Object Detection
-사진 자체가 아닌 사진 속의 특정 객체의 위치와 분류를 수행하는 작업.
Previous Method
1) Sliding Window

-일반적으로 많이 활용되었던 방법.
-사전에 특정 사이즈의 윈도우를 정해놓고, 그 윈도우를 활용해 사진을 훑으며 객체 탐지
2) Selective Search

-사진의 색상이나 모양 등을 토대로 low-level부터 high-level의 객체 영역을 탐지하는 방법.
-RCNN~FasterRCNN까지 활용되었다.
Deep Learning을 활용한 객체 탐지

-딥러닝을 활용한 객체 탐지는 크게 2stage와 1stage로 나뉜다.
-2 stage는 어떤 이미지가 주어지면 가장 먼저 Selective Search 기반의 Region Proposal Network를 지나
객체들의 영역들을 추천해준다.
-이렇게 추천받은 후보 영역들을 기반으로 실제 객체가 있는 영역에 대해 클래스와 위치를 파악하는
Projected Region Proposals를 지난다.
-1 Stage는 이러한 작업이 한 번에 이루어진다.
RCNN
-초창기의 모델로, 크게 복잡하지 않다.

1) Selevtive Search를 통해 약 2,000개의 ROI(Region of Interest)를 추출한다.
2) RoI의 크기를 조절해 모두 동일한 사이즈로 변형한 후
3) RoI를 CNN에 넣어 특징을 추출한다.
4-1) CNN을 통해 나온 특징을 SVM에 넣어 분류를 진행한다.
4-2) CNN을 통해 나온 특징을 Regression을 통해 바운딩 박스를 예측한다.
-간단한 모델이기에 여러 단점이 존재했다.
1) 2,000개의 ROI를 추출해 CNN을 거치기에 속도가 느리다.
2) 강제 와핑으로 인한 원래의 차원이 아니라 성능 손실 가능성이 큼.
3) CNN, SVM, Regression을 따로 학습하여 굳이 따지자면 END-TO-END가 아니다.
SPPNet

-RNN은 Region Proposal 후 Wrping을 하고 난 후의 결과 2,000개를 전부 CNN에 넣었다.
-SPPNet은 먼저 CNN을 거치는 방법을 채택했고, 이를 토대로 ROI를 추출했다.
-이러한 방법은 한 번의 CNN만 거치는 방법으로 느린 속도를 보완했다.
-또한 기존의 CNN은 FC 때문에 고정 크기의 이미지가 입력되었다. 이는 Crop 혹은 Warp(줄이거나 늘리기)를
수행해야 해서 성능 손실 가능성이 존재했다.
-하지만 SPPNet은 이러한 없앴기에 Warping으로 인한 성능 손실 가능성을 줄였고, 고정 크기의 이미지가
필요 없어졌다.
-보다 적은 수의 ROI를 추출하기에 속도가 느린 점을 보완했고, 강제 와핑을 없애 성능 손실
가능성을 줄였다.
-하지만 아직도 end-to-end가 아니고, CNN, SVM, Reg를 별도로 학습해야 한다는 단점이 존재했다.
Fast RCNN

