Multi modal learning

-다양한 타입과 특성의 데이터를 활용한 학습법
-즉, 서로 다른 데이터를 사용해 진행하는 학습법
-물론 실제로는 그렇게 쉬운 문제가 아니다.
-그 이유로 Multi model learning은 세 가지 어려운 점이 있다.

1) 다양한 데이터를 활용해야 하는데, 각 데이터는 특징이 달라 표현법이 서로 다르다.
2) 서로 다른 모달리티에서 오는 정보의 양이 고르지 못하다.
=> 텍스트에서는 하나지만, 이미지에서는 많은 양이 나온다.
3) 여러 모달리티를 사용하기에 각 모달리티를 공평하게 참조를 해야하는데 그러지 못하다.
=> NN 모델들은 결과를 내기 위해 중요한 데이터에 큰 가중치를 두는 경향이 있다.
이로 인해 시각+소리 데이터를 넣었을 때 시각이 대상의 식별에 더 큰 영향을 끼치기에 시각 데이터에
더 많은 가중치를 두게 된다.
-여러 센서에서 오는 출력 데이터를 Multi-modal Learning 하는 방법은 다음과 같다.

1) Matching : 서로 다른 데이터를 공통된 공간으로 보내 매칭
2) Translating : 하나의 데이터를 다른 데이터로 변환
3) Referencing : 하나의 모달리티에서 같은 모달리티로 출력을 내보낼 때 다른 모달리티를 참조하며 상호작용
*Matching의 예로는 이미지 태깅
*Translating의 예로는 이미지 캡션 (이미지를 보고 설명 생성
*Referencing의 예로는 Visual question answering
Multi-modal tasks - Visual data & Text
Text embedding

-캐릭터 레벨로 머신러닝을 진행하는 것은 좋지 않음 (추가)
-그래서 일반적으로 워드 레벨로 머신러닝을 진행한다.
-단어는 임베딩 벡터라는 다차원 벡터로 표현한다.
-임베딩 벡터는 2D로 표현하면 비슷한 단어는 가까운 위치에 표현된다.
-또한 같은 관계의 단어들은 비슷한 정도로 떨어져있다.
-이는 임베딩 벡터는 단어 사이의 관계를 나타낸다고 볼 수 있다. (추가)
-Word2Vec은 단어 간 유사도를 반영할 수 있도록 단어의 의미를 벡터화할 수 있는 워드 임베딩 방법.
-Word2Vec은 Skip-gram model과 CBOW 를 사용하여 구현할 수 있다.
-CBOW는 주변 단어를 통해 중심 단어를 예측하는 것이고, Skip-gram model은 중심 단어를 통해 주변 단어를
예측한다.

Joint embedding
-Matching을 하기 위한 공통된 임베딩 벡터들을 학습하는 방법이다.
-다음의 작업들이 가능하다.
1) Image Tagging

-입력 이미지를 통해 태그를 생성하거나, 태그를 활용해 이미지를 검색하는 방법.
-구현 방법은 Pre-trained된 Unimodel 모델들을 합쳐주면 가능하다.
-즉, NLP 관련 모델과 CNN 모델을 학습시킨 후 출력한 특징 벡터들을 같은 차원으로 맞춰준 후,
연관성 있는 차원끼리 합쳐주는 Joint embedding space를 학습한다.
-Joint embedding space의 학습을 위해 텍스트와 이미지 데이터를 같은 공간에 매핑해주고 같은 데이터 간 거리는
좁히고 다른 데이터 간 거리는 넓히는 방법으로 학습을 진행한다.
-이러한 거리 기반 학습 방법을 Metric Learning이라고 한다.
-이렇게 학습된 모델은 텍스트 임베딩과 마찬가지로 거리 기반의 관계 파악이 가능해진다.

