자연어 처리의 응용분야
-의미 분석기
-구문 분석기
-감성 분석기
-형태소 분석기
-개체명 분석기
-등 다양한 자연어처리가 있지만, 대부분은 '분류'문제이다.
-그리고 이러한 분류를 위해 자연어를 벡터화하는 인코딩이 필요하다.
특징 추출과 분류

-분류를 위해선 데이터를 수학적으로 표현해야 한다.
-먼저 분류 대상의 특징을 파악해야 한다.
-그리고 이 특징을 기준으로 분류 대상을 그래프 위에 표현이 가능하고,
분류의 경계를 수학적으로 나눌 수 있다. 이를 Classification이라 한다.
-새로운 데이터 역시 특징을 기준으로 그래프에 표현하면 어떤 그룹과 유사한지 파악할 수 있다.
-과거에는 사람이 직접 특징을 파악해 분류했으나, 실제 복잡한 문제에서는 사람이 파악할 수 없다.
-그래서 이러한 특징을 컴퓨터가 스스로 찾고, 분류하게 하는 것이 기계 학습의 핵심이다.
자연어 단어 임베딩

-자연어를 좌표평면 위에 표현하는 방법
-가장 단순한 표현 방법은 원핫 인코딩 (Sparse Representation)이 있다.
-n개의 단어를 n차원의 벡터로 표현하는 방법이다.
-하지만 단어 벡터가 sparse해서 단어가 가지는 의미를 벡터 공간에 표현할 수는 없다.
-이를 보완하기 위해 Word2Vec이 개발되었다.
-마찬가지로 자연어의 의미를 벡터 공간에 임베딩하는 방법으로, 한 단어의 주변 단어들을 통해
단어의 의미를 파악한다.
-즉, 비슷한 문장 속의 비슷한 위치에 나온 두 개의 단어를 비슷한 의미로 분류한다.
-Word2Vec은 주변부의 단어를 예측하는 방식인 Skip-gram 방식으로 학습한다.
-단어에 대한 dense vector를 얻을 수 있다.
-Word2Vec은 단어 간 유사도 측정과 관계 파악에 용이하다.
-하지만 단어의 subword information을 무시하고, Out of Vocabulary에서 적용할 수 없다.
*subword information 무시 : 서울과 서울시를 다른 단어로 파악.
*OOV : 학습에 사용하지 않은 단어에 대한 벡터값 출력 불가능.
FastText
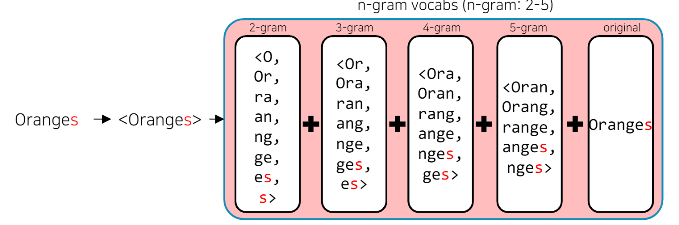
-한국어는 다양한 용언 형태를 가진다 : 모르다, 모르네, 모르데, 모르지 ...
-Word2Vec이러한 subword들을 독립된 Vocab으로 가진다.
-FastText는 이러한 subword에 집중해 만들어진 Word2Vec이다.
-알고리즘 자체는 Word2Vec과 유사하나, 주변 단어와 중심 단어를 만들 때 N-gram을 사용한다.
-n-gram의 범위가 2-5일 때, 단어를 다음과 같이 분리하여 학습한다.
assumption = {as, ss, su, ... , ass, ssu, ..., ption, assumption}
-FastText는 단어를 n-gram으로 분리한 후 모든 n-gram Vector를 합산한 후 평균을 통해 벡터를 획득한다.
-n-gram으로 나눠진 단어는 사전에 들어가지 않으며, 별도의 n-gram vector를 형성한다.
