728x90
반응형
출처 : https://book.naver.com/bookdb/book_detail.nhn?bid=21488029
공개적 빅데이터분석기사 실기
본 도서는 한국데이터산업진흥원에서 실시하는 빅데이터분석기사 국가기술자격 실기시험 대비 도서입니다.본 교재는 PYTHON을 활용하여 쉽고 빠른 자격증 취득으로 이어질 수 있도록 도움을 줄
book.naver.com
*해당 글은 학습을 목적으로 위의 도서 내용 중 일부 내용만을 요약하여 작성한 포스팅입니다.
상세 내용 및 전체 내용 확인을 원하신다면 도서 구매를 추천드립니다.
- 먼저 분석 데이터를 검토한다.
import pandas as pd
data = pd.read_csv('/house_price.csv', encoding='utf-8')
data.head()
- 그 후 shape 함수를 통해 행과 열의 갯수를 검토한다.
data.shape
- 다음으로 모든 변수 별 기술 통계를 확인하기 위해 describe 함수를 사용한다.
data.describe()
- 평균과 중위값의 일치정도와 min/max 값을 살펴보며 이상치를 확인한다.
- 다음으로 결측치를 제거하고 시각화하여 머신러닝 수행에 문제가 없을지 살핀다.
data = data.dropna()
%matplotlib inline
data.hist(bins=50, figsize=(20, 15))
- 문제가 없으므로 x, y를 분리한 후 학습, 테스트 데이터 셋으로 분할한다.
- 회귀의 경우 train_test_split에 stratify 파라미터를 사용할 수 없기에 수작업으로 평균이 너무 다르지 않은지 확인한다.
x = data[data.columns[:5]]
y = data[data.columns[5]]
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=42)
print(y_train.mean())
print(y_test.mean())
- 평균에 큰 차이가 없으므로 MinMaxScaler 적용 후 선형회귀를 수행한다.
from sklearn.preprocessing import MinMaxScaler
scaler_minmax = MinMaxScaler()
scaler_minmax.fit(x_train)
x_train = scaler_minmax.transform(x_train)
x_test = scaler_minmax.transform(x_test)
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(x_train, y_train)
pred_train = model.predict(x_train)
print('TRAIN :', model.score(x_train, y_train))
pred_test = model.predict(x_test)
print('TEST :', model.score(x_test, y_test))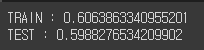
- 회귀모델의 주요 모델평가지표로는 RMSE (Root Mean Squared Error)가 있다. 설명력이 맞는 정도라면 RMSE는 틀린 정도로 오차를 판단한다.
- 그 외에도 MAE, MSE, MAPE, MPE 등이 사용 가능하며, 각 지표는 다음과 같이 구현할 수 있다.
#RMSE
import numpy as np
from sklearn.metrics import mean_squared_error
MSE = mean_squared_error(y_test, pred_test)
np.sqrt(MSE) # sqrt 안하면 mse
#MAE
from sklearn.metrics import mean_absolute_error
mean_absolute_error(y_test, pred_test)
#MAPE
def MAPE(y_test, pred_test) :
return np.mean(np.abs((y_test - pred_test) / y_test)) * 100
MAPE(y_test, pred_test)
#MPE
def MPE(y_test, pred_test) :
return np.mean((y_test - pred_test) / y_test) * 100
MPE(y_test, pred_test)
728x90
반응형
'자격증 > 빅데이터 분석기사 (실기)' 카테고리의 다른 글
| 04. 머신러닝 핵심 알고리즘 (1) (0) | 2022.06.05 |
|---|---|
| 03_03. 머신러닝 프로세스 (0) | 2022.06.04 |
| 03_01. 분류 (0) | 2022.05.30 |
| 03_머신러닝 프로세스 (0) | 2022.05.30 |
| 02_01. 데이터 정제 실전 과제 (0) | 2022.05.30 |



