데이터 시각화
-데이터를 그래픽 요소로 매핑하여 시각적으로 표현하는 것
-연구에서 사용하지 말라는 시각화가 실무에서 요구될 수도 있다.
-즉 시각화에 정해진 정답은 없다.
데이터셋의 종류
1) 정형 데이터 : 테이블 형태로 제공되는 데이터. 가장 쉽게 시각화할 수 있다.
2) 시계열 데이터 : 기온, 주가 등의 정형 데이터와 음성, 비디오 같은 비정형 데이터가 존재.
시간의 흐름에 따라 추세, 계절성, 주기성 등을 살펴야 한다.
3) 지리/지도 데이터 : 지도 정보와 보고자 하는 정보 간의 조화가 중요하다.
4) 관계 데이터 : 객체간 관계가 존재하여, 객체는 노드, 관계는 링크로 표현한다.
5) 계층적 데이터 : 관계 중에서도 포함 관계가 분명한 데이터로, 트리 등이 예시이고 네트워크 시각화 가능
-데이터 종류는 다양하게 분류할 수 있으나, 대표적으로 4가지로 분류된다.
1) 수치형 : 수로 표현하는 데이터
1-1) 연속형 : 길이, 무게, 온도 등
1-2) 이산형 : 주사위 눈금, 사람 수 등
2) 범주형 : 수로 표현될 수 있지만, 수치 자체에 연속성이 없는 경우
2-1) 명목형 : 혈액형, 종교 등
2-2) 순서형 : 학년, 별점, 등급 등
시각화 이해하기
1) 마크와 채널
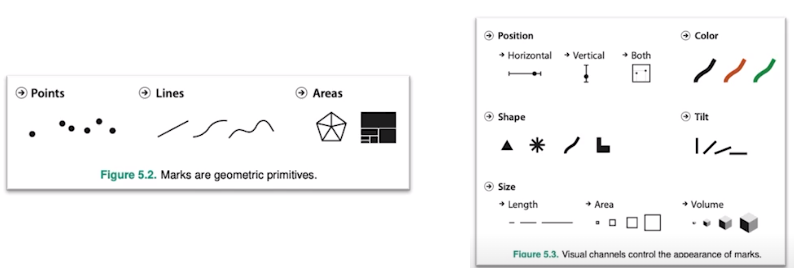
-마크 : 점, 선, 면으로 이루어진 데이터 시각화
-채널 : 각 마크를 변경할 수 있는 요소들
2) 전주의적 속성 (Pre-attentive Attribute)