2) Image & food recipe retireval

-음식 이미지와 조리법을 연결해주는 방법
-쿼리 이미지를 넣었을 때 해당 이미지 속 음식의 조리법을 추출하거나,
조리법을 입력했을 때 만들 수 있는 음식의 이미지를 출력하는 방법
-레시피는 RNN 계열의 모델을 활용해 재료들이 어떤 순서로 추가되는지 파악하여 특징을 추출한다.
-또한 같은 방법으로 조리법을 인코딩하여 특징을 추출한다.
-이미지는 CNN을 통해 피처맵을 추출한다.
-Cosine 유사도를 사용해 연관된 특징들을 매핑해주며 Joint Embedding을 학습하고,
Semantic Regularization Loss를 통해 높은 레벨의 semantics를 학습한다.
*코사인 유사도 : 내적공간의 두 벡터간 코사인 값을 통해 유사도 파악

*Semantic Regularization Loss

Cross modal translation
-아래의 작업들이 가능하다.
1) Image captioning
-주어진 이미지를 잘 설명하는 설명 문장을 생성하는 모델
-즉, Image-to-Sentence 모델로 CNN과 RNN을 사용한다.
1-1) Show and Tell

-CNN을 인코더로, RNN을 디코더로 활용한다.
-인코더인 CNN이 입력 이미지를 FC 레이어를 통해 고정된 특징으로 만들어 RNN의 시작 토큰으로 입력한다.
-RNN은 시작 토큰을 기준으로 단어들을 출력하여 최종적으로 문장을 생성하게 된다.
-이러한 구조 상 Show and Tell은 전체 이미지에 대한 특징에서 문장을 생성할 수 밖에 없다.
1-2) Show, Attend, and Tell

-전체 이미지를 보고 판단하는 Show and Tell에서 발전하여, 국지적인 정보를 보고 판단하는 모델이다.
-구조상 다른 점은 특징을 FC 레이어를 거친 벡터가 아닌 특징맵의 형태로 RNN에 넘겨준다.
-Attention 과정은 다음과 같다.

-인간이 사물을 볼 때 전체가 아닌 특징적인 부분들을 위주로 보는 것을 기원으로 삼았다.
-위 모델에서의 어텐션은 특징맵을 받아 RNN을 통과시켜 집중적으로 확인해야 하는 부분을 확인하는 히트맵을 만든다.
-그리고 히트맵과 특징맵을 결합하여 z를 만드는데, 이를 softmax attention 임베딩이라 부른다.
-z는 히트맵과 특징맵의 weighted sum (내적)을 한 다음 평균을 구함으로써 만들어진다.
-상세하게 살펴보면 다음과 같다.

1) 가장 먼저 CNN의 결과로 특징맵을 출력한다. 이를 RNN 모델의 컨디션으로 넣어준다.
2) 해당 컨디션을 바탕으로 어떤 부분이 중요한지 (어떤 부분을 어텐션할지) s1을 출력한다.
그렇게 나온 s1 내적을 이용해 z1을 생성하고, z1과 스타트 토큰인 y1을 토대로 RNN이 다음 출력을 만든다.
출력은 시작 단어 d1 (A)와, 다음으로 중요한 부분을 확인할 s2를 만든다.
3) d1은 출력으로 향하고 d1은 특징맵과 weighted sum을 통해 z2가 되고, y2는 이전에 출력한 단어가 되어
RNN의 입력으로 다음 단어를 출력한다.
3) Text-to-Image by generative model

-문장을 통해 이미지를 생성하는 방식
-사실 구현법 자체는 컨디셔널 GAN과 같다.
-텍스트 전체를 Fixed dimensional 벡터로 만들고, 가우시안 랜덤 코드를 앞에 붙여준다.
-가우시안 랜덤 코드는 똑같은 input에 대해 항상 똑같은 결과만이 나오는 것을 방지해준다.
-즉, 다양한 결과가 나올 수 있게 해준다.
-컨디션 정보와 입력 정보가 함께 생성자에 들어가면 생성자는 새로운 이미지를 생성한다.
-판별자는 생성된 이미지를 받아 낮은 차원의 특징을 추출하여 문장의 특징을 받아 그래서 생성된 이미지가
True이냐 False이냐를 판별한다.
Cross model reasoning (Referencing)
1) Visual question answering