-FastText는 이러한 특성 덕에 오탈자, OOV, 등장 회수가 적은 학습 단어에 대해서도 좋은 성능을 보인다.
단어 임베딩 방식의 한계점
-Word2Vec이나 FastText와 같은 워드 임베딩 방식은 동형어, 다의어 등에 대해선 임베딩 성능이 좋지 못하다.
-예를 들어 account의 여러 뜻을 고려하지 못한다.
-또한 주변 단어를 통해 학습이 이루어지기에 '문맥'을 고려할 수도 없다.
모델과 언어 모델
-모델은 자연 법칙을 컴퓨터로 모사함으로써 시뮬레이션 하는 것.
-이전 상태를 기반으로 미래의 상태를 예측할 수 있다.
-자연어의 법칙을 컴퓨터로 모사한 모델이 언어 모델이다.
-단어 임베딩 방식의 한계를 극복하기 위해 (문맥 이해) 개발되었다.
-주어진 단어들로부터 그 다음에 등장한 단어의 확률을 예측하는 방식으로 학습한다. (이전 상태로 미래 상태 예측)
-다음에 등장할 단어를 잘 예측하는 모델은 그 언어의 특성이 잘 반영된 모델이자 문맥을 잘 계산하는
좋은 언어 모델이다.
언어 모델
1) 마르코브 체인 모델
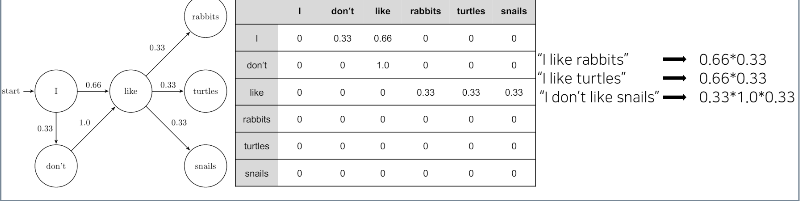
-다음의 단어나 문장이 나올 확률을 통계와 단어의 n-gram을 기반으로 계산
-딥러닝 기반의 언어모델은 해당 확률을 최대로 하도록 학습한다.
2) RNN
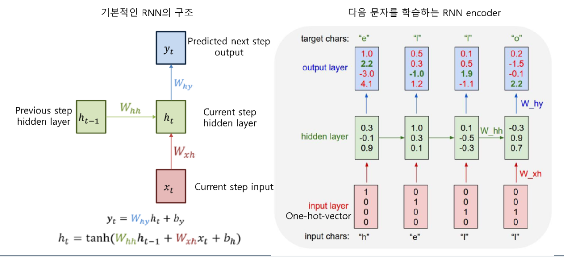
-히든 노드가 방향을 가진 엣지로 연결된 순환 구조
-이전 상태 정보가 다음 상태를 예측하는 데 사용되며, 시계열 데이터 처리에 특화되어있다.
-RNN 기반의 언어 모델은 앞선 단어들의 문맥을 고려해 만들어진 최종 출력 벡터이다 (Context Vector)
-출력된 context vector 값에 대해 classification layer를 붙여 문장 분류를 위한 모델을 만들 수 있다.
3) RNN 기반의 Seq2Seq

-인코더 레이어 : RNN 구조를 통해 컨텍스트 벡터 획득
-디코더 레이어 : 획득된 컨텍스트 벡터를 입력으로 출력 예측
-RNN의 구조의 한계점인, 입력 시퀀스의 길이가 길면 앞의 데이터가 희석되고, 고정된 context vector 사이즈로
Sequenct에 대한 정보 함축과, 중요하지 않은 token도 영향을 주는 한계를 극복하지 못함.
-이로 인해 Attention이 탄생했다.
4) Attention 모델

-인간이 정보처리를 할 때 모든 정보를 고려하는 것이 아니라, 중요한 것만을 고려한다.
-이를 토대로 중요한 feature를 더욱 중요하게 고려하는 것이 모티브이다.
-문맥에 따라 동적으로 할당되는 인코더의 Attention weight로 인한 dynamic context vector를 획득한다.
-기존의 Seq2Seq의 인코더와 디코더의 성능을 비약적으로 향상시켰다.
-하지만 여전이 RNN이 순차적으로 이루어지기에 연산 속도가 느렸다.
-이러한 단점의 극복을 위해 아예 RNN을 빼버린 트랜스포머가 등장했다.
5) Self-Attention (Transformer)