-주의를 주지 않아도 인지되는 요소로,
시각적으로 다양한 전주의적 속성이 존재한다.
-하지만 동시에 사용하면 인지하기 어려울 수 있으니, 적절하게 사용해야 한다.
Bar Plot 사용하기
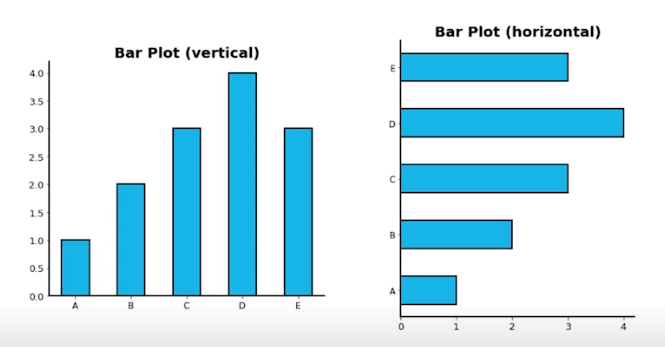
-Bar Plot이란 직사각형 막대를 사용하여 데이터 값을 표현하는 그래프
-막대 그래프, bar chart, bar graph 등의 이름으로 불린다.
-범주에 따른 수치값을 비교하기에 적합한 방법이다. (개별 비교와 그룹 비교 모두 적합)
-막대의 방향에 따른 분류
1) 수직 (.bar()) : x축에 범주, y축에 값
2) 수평 (.barh()) : y축에 범주, x축에 값 => (범주가 많을 때 적합)
다양한 BarPlot
1) Multiple Bar Plot
-여러 그룹을 보여주기 위해 플롯을 여러 개 그리는 방법.
-쌓아서 표현할 수 있고, 겹쳐서 표현할 수도 있고, 이웃에 배치하여 표현할 수도 있다.
fig, axes = plt.subplots(1, 2, figsize=(15, 7))
axes[0].bar(group['male'].index, group['male'], color='royalblue')
axes[1].bar(group['female'].index, group['female'], color='tomato')
plt.show()
2) Stacked Bar Plot
-2개 이상의 그룹을 쌓아 표현하는 Bar plot
-각 바에서 나타나는 그룹의 순서는 항상 유지된다.
-맨 밑의 bar의 분포는 파악하기 쉽지만 그 외의 분포는 파악하기 어려울 수 있다.
-2개의 그룹이 긍정/부정 이라면 축 조정 가능.
-bar에서는 bottom 파라미터를, barh에서는 left 파라미터를 사용하여 구현.
-응용하여 전체에서 비율을 나타내는 Percentage Stacked Bar Chart 구현도 가능하다.
fig, axes = plt.subplots(1, 2, figsize=(15, 7))
group_cnt = student['race/ethnicity'].value_counts().sort_index()
axes[0].bar(group_cnt.index, group_cnt, color='darkgray')
axes[1].bar(group['male'].index, group['male'], color='royalblue')
axes[1].bar(group['female'].index, group['female'], bottom=group['male'], color='tomato')
for ax in axes:
ax.set_ylim(0, 350)
plt.show()#Percentage Stacked Bar Plot
fig, ax = plt.subplots(1, 1, figsize=(12, 7))
group = group.sort_index(ascending=False) # 역순 정렬
total=group['male']+group['female'] # 각 그룹별 합
ax.barh(group['male'].index, group['male']/total,
color='royalblue')
ax.barh(group['female'].index, group['female']/total,
left=group['male']/total,
color='tomato')
ax.set_xlim(0, 1)
for s in ['top', 'bottom', 'left', 'right']:
ax.spines[s].set_visible(False)
plt.show()
3) Overlapped Bar Plot
-위의 분포를 파악하기 어렵다는 Stacked Bar Plot의 단점을 극복.
-하지만 3개 이상의 그룹의 비교에는 좋지 않다.
-같은 축을 사용하기에 비교가 쉽고, 투명도를 조정하면 겹치는 부분을 파악할 수 있다. (alpha)
-Bar Plot보다는 Area Plot에서 더 효과적이다. (seaborn 모듈)
group = group.sort_index() # 다시 정렬
fig, axes = plt.subplots(2, 2, figsize=(12, 12))
axes = axes.flatten()
for idx, alpha in enumerate([1, 0.7, 0.5, 0.3]):
axes[idx].bar(group['male'].index, group['male'],
color='royalblue',
alpha=alpha)
axes[idx].bar(group['female'].index, group['female'],
color='tomato',
alpha=alpha)
axes[idx].set_title(f'Alpha = {alpha}')
for ax in axes:
ax.set_ylim(0, 200)
plt.show()
4) Grouped Bar Plot
-그룹별 범주에 따른 bar를 이웃되게 배치하는 방법
-Matplotlib에서는 비교적 구현이 까다로움.
fig, ax = plt.subplots(1, 1, figsize=(12, 7))
idx = np.arange(len(group['male'].index))
width=0.35
ax.bar(idx-width/2, group['male'],
color='royalblue',
width=width)
ax.bar(idx+width/2, group['female'],
color='tomato',
width=width)
ax.set_xticks(idx)
ax.set_xticklabels(group['male'].index)
plt.show()
정확한 Bar Plot
-Principle of Proportion Ink (잉크양 비례 법칙) : 실제 값과 그에 표현되는 그래픽으로 표현되는
잉크 양은 비례해야 한다.
-반드시 x 축의 시작은 0 이어야 하고, 만약 차이를 나타내고 싶다면 plot의 세로 비율을 늘려라.
-막대 그래프에만 한정되는 원칙은 아니고, 다양한 플롯과 차트의 시각화에서 사용된다.
-더 정확한 정보 전달을 위해서는 정렬이 필수이다.
-Pandas 에서는 sort_values(), sort_index()를 사용하면 정렬 가능.
-시계열은 시간순으로, 수치형은 크기순으로, 순서형은 범주순으로, 명목형은 범주의 값에 따라 정렬하자.
-여러 가지 기준으로 정렬을 하다보면 패턴 발견도 가능하다.
-여백과 공간을 조정하여 적절한 공간을 활용하면 가독성이 높아진다.
-필요없는 복잡함은 지양하고, 가능하면 단순하게 표현하는 것이 좋다.
-또한 오차 막대를 추가하여 Uncertainty 정보를 추가하면 좋다.
-Bar 사이의 gap이 0이라면 hist()를 사용해서 히스토그램으로 표현하면 연속된 느낌을 줄 수 있다.
Line Plot