-입력으로는 Image stream과 Question stream을 받는다.
-텍스트의 시퀀스는 RNN으로, 이미지는 CNN을 통해 처리한다. 그리고 같은 차원의 벡터로 출력한다.
-그렇게 각 모델에서 나온 특징들은 Point-wise multiplication을 통해 (일종의 Joint 임베딩) 상호연관성이 있도록
만든 후 완전연결층으로 보낸다.
-모든 학습의 과정은 End-to-end로 이루어진다.
Multi-modal tasks - Visual data & Audio
Sound의 표현 방식
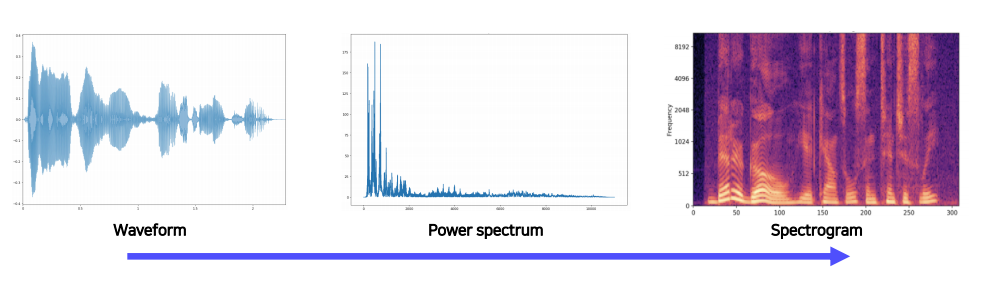
-원래의 데이터는 1D 시그널로 주어지게 된다.
-하지만 ML의 입력 데이터로 사용하기 위해서는 어쿠스틱 특징으로 변환이 필요하다. (스텍토그램, MFCC 등)
*acoustic feature : 음성 소리의 종류를 급성, 중대성 또는 확산으로 정의하는 음향 특성.
-스텍토그램으로 변환하는 방식 : Fourier transform
-Short-time Fourier transform (STFT) 방식으로 작동한다.
-짧은 윈도우 구간 내에서만 FT를 적용하는 방식
-짧은 윈도우 구간에 대해서 해밍 윈도우를 곱하여 가운데를 강조하고 바깥을 약화시킨다.
-이렇게 하면 스펙트럼의 변화를 더 확실하게 표현이 가능하다.
-윈도우와 윈도우를 조금 겹치게 (오버랩되게) 구성한다.

-Fourier Transform (푸리에 변환)

-입력 신호를 다양한 주파수를 갖는 주기함수들의 합으로 분해하여 표현한다.
-즉, 입력 신호를 다양한 주파수 내역의 sin, cos 함수들로 분해하는 것이다.

-위의 그래프에서 주기함수들을 모두 합하면 원래의 입력신호가 나온다.
-푸리에 변환은 신호의 주파수 성분을 알 수 있게 해준다.
-어쿠스틱 특징들을 잘 파악할 수 있는 방법이다.
Spectogram

-시간 축에 따른 스펙트럼의 스택이다.
-파형과 스펙트럼의 특징이 조합되어 있는데,
파형은 시간의 변화에 따른 진폭의 변화를 볼 수 있고,
스펙트럼에서는 주파수의 변화에 따른 진폭의 변화를 볼 수 있다.
-이 둘을 합친 스펙트럼은 시간과 주파수의 변화에 따른 진폭의 차이를 색상과 농도를 통해 확인할 수 있다.
Joint Embedding (Matching)
1) Scene recognition by sound
-소리를 듣고 해당하는 장면을 생성하는 것.
-대표적으로 2016년에 발표된 SoundNet이 있다.
-SoundNet은 오디오의 표현을 어떤 식으로 학습할 것인가에 대한 방법론을 제시한다.