-RNN 구조의 이전 상태를 다음 상태로 연결하는 구조를 없앴다.
-즉 시퀀스 정보를 하나씩 넣지 않고, 전부 넣어버린다.
-또한 인코더와 디코더를 별도로 놓지 않고 하나의 네트워크 안에 포함시켰다.
-현재의 자연어 모델들은 전부 Transformer를 기준으로 개발되었다.
자연어 전처리
-전처리는 원시 데이터를 기계 학습 모델이 학습하는데 적합하게 만드는 프로세스이다.
-즉, 학습에 사용될 데이터를 수집하여 가공하는 모든 프로세스이다.
-모델의 학습에 가장 중요한 것은 데이터이다. 모델을 아무리 바꾸고 튜닝해도 데이터에 문제가 있다면
성능이 나올 수 없다.
-자연어 처리 단계는 다음과 같이 이루어진다.
1) Task 설계 : 문제 제기
2) 필요 데이터 수집
3) 통계학적 분석 : Token 갯수 확인(아웃라이어 제거), 빈도 확인(사전 정의)
4) 전처리 : 개행문자 제거, 특수문자 제거, 공백 제거, 중복 표현 제거, 제목 제거, 불용어 (의미가 없는 단어) 제거 등
5) Tagging : 라벨 달기
6) Tokenizing : 자연어를 단위로 분리 (어절, 형태소, 단어 단위)
-한번에 이 모든 단계가 이루어지는 경우는 거의 없고, 계속 왔다갔다 한다.
Python String 관련 함수




한국어 토큰화
-토큰화 : 주어진 데이터를 토큰 단위(어절, 단어, 형태소, 음절 등)으로 나누는 작업
-문장 토큰화 : 문장을 분리
-단어 토큰화 : 구두점 분리, 단어 분리
-영어는 New York같은 합성어 처리와 It's 같은 줄임말 예외처리만 하면 띄어쓰기로도 충분
-한국어는 조사나 어미를 붙여 말을 만드는 교착어이기에 띄어쓰기만으로는 부족하다.
-한국어에서는 어절이 의미를 가지는 최소 단위인 형태소로 분리한다.
BERT 모델
-Transformer를 기반으로 한 모델.
-Masked를 기반으로 한 모델이다.
-풀어 말하자면, 입력 값에 대해 Masked를 함으로써 보다 어려운 문제에 대해 학습을 함으로써
언어에 대해 확실하게 학습을 진행한다.
-시기상으로는 GPT-1보다 늦게 나오고, GPT-2보다 빨리 나왔다.
-Masked된 자연어를 원본 자연어로 복원하는 방향으로 학습을 한다.
-GPT-2는 Input을 잘라 Next Sequence를 추측하는 방향으로 학습한다.
BERT 모델 구조도