-연속적으로 변화하는 값을 순서대로 점으로 나타내고 선으로 연결한 그래프
-꺾은선 그래프, 선 그래프, line chart, line graph 등의 이름으로 사용된다.
-시간/순서에 대한 변화에 적합하여 추세를 살피기 위해 사용. 즉, 시계열 분석에 특화
-.plot 으로 활용할 수 있다.
-5개 이하의 선을 사용하는 것을 추천한다. => 많은 선은 중첩으로 인한 가독성 하락
-선을 구별하는 요소는 (색상, 마커, 선의 종류) 가 있다.
Line plot을 위한 전처리
-시시각각 변동하는 데이터는 노이즈로 인해 패턴 및 추세 파악이 어렵다.
-노이즈의 인지적인 방해를 줄이기 위해 smoothing을 사용해야 한다.
-어떤 구간에 대해 평균을 내어 사용하는 방법이 대표적이다. (이동평균 방법)
#DATA : 미국 주식 데이터셋 : https://www.kaggle.com/dgawlik/nyse
stock = pd.read_csv('./prices.csv')
stock['date'] = pd.to_datetime(stock['date'], format='%Y-%m-%d', errors='raise')
stock.set_index("date", inplace = True)
# FAANG
apple = stock[stock['symbol']=='AAPL']
google = stock[stock['symbol']=='GOOGL']
google.head()
fig, ax = plt.subplots(1, 1, figsize=(15, 7), dpi=300)
ax.plot(google.index, google['close'])
ax.plot(apple.index, apple['close'])
plt.show()
#이동 평균 사용
google_rolling = google.rolling(window=20).mean()
fig, axes = plt.subplots(2, 1, figsize=(12, 7), dpi=300, sharex=True)
axes[0].plot(google.index,google['close'])
axes[1].plot(google_rolling.index,google_rolling['close'])
plt.show()
정확한 Line plot