-레이블이 없는 비디오를 Visual Recognition Networks에 넣어줌으로써 하나는 객체를 식별하고, 다른 하나는
장면을 식별한다.
-그리고 오디오는 별도로 추출하여 1d cnn을 통해 두 개의 헤드로 나누어 객체와 장면 식별에 KL Diverse로 매칭한다.
-학습 자체는 오디오 측에서만 일어난다. 비디오 식별은 사전 학습 모델을 사용하기 때문.
-즉 teacher- student 모델과 유사하다.
-위 모델의 특징은 오디오 데이터를 별도로 전처리 하지 않고 Raw Waveform을 사용했는데, 이는 Raw Waveform을
사용하면 더 성능이 좋아서 그런 것이 아니라, 그냥 바꿀 생각을 하지 않은 것으로 추측된다.
-만약 해당 모델을 학습시켜 다른 모델에 적용 시 Pool5의 특징을 뽑아서 사용하면 된다.
-저 부분이 Sound를 표현하는 학습된 대표적인 특징이 나오는 부분이기 때문.
-저 뒤부터는 두 개의 헤드로 나누어지는 과정이기 때문.
-저 부분의 특징을 가지고 나와 다른 분류기에 넣으면 된다.
Cross model translation
1) Speech2Face

-음성을 듣고 얼굴을 만들어내는 네트워크
-Waveform 형태의 오디오를 스펙토그램으로 바꾸어 인코더에 넣어주면 얼굴을 생성하는 모델
-모델의 학습을 위해서 Module network 구조를 사용한다.
-Module network 구조는 사전 학습된 모델들을 적재적소에 잘 배치하여 조합하는 방식
-Joint embedding learning을 응용한 사례이며, 자가 학습 모델.
*자가 학습 모델 (Self-supervised Trainig) : 라벨이 없는 데이터에 기존 모델로 라벨을 붙여주고,
그 데이터로 학습하는 모델. (Day 31에 있음)
2) Image-to-speech synthesis
-이미지를 입력하면 소리를 만들어주는 모델

-이미지가 들어오면 ResNet을 통해 14*14 특징맵으로 추출한다.
-그 후 Show, Attend, and Tell에서 사용한 구조를 활용한다.
-이 때 output은 sub-word-unit이라는 natural language가 아닌 중간 형태의 토큰으로 생성해준다.
-그리고 Unit-to-Speech Model (TTS)를 통해 유닛을 스피치로 변환한다.

-모델들의 중간에서 유닛들이 잘 호환될 수 있도록 유도한다.
-무슨 소리인지 도저히 이해가 안됨.
Cross model reasoning
1) Sound source localization

-이미지와 오디오를 넣었을 때 이미지의 어떤 부분에서 해당 오디오가 추출되었는지 추출해주는 작업.
-CNN을 통해 이미지 데이터를 식별하고, SoundNet과 같이 CNN을 토대로 한 모델로 오디오를 식별한다.

-VisualNet과 AudioNet을 통해 각자의 특성을 파악하여 AttentionNet으로 넘겨준다.
-AttentionNet은 두 개의 특성맵을 내적하며 관계성을 파악한후 Localization score를 출력한다.
-그리고 그렇게 나온 Localization Score가 맞는지 검사하기 위해서 Supervised Learning을 수행한다.
-비디오는 항상 오디오를 가지고 있기에 Unsupervised Learning도 가능하다.
-내적을 통해 나온 Localization Score와 VisualNet의 특징맵을 weighter sum pooling해서 Attended visual
feature을 추출한다.
-해당 특징과 오디오넷의 특징을 metric learning을 하면 파악한 이미지에서 해당 오디오가 나왔는지 아닌지를
판별할 수 있다.
Image Captioning Practice (실습)
-주어진 이미지에 대한 설명을 생성하는 작업.
-이미지 캡셔닝 구조는 CNN으로 이루어진 인코더와, RNN으로 이루어진 디코더로 나뉜다.
인코더