1) 이미지를 CNN에 넣어 특징 추출
2) ROI Projection으로 특징맵 상의 ROI 계산
3) ROI Pooling으로 일정한 크기의 특징 추출
4) FC 이후 Softmax Classification과 Bounding Box Regression
-이러한 방법은 이전의 단점인 세 모델을 따로 학습시켜야 하는 방법이 아니라, 전부 동시 학습이 가능하다.
-하지만 여전히 End-to-end는 아니었는데, 아직 Selective Search 기반의 ROI 추출이 남아있었기 때문이다.
Faster RCNN
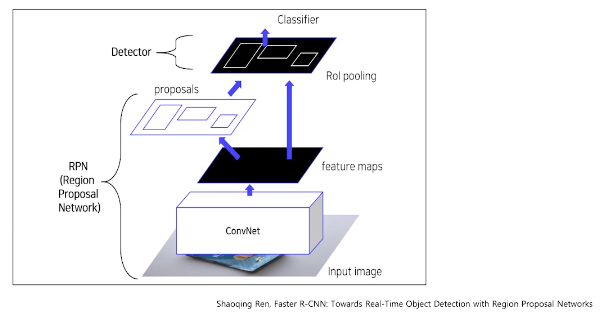
-Fast RCNN은 Selective Search로 영역을 추출했다면, Faster RCNN은 Region Proposal Network라는 새로운
네트워크를 제시했다.
-이로 인해 End-to-end의 모델이 완성되었다.
-Region Proposal Network
-ROI를 만들어내는 메소드이나, Selective Search가 아닌 다른 방법으로 동작.
-동작 원리는 다음과 같다.
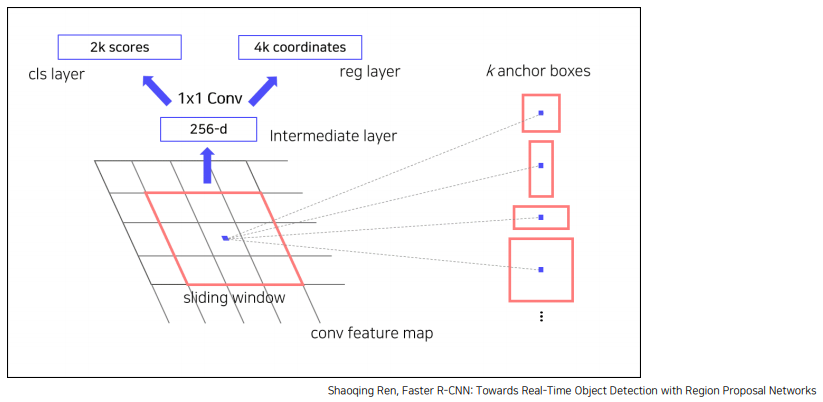
1) CNN을 통해 추출한 특징맵을 입력으로 받는다.
2) 특징맵에 3*3 컨볼루션을 256 혹은 512 채널수만큼 수행한다. 패딩은 1로 주어 이미지 크기를 보존한다.
3) 얻은 특징맵을 입력으로 classification과 bounding box regression 예측값을 반환한다.
이 때 FC 레이어를 사용하는 것이 아니라, Fully Convolution Network를 사용한다.
*NMS : 유사한 RPN Proposals를 제거하기 위해 사용하는데, Class score를 기준으로 proposal을 분류하고,
iou가 0.7 이상인 영역은 중복으로 간주하고 제거한다.
여기까지는 2 Stages 모델이다.
그리고 여기부터는 1 Stages 모델
-2 Stages 까지는 Region Proposal Network로 먼저 영역을 추천하고 시작했다면, 1 Stages는 이 모든 것을
한 단계로 예측한다.
YOLO

-이미지를 CNN에 넣어 s*s grid 특징맵을 추출한다. 그리고 각 grid 별로 분류를 수행하여 분류들을 합쳐
영역을 찾아낸다.
-Loss는 크게 세 가지 파트를 하나로 합쳐 사용한다.

-Localization Loss : 예측된 바운딩 박스의 위치와 크기에 대한 에러 측정
-객체가 탐지되지 않은 경우에 대해서는 loss를 계산하지 않는다.
-sum squared error를 적용하되, 크기에 대해 각 높이와 너비에 루트를 씌웠다. 이는 절대 수치를 계산하면 큰
박스의 오차가 작은 박스의 오차보다 큰 가중치를 받게 되는 점을 보완한 것이다.
-Confidence Loss : 객체가 탐지된 경우와 객체가 탐지되지 않은 경우로 나뉜다. (앞, 뒤)
-둘의 다른 점은 객체가 탐지되지 않은 경우는 loss의 가중치를 적게 함으로써 클래스 불균형 문제를 방지했다.
-classification loss : 객체가 탐지된 경우의 오차이다.
-객체가 탐지되지 않았으면 0이 된다.
-YOLO는 Faster R-CNN에 비해 6배 빠른 속도를 보여주었다.
-하지만 그리드 별로 BBox 예측을 진행하기에 그리드보다 작은 크기의 물체를 검출할 수 없다.
-또한 신경망을 텅과하여 마지막 특징만을 사용하기에 다양한 스케일의 출력을 사용하지 못했고,
이로 인해 정확도가 낮아졌다.
-이러한 다양한 스케일의 출력 사용은 SSD와 YOLO V2 에서 사용되었다.
--
Neck