1) Input Layer : 두 개의 문장을 입력으로 받아, 문장1 <SEP> 문장2 로 구성한다.
2) Transformer : 12개의 레이어로 구성된다.
3) CLS : 두 개의 문장들의 관계를 파악한다.
-이러한 구조는 All-to-all Network로 구성된다. 즉, cls 토큰 벡터에 입력된 문장에 대한 정보가 모두 녹아 임베딩 된다.
-그리고 이 <CLS> 토큰을 활용해 분류를 실행한다.
-학습은 영어 위키를 사용했고, WordPiece 토크나이저를 사용했다.
-두 개의 토큰을 <SEP>으로 묶은 후, 15%의 확률로 랜덤하게 선택된 토큰(단어)들을 마스킹한다.
한국어 BERT모델
1) ETRI KoBERT : WordPiece 토크나이저를 사용했지만, 그 전에 형태소 단위로 분리를 먼저 수행했다.
2) KoBERT (SKT) : 형태소 분석을 하지 않고 곧바로 WordPice 토크나이저를 사용.
-ETRI가 보다 좋은 성능을 보이나, 반드시 ETRI 형태소 분석기를 사용해야만 한다. 이로 인해 상황에
맞게 다양한 형태소 분석기를 사용할 수 없다.
*문장 속에는 분류에 중요한 역할을 하는 핵심 단어들이 존재하는데, BERT 내에는 이러한 단어들을 식별하는
구조가 존재하지 않는다. 그래서 중요한 단어의 앞 뒤를 <ENT> </ENT>를 넣어주면 성능이 증가될 수 있다.
BERT 모델 학습
-BERT는 두 문장의 순서 예측(NSP), 마스킹 기법(MSM)을 토대로 학습을 수행한다.
-도메인 특화 태스크의 경우 도메인 특화된 학습 데이터만 사용하는 것이 성능이 더 좋다.
그렇기 때문에 기존의 모델을 가져오는 것보다, 새로 학습하는 것이 더 좋다.
-즉 BERT는 일반 NLP에서는 좋을 지 몰라도, 바이오, 과학, 경제 등 어느 특정 분야가 정해진 문제라면,
그 특정 분야의 언어를 활용한 학습을 진행해야만 한다.
-학습에 앞서 두 개의 문장을 <SEP>으로 분리한 후 Input으로 넣어준다.
BERT-단일 문장 분류 모델 학습

-BERT의 <CLS> 토큰을 분류하는 Dense 레이어를 사용한다.
BERT-두 문장 관계 분류

-주어진 두 개의 문장에 대해 두 문장의 자연어 추론과 의미론적인 유사성을 측정하는 작업
-데이터로는 두 가지를 사용한다.
1) Natural Language Inference (NLI) : 두 개의 문장에 대해 모순, 중립, 함의를 구분
2) Segmantic Text Piar : 두 문장의 의미가 서로 같은 문장인지 검증
*Information Retrieval Question and Answerint(IRQA)
-사전에 정의한 q&a에서 적절한 답변을 예측하는 모델.
-IRQA는 일반 챗봇과 달리 질문에 대한 답을 하나만 예측하는 것이 아니라,
보유한 데이터셋에서 비슷한 질문들을 검출하는 Paraphrase Detection 모델을 추가로 부착하여
예측한 답변이 해당 질문에도 사용될 수 있는지 검출.
BERT-문장 토큰 관계 분류
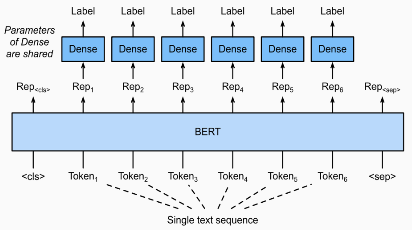
-입력 문장의 각 토큰에 대해 분류를 수행한다.
-대표적으로 Named Entity Recognition(NER, 개체명 인식) 작업이 있다.
-NER은 문맥을 파악하여 인명, 기관명, 지명 등과 같은 문장 또는 문서에서 특정한 의미를 가진
단어 또는 어구(개체)를 인식하는 작업이다.
-또 다른 예로는 Part-of-speech tagging(POS, 품사 태깅) 작업이 있다.
-문장의 각 성분에 대해 가장 알맞은 품사를 태깅하는 작업
-문장 토큰 분류 모델 학습은 문장의 각 토큰에 대해 일일히 분류를 수행한다.
-주의점으로는 객체명 인식을 할 때 음절 단위로 토큰을 분해하는 것이 좋은데, BERT는 WordPiece 토크나이저를
사용하는데, 형태소 단위 토큰 분리 시 잘못 토큰을 분리하면 WordPiece 토크나이저가 분류할 수 없는
토큰이 존재할 수 있다. ex) 이순신은 => 이순 / 신은
-그래서 음절 단위로 토큰을 분리하여 매핑하는 것이 좋은데, 정답은 아니다.
*문장 토큰 관계 분류에 카카오 브레인의 Pororo를 사용하면 좋다.
Text Data Augmentation
1) EDA
-SR, RI, RS, RD를 수행한다. 즉, 동의어 대체, 임의 단어 삽입, 임의 단어 스왑, 임의 단어 삭제 수행
2) Back Translation
-기계 번역의 성능 향상을 위해 소개된 논문.
-MonoLingual 데이터로 Semi-Supervised Learning 방법을 다룬 연구
-일반적으로 기계 번역을 위해 A-B 쌍의 BiLingual 데이터가 필요한데 데이터 구축이 쉽지 않음.
-따라서 MonoLingual 데이터와 BiLingual 데이터를 함께 사용하는 Semi-Supervised Learning 방법이 필요
-BiLingual 데이터로 학습한 후 MonoLingual 데이터에 라벨을 붙여 그 데이터로 추가 학습 수행
-방법은 크게 다섯 가지임.