-막대 그래프와 달리 추세를 보기 위한 목적이기에 축을 0에 초점을 둘 필요가 없다.
-너무 구체적인 line plot보다는 생략된 line plot이 더 나을 수 있다.
-즉, Grid, annotate 등은 모두 제거하고, 디테일한 정보는 표로 제공하자.
-생략되지 않는 선에서 범위를 조정하여 변화율을 관찰하자.
-위의 경우 오른쪽이 좋긴 하지만, 그렇다고 언제나 오른쪽이 좋은 게 아니라, 실제 값이 중요한 경우에는 왼쪽이
더 좋다.
#추세에 집중
from matplotlib.ticker import MultipleLocator
fig = plt.figure(figsize=(12, 5))
np.random.seed(970725)
x = np.arange(20)
y = np.random.rand(20)
# Ax1
ax1 = fig.add_subplot(121)
ax1.plot(x, y,
marker='o',
linewidth=2)
ax1.xaxis.set_major_locator(MultipleLocator(1))
ax1.yaxis.set_major_locator(MultipleLocator(0.05))
ax1.grid(linewidth=0.3)
# Ax2
ax2 = fig.add_subplot(122)
ax2.plot(x, y,
linewidth=2,)
ax2.spines['top'].set_visible(False)
ax2.spines['right'].set_visible(False)
ax1.set_title(f"Line Plot (information)", loc='left', fontsize=12, va= 'bottom', fontweight='semibold')
ax2.set_title(f"Line Plot (clean)", loc='left', fontsize=12, va= 'bottom', fontweight='semibold')
plt.show()
-간격은 규칙적인 간격이 아니라면 오해를 줄 수 있다.
-그래프 상에서 간격이 규칙적이면 기울기 정보를 오해할 수 있고, 간격이 다르면 없는 데이터에 대해 있다고
오해할 수 있다.
-그러므로 규칙적인 간격의 데이터가 아니라면 각 관측 값에 점으로 표시하여 오해를 줄여야 한다.
x = [2, 3, 5, 7, 9]
y = [2, 3, 4, 7, 10]
fig, ax = plt.subplots(1, 3, figsize=(13, 4))
ax[0].plot([str(i) for i in x], y)
ax[1].plot(x, y)
ax[2].plot(x, y, marker='o')
plt.show()-보간 : Line은 점을 이어 만드는 요소이고, 보간은 점 사이에 데이터가 없기에 이를 잇는 방법이다.
-데이터에 에러나 노이즈가 포함되었을 때 데이터의 이해를 돕는 방법이다.
-프레젠테이션에서는 좋을 수 있으나 일반적인 분석에서는 지양해야 한다.
=> 없는 데이터를 있다고 생각할 수 있으며 작은 차이를 없앨 수 있다.
from scipy.interpolate import make_interp_spline, interp1d
import matplotlib.dates as dates
fig, ax = plt.subplots(1, 2, figsize=(20, 7), dpi=300)
date_np = google.index
value_np = google['close']
date_num = dates.date2num(date_np)
# smooth
date_num_smooth = np.linspace(date_num.min(), date_num.max(), 50)
spl = make_interp_spline(date_num, value_np, k=3)
value_np_smooth = spl(date_num_smooth)
# print
ax[0].plot(date_np, value_np)
ax[1].plot(dates.num2date(date_num_smooth), value_np_smooth)
plt.show()-이중 축 : 한 플롯에 대해 2개의 축을 이중 축이라고 한다.
-같은 시간 축에 대해 서로 다른 종류의 데이터를 표현하기 위해 축이 2개가 필요하다.
-한 데이터에 대해 다른 단위가 있을 때도 사용한다.
-하지만 이중 축은 지양하는 것이 좋다. 두 개의 그래프가 상관이 없는 데 상관이 있는 것처럼 보일 수 있기 때문.
그러니 그냥 2개의 plot을 그리자.
fig, ax1 = plt.subplots(figsize=(12, 7), dpi=150)
# First Plot
color = 'royalblue'
ax1.plot(google.index, google['close'], color=color)
ax1.set_xlabel('date')
ax1.set_ylabel('close price', color=color)
ax1.tick_params(axis='y', labelcolor=color)
# # Second Plot
ax2 = ax1.twinx()
color = 'tomato'
ax2.plot(google.index, google['volume'], color=color)
ax2.set_ylabel('volume', color=color)
ax2.tick_params(axis='y', labelcolor=color)
ax1.set_title('Google Close Price & Volume', loc='left', fontsize=15)
plt.show()
def deg2rad(x):
return x * np.pi / 180
def rad2deg(x):
return x * 180 / np.pi
fig, ax = plt.subplots()
x = np.arange(0, 360)
y = np.sin(2 * x * np.pi / 180)
ax.plot(x, y)
ax.set_xlabel('angle [degrees]')
ax.set_ylabel('signal')
ax.set_title('Sine wave')
secax = ax.secondary_xaxis('top', functions=(deg2rad, rad2deg))
secax.set_xlabel('angle [rad]')
plt.show()-라인 끝 단에 레이블을 추가하면 식별에 도움이 될 수 있다. (즉, 범례 대신 쓰자.)
-또한 Min/max 정보를 추가하면 도움이 될 수 있다.
-또한 신뢰구간, 분산 등을 추가해주면 좋을 수 있다.
Scatter plot (산점도)

-점을 사용하여 두 특징 간의 관계를 알기 위해 사용되는 그래프
-직교 좌표계에서 x, y에 특징 값을 매핑하여 사용하고, scatter 함수로 구현한다.
-점에서 다양한 변수를 사용하여 표현이 가능하다. (색, 모양, 크기)
Scatter plot의 목적
1) 상관 관계 (양, 음, 없음)를 확인할 수 있다.
2) 군집, 값 사이의 차이, 이상치를 확인할 수도 있다.
정확한 Scatter Plot

