |
| [빅데이터] Spark & Zeppelin (0) | 2021.07.30 |