3) Pre-trained Transformer Models

-AR, AE, Seq2Seq을 이용한 논문
-라벨을 포함하여 fine-tuning 하는 Conditional Pre-training 방법
-앞의 두 방법보다 성능 향상률이 높음.
GPT 모델

-BERT는 Transformer의 인코더를, GPT는 디코더를 사용했다.
-GPT의 언어 학습 방식은 각 토큰에 대해 다음에 나올법한 토큰(단어)가 무엇인지 예측한다.
EX) 발 => 없는 / 받침대 / 각질 => 없는 => 말이 / 새 ...
-GPT는 입력 문장에 대해 Context 벡터 출력 및 Linear 레이어를 통한 분류를 위해 개발되었다.
-그래서 자연어 문장의 분류에 아주 성능이 좋고, 적은 양의 데이터에서도 높은 분류 성능이 나타난다.
-Pre-train 언어 모델의 새 지평을 열었고, BERT로 발전되는 팀거름이 되었다.
-하지만 여전히 지도 학습이 필요하기에 라벨이 필요했다.
-또한 특정 작업을 위해 fine-tuning된 모델은 다른 작업에서 사용할 수 없었다.

-그런데 언어의 특성상 지도학습의 목적 함수를 비지도 학습의 목적 함수와 같다.
-엄청 큰 데이터셋을 사용하면 자연어 task들도 자연스럽게 학습한다.
-GPT 개발 연구진을 "인간은 새로운 작업의 학습을 위해 많은 데이터를 필요로 하지 않는다"는 것을 토대로
"Pre-trained model을 fine tuning을 통해 하나의 태스크만 수행하는 것은 필요는 작업이다"는 가설로 바꾸어
Zero-shot, One-short, Few-shot을 제안한다.
-이러한 것들은 Gradient Learning을 필요로 하지 않고, 분류를 위한 힌트(소스)를 몇 개를 주느냐로 나뉜다.
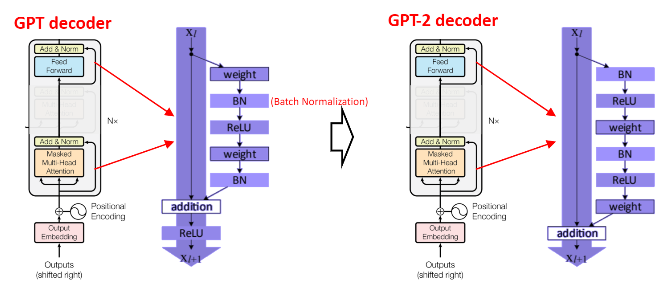
-위의 아이디어를 기반으로 GPT-2가 개발되었다. 파라미터 수와 학습 데이터를 늘려 학습을 시킨 모델이다.
-GPT-2는 다음 단어 예측은 SOTA 성능이었으나, 다른 자연어 태스크는 일반 신경망 수준이었다.
하지만 Zero, One, Few shot이라는 새로운 지표를 열었다.