-점이 많아질수록 점의 분포를 파악하기 힘들다.
-그래서 투명도를 조정하거나, 지터링 (점의 위치를 약간씩 변경)를 사용할 수 있다.
-또한 2차원 히스토그램, Contour plot(등고선)으로 변경하여 표현할 수도 있다.
-Scatter plot의 각 데이터의 크기를 크게 하면 버블 차트가 된다.
-구별하기 쉽지만 오용하기 쉬울 수 있다.
-이러한 것은 관계보다는 점간 비율에 초점을 둘 때 사용되고,
-SWOT 분석 등에 활용이 가능하다.
-추세선을 사용하면 scatter의 패턴을 유추할 수 있으나, 2개 이상이 되면 가독성이 떨어질 수 있다.
-또한 Grid는 지양하고, 사용해야 한다면 무채색으로 사용하고 최소한으로 사용한다.
-범주형이 포함된 관계는 heatmap 또는 bubble chart를 추천함.
Text 사용하기

-시각화에 Text? : 시각적으로 표현할 수 없는 설명이 존재할 것이고, 잘못된 전달에서 생기는 오해 방지 가능.
-물론 너무 많이 사용하면 이해를 방해할 수 있음.
Clolor 사용하기

-그래프에서 위치와 색은 가장 효과적으로 채널을 구분할 수 있는 요소이다.
-위치는 시각화 방법에 따라 자동으로 결정되지만, 색은 개발자가 직접 골라야 한다.
-색을 사용하는 것은 인사이트를 효과적으로 전달할 수 있는 요소이다.
-색을 사용하는 것은 통용되는 색을 사용하는 것이 좋다. (정치의 경우 보수는 빨강, 진보는 파랑)
Color Palette의 종류
1) Categorical

-Discrete, Qualitative 등 다양한 이름으로 불리며, 독립된 색상으로 구성되어 범주형 변수에 사용된다.
-즉, 색상을 통해 어떤 색과 어떤 색이 유사하다는 느낌을 주지 않는다.
-그렇기에 색의 차이로 구분하고, 채도, 명도를 조정하지 않는다.

2) Sequential

-정렬된 값을 사용하는 순서형, 연속형 변수에 적합하다.
-연속적인 색상을 사용하여 값을 표현하는데, 어두운 배경에서는 밝은 색이, 반대에서는 어두운 색이 큰 값을 표현
-색상은 단일 색조로 표현하고, 균일한 색상 변화가 필요

3) Diverge (발산형)

-연속형과 유사하지만 중앙을 기준으로 발산한다.
-상반된 값 (온도 등)과 서로 다른 2개 (지지율 등)을 표현하는 데 적합하다.
-양 끝으로 갈수록 진해지며, 중앙의 색은 양쪽의 점에 편향되지 않아야 한다.

그 외
-데이터에서 다름을 보이기 위해 Highlighting (강조)를 사용할 수 있다.
-방법으로는 명도 대비, 색상 대비, 채도 대비, 보색 대비 등의 색상 대비가 있다.
-그런데 시각화에서 색을 신경쓸 때 색맹과 색약이신 분들에 대한 배려가 필요하다. 그렇기에 이에 대한 고려는
필수적이다.
Facet (분할)
-화면 상에 View를 분할 및 추가하여 다양한 관점을 전달한는 방법
-같은 데이터셋에 서로 다른 인코딩을 통해 다른 인사이트를 얻을 수 있고,
같은 방법으로 동시에 여러 특징들을 보거나,
큰 틀에서는 볼 수 없었던 부분 집합을 세세하게 보여줄 수 있다.
Matplotlib에서의 구성
1) NxM subplots

-Figure와 Axes로 사용할 수 있다.
-Figure은 큰 틀로 언제나 1개이고, Axes는 각 플롯이 들어가는 공간이다.
-plt.subplot(), plt.figure() + fig.add_subplot(), plt.subplots()로 사용할 수 있다.
2) Grid Spec의 활용