-BackBone에서 Neck이라는 연구가 진행되었다.
-기존의 모델들은 마지막 Conv층의 출력만을 사용했기에, 고레벨의 특징만을 잡아냈다.
-이러한 문제를 해결하고자, 중간중간의 출력들도 사용하기 위해 고안되었다.
-FPN, PANet, ASPP등이 예시.
FPN (Feature Pyramid Network)

-featurized image pyramid는 각 레벨에서 독립적으로 특징을 추출하여 객체를 탐지한다.
-당연히 연산량과 시간 관점에서 비효율적이다.
-single feature map은 컨볼루션 레이어를 통해 특징을 압축한다.
-하지만 멀티 스케일을 사용하지 않고 한 번에 압축하기에 성능이 별로이다.
-Pyramid Feature Hierachy는 서로 다른 스케일의 특징맵을 이용해 멀티 스케일을 추출한다.
-각 레벨에서 독립적으로 추출하여 이미 계산된 상위 레벨의 특징을 재사용하지 않는다.
-Feature Pyramid Network는 Top-down 방식으로, 추출된 결과들을 묶는다.
-각 레벨에서 독립적으로 특징을 추출하여 객체를 탐지하는데, 상위 레벨의 이미
게산된 특징을 재사용하기에 멀티 스케일 특징들을 효율적으로 사용할 수 있다.
-하지만 원본 이미지인 low level 특징들은 희석되는 문제가 있다.
-그래서 이 문제를 해결하기 위해, 하위 레벨의 특징을 직접 전해주는 방식이 PAN이다.
PAN (Path Aggregarion Network)
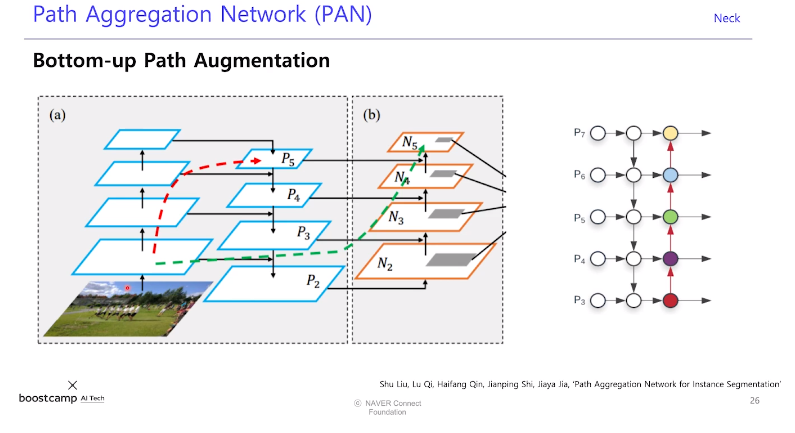
-low level의 특징 정보를 직접 전달했다.
RFP (Recursive Aggreration Network)

-백본의 output을 다시 원래의 백본으로 돌려준다.
'BOOSTCAMP AI TECH > PStage' 카테고리의 다른 글
| 03-02. MRC (Machine Reading Comprehension, 기계독해) (0) | 2021.04.26 |
|---|---|
| 03-01. Object Detection / Segmentation (0) | 2021.04.26 |
| 02-02. Tabular (0) | 2021.04.24 |
| 02-01. KLUE (0) | 2021.04.24 |
| 01. Computer Vision (0) | 2021.04.24 |