-그 후 GPT2에서 학습 데이터와 파라미터를 보다 많이 늘려 GPT-3를 개발했다.
-GPT3도 트랜스포머의 디코더를 사용했으나, GPT-2와 약간 다르고, Initialize를 조금 변경했다.
-GPT3는 다양한 자연어 Task에 대해 좋은 성능을 보여주었다. 하지만 Weight update가 없다는 문제가 있다. 이로 인해 시기에 따라 달라지는 문제에 대응이 불가능하다. ex) 한국의 대통령이 누구야? 이승만입니다.
BERT 이후의 언어 모델
-BERT의 경우 <MASK> 토큰을 독립적으로 예측하기에 토큰 사이의 관계 학습이 불가능하다.
-또한 임베딩 길이의 한계로 SEGMENT간 관계 학습이 불가능하다.
-GPT의 경우에는 단일 방향성으로만 학습된다. 즉, 앞을 토대로 뒤를 예측하는 문제가 있다.
1) XLNet

-BERT의 단점인 512 토큰 (임베딩 길이)의 한계를 벗어났다.
-BERT는 포지셔널 인코딩을 512토큰 내에서 절대값을 기준으로 수행하는데,
XLNet은 현재 위치 대비 n번째 상대 거리를 바탕으로 포지셔널 인코딩을 수행한다.
-이러한 방식은 임베딩 길이의 한계를 벗어났다.
-또한 마스크 토큰을 없애고 Permutation Language Modeling 방법으로 학습을 수행한다.
-기존 모델은 원본 문장의 이전 단어에 대해 다음 단어 하나를 예측했다면, XLNet은 입력 문장의 토큰들을 순열 조합을
통해 섞어버리고, 이 섞인 문장에 대해 다음 단어를 하나씩 예측함으로써 단일 방향성의 한계를 벗어났다.
2) RoBERTa
-BERT와 동일한 구조이나 학습 방법을 변경해 보았다.
-모델의 학습 시간을 증가하고, 배치 사이즈를 증가하고, 학습 데이터를 증가했다.
-또한 Next Sentence Prediction을 제거했다. 이유라면 너무 쉬운 문제라 성능이 하락하기 때문
-Longer Sentence를 추가해 보다 긴 문장을 사용할 수 있게 했다.
-Dynamic masking을 활용하 똑같은 텍스트 데이터에 10개의 다른 마스킹을 적용하여 중복하여 학습.
3) BART

-BERT와 GPT를 하나로 합친 모델
-즉, 트랜스포머의 인코더와 디코더를 동시에 사용했다.
-기존의 GPT는 학습 방법으로 Next Token을 예측하고, BERT는 Masked 토큰을 예측하는데, BART는 이를 섞어 위의
그림처럼 다양한 학습을 진행했다.
-즉 온갖 어려운 Task를 할 수 있도록 학습되었다.
4) T-5

-마찬가지로 트랜스포머의 인코더와 디코더를 함께 사용하 모델
-현재를 기준으로 가장 좋은 모델이다.
-Pretrain 과정에서 온갖 task를 다양하게 학습할 수 있다. Scored 데이터, GLUE 데이터 등에 대해서도 학습할
수 있다.
-학습에서 마스킹 기법을 사용하는데, 하지만 마스킹을 하나의 토큰에 하는 것이 아니라, 의미를 가진 여러
토큰들 여러 개를 마스킹 하고, 이를 복원하는 과정으로 학습한다.
-한국어 T-5는 없지만, MultiLingual T-5 안에 한국어가 포함됨.
5) Meena

-대화 모델을 위한 언어 모델
-트랜스포머 인코더 레이어 하나와, 여러 디코더 레이어를 활용해 구축되었다.
-챗봇 평가를 위한 새로운 지표인 Sensibleness and Specificity Average (SSA)를 제시했다.
-특징으로는 기존의 챗봇은 하나의 질문에 대한 하나의 답변이 가능하고, 대화를 이어나가지 못했다.
하지만 Meena는 대화의 흐름을 이해하고, 이전의 대화 내용을 기억해 대화 전체의 흐름을 이해한다.
-SSA는 이러한 평가 지표로, 현재까지의 대화 맥락에서 어울리는 대답을 하였는가, 얼마나 구체적으로 대답을
하였는가에 대한 지표이다.
6) Controllable LM
-이전의 언어 모델들은 결국 확률적으로 선택한다는 한계가 존재했다. 이는 결코 인간이 대답하는 것에 미치지 못한다.
-이러한 점을 보완하고자, Controllable LM이 등장했다.
6-1) Plug and Play LM (PPLM)