-그리드 형태의 subplot.
-그러나 다른 사이즈를 만들기 위해서는 Slicing을 사용하거나, x, y, dx, dy를 사용해야 한다.
-fig.add_grid_spec() 함수를 사용하거나 fig.subplot2grid() 를 사용하면 된다.
#add_gridspec
fig = plt.figure(figsize=(8, 5))
gs = fig.add_gridspec(3, 3) # make 3 by 3 grid (row, col)
ax = [None for _ in range(5)]
ax[0] = fig.add_subplot(gs[0, :])
ax[0].set_title('gs[0, :]')
ax[1] = fig.add_subplot(gs[1, :-1])
ax[1].set_title('gs[1, :-1]')
ax[2] = fig.add_subplot(gs[1:, -1])
ax[2].set_title('gs[1:, -1]')
ax[3] = fig.add_subplot(gs[-1, 0])
ax[3].set_title('gs[-1, 0]')
ax[4] = fig.add_subplot(gs[-1, -2])
ax[4].set_title('gs[-1, -2]')
for ix in range(5):
ax[ix].set_xticks([])
ax[ix].set_yticks([])
plt.tight_layout()
plt.show()
#subplot2grid
fig = plt.figure(figsize=(8, 5)) # initialize figure
ax = [None for _ in range(6)] # list to save many ax for setting parameter in each
ax[0] = plt.subplot2grid((3,4), (0,0), colspan=4)
ax[1] = plt.subplot2grid((3,4), (1,0), colspan=1)
ax[2] = plt.subplot2grid((3,4), (1,1), colspan=1)
ax[3] = plt.subplot2grid((3,4), (1,2), colspan=1)
ax[4] = plt.subplot2grid((3,4), (1,3), colspan=1,rowspan=2)
ax[5] = plt.subplot2grid((3,4), (2,0), colspan=3)
for ix in range(6):
ax[ix].set_title('ax[{}]'.format(ix)) # make ax title for distinguish:)
ax[ix].set_xticks([]) # to remove x ticks
ax[ix].set_yticks([]) # to remove y ticks
fig.tight_layout()
plt.show()
3) 내부에 그리기

-AX 내부에 서브플롯을 추가하는 방법
-미니맵과 같은 형태로 추가할 수 있고, 외부 정보를 적은 비중으로 추가할 수 있다.
-ax.inset_axes()로 구현 가능.
fig, ax = plt.subplots()
axin = ax.inset_axes([0.8, 0.8, 0.2, 0.2])
plt.show()
fig, ax = plt.subplots()
color=['royalblue', 'tomato']
ax.bar(['A', 'B'], [1, 2],
color=color
)
ax.margins(0.2)
axin = ax.inset_axes([0.8, 0.8, 0.2, 0.2])
axin.pie([1, 2], colors=color,
autopct='%1.0f%%')
plt.show()
-그리드를 사용하지 않고 사이드에 추가할 수도 있다.
-make_axes_locatable(ax)로 구현.
from mpl_toolkits.axes_grid1.axes_divider import make_axes_locatable
fig, ax = plt.subplots(1, 1)
ax_divider = make_axes_locatable(ax)
ax = ax_divider.append_axes("right", size="7%", pad="2%")
plt.show()
fig, ax = plt.subplots(1, 1)
# 이미지를 보여주는 시각화
# 2D 배열을 색으로 보여줌
im = ax.imshow(np.arange(100).reshape((10, 10)))
divider = make_axes_locatable(ax)
cax = divider.append_axes("right", size="5%", pad=0.05)
fig.colorbar(im, cax=cax)
plt.show()Grid (격자)

-격자는 축과 평행한 선을 사용해 거리 및 값 정보를 보조적으로 제공한다.
-전형적인 Grid는 아니지만, 여러 형태의 Grid가 존재한다.

-이러한 방법은 matplotlib에서는 제공하지 않고, numpy와 함께 사용하면 구현이 가능하다.
-medium.com/nightingale/gotta-gridem-all-2f768048f934

-두 변수의 합이 중요할 때

-기울기가 다양한 그래프.
-비율이 중요할 때

-특정 데이터를 중심으로 하여 거리를 살펴봐야 할 때
심플한 처리
-어렵지 않게 더 많은 정보와 주의를 줄 수 있는 방법들
1) 선 추가하기 : 평균, 최대, 최소 값등을 추가 가능
2) 면 추가하기 : 데이터들을 등급으로 나눌 때 사용 가능.
'BOOSTCAMP AI TECH > PStage' 카테고리의 다른 글
| 03-02. MRC (Machine Reading Comprehension, 기계독해) (0) | 2021.04.26 |
|---|---|
| 03-01. Object Detection / Segmentation (0) | 2021.04.26 |
| 02-02. Tabular (0) | 2021.04.24 |
| 02-01. KLUE (0) | 2021.04.24 |
| 01. Computer Vision (0) | 2021.04.24 |