-일반적인 LM은 답변 생성을 위해 다음에 등장할 단어에 대해 확률 분포를 통해 선택을 했다.
-PPLM 또한 다음에 등장할 단어를 미리 저장해놓고 확률 분포를 통해 선택한다.
-하지만 원하는 단어들의 확률이 최대가 되도록 이전 상태의 벡터를 수정하고,
수정된 벡터를 통해 다음 단어를 예측한다.
-위의 경우, 원래라면 OK가 나와야 하지만 Delicious가 나오도록 미리 저장을 한다. 이를 위해 Delicious가 나오도록
벡터 정보를 업데이트 한다. 즉, 이전의 벡터값을 수정한다. (경사도가 변경되는 것이 아님에 유의)
-이러한 방법은 기존의 모델에 대한 변경 없이 원하는 문장 생성의 유도가 가능하다.
-또한 확률 분포를 사용하기에 중첩이 가능하고, 이를 통해 특정 카테고리에 대한 감정을 컨트롤할 수 있다.
-흔히 말하는 그라데이션 분노도 생성할 수 있다.


-위는 PPLM의 적용 예시이다. 원하는 방향(음악)으로 문장이 생성된다.
Multimodal
-사람은 언어를 배울 때 언어만을 토대로 언어를 배우는 것이 아니라, 다양한 감각을 토대로 언어를 배운다.
-하지만 인공지능은 언어를 토대로 언어를 배우기에, 이는 충분하지 못하고, 이러한 점을 토대로 최근에는
MultiModal에 대한 연구가 진행되고 있다.
1) LXMERT

-이미지와 자연어를 동시에 학습한 후 이 정보를 하나의 모델로 합친 모델
-이미지에 대한 객체 인식을 수행하여 "이미지 속에 고양이가 어디에 있어"와 같은 질문에 대한 응답 출력
2) ViLBERT
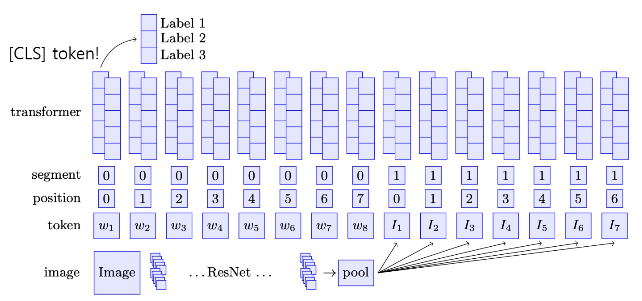
-원래의 BERT는 "문장 <SEP> 문장" 이었으나, ViBERT는 "이미지에 대한 임베딩 벡터 <SEP> 자연어" 를 넣어
이미지와 자연어에 대한 <CLS>를 만들어낸다.
-그리고 해당 <CLS>를 분류하여 자연어와 이미지가 합쳐진 Multimodal 정보를 통해 분류를 수행한다.
3) Dall-e
-자연어로부터 이미지를 생성하는 모델
-작동 방식은 다음과 같다.
1) VQ-VAE를 통해 이미지의 차원 축소를 학습한다.
2) Autoregressive 형태로 다음 토큰 예측을 학습한다. (GPT-2의 학습 방식과 같음)
'BOOSTCAMP AI TECH > PStage' 카테고리의 다른 글
| 03-02. MRC (Machine Reading Comprehension, 기계독해) (0) | 2021.04.26 |
|---|---|
| 03-01. Object Detection / Segmentation (0) | 2021.04.26 |
| 02-02. Tabular (0) | 2021.04.24 |
| 01. Computer Vision (0) | 2021.04.24 |
| 00. 시각화 (0) | 2021.04.24 |