-CNN이 출력하는 특징맵의 크기를 미리 정의한 상태여야 편하다. (encoded_image_size)
-위의 인코더는 사전 학습된 ResNet-101을 사용한다.
-단, 그래도 활용하지 않고 마지막 두 개의 레이어 (완전 연결층들을)를 잘라 공간 정보를 유지한 특징 맵을 추출한다.
-해당 모델을 다시 Sequential한 모델로 변경하여 사용한다.
디코더의 동작 과정

-추출한 특징맵을 디코더인 RNN에 넣어준다.
-위의 예시는 RNN 중에서도 attention 모듈을 사용한 예시이다.
-첫 입력에서 특징맵과 start token을 입력으로 넣어주면 히든 스테이트 벡터 h(t)와 이전 레이어의 출력값, 이전
레이어의 어텐션 정보를 함께 넣어주며 연속으로 예측이 이루어진다.

-RNN의 특성상 이전 출력을 입력으로 받기에 중간에 잘못된 단어가 예측되면 이후의 예측은 전부 잘못된 것일 수 밖에
없다.
-이를 방지하기 위해 Beam Search를 사용한다.
-Beam Search는 하이퍼 파라미터 k를 가지는데, 각 단계에서 k개의 가장 높은 점수의 경우의 수를 남기는 방법이다.
-위의 예시에서 첫 단계에서 가장 높은 스코어를 받은 an, a, oh가 추출되었다. 다음 단계에서 각 단어들의 다음 예측
k개를 선별하여, k^2개의 경우의 수를 예측하고, 가장 점수가 높은 k개의 문장만을 선택하고 나머지는 삭제한다.
-이런 방식으로 계속해서 이어나가며 최종적으로 여러 개의 출력값을 내놓게 되고, 그 중 가장 점수가 높은 문장을
선택하여 최종 출력값으로 선택한다.
-이러한 방법은 탐욕법이기는 하지만, 어느 정도의 여지를 남겨둠으로써 모델의 출력을 다양하게 만들고,
잘못된 예측의 확률을 줄여준다.
3D Understanding
-AI, CV 분야에서 3D가 중요한 이유는 우리가 사는 실세계가 3D이기 때문이다.
-AI가 실세계에서 완벽하게 작동하기 위해서 실세계의 공간인 3D를 이해해야만 한다.
-3D는 AR/VR, 3D 프린팅, 의학 등에서 활발하게 사용되고 있다.
The way we observe 3D

-이미지는 3D가 아닌, 2D에 투영된 것이다.
-3D와 2D는 빛 또는 각도를 통한 직선의 관계가 있는데, 이를 활용하여 3D로 변환할 수 있다.
-그 방법은 다양한 각도에서 찍은 사진들을 교차하여, Triangulation이라는 겹치는 포인트를 찾는 것이다.
-위와 같은 2-view 외에도 n-view가 가능한데, 그건 밑의 책을 참고하자.
*Multi View Gepmetry in computer vision
*난이도가 높으니 수학 공부 먼저하자.
컴퓨터에서 3D를 표현하는 방식

-2D 이미지는 단순하게 W*H*(RGB)로 컴퓨터 상에서 표현이 가능하다.
-하지만 3D의 표현은 단순하지 않다. 그리고 그 방법은 하나가 아니라 다양한 방법이 있다.
1) Multi-view images : 다양한 방향과 각도에서의 이미지를 파악한다.
2) Volumetric (voxel) : 2D이미지와 가장 비슷한 표현 방법.
3D 공간을 격자로 나누어, 3D 객체를 그래프 상에 0, 1로 표시한다.
3) Part assembly : 기본적인 도형들의 집합으로 표현 => 위의 경우 6개의 서로 다른 사각형
4) Point cloud : 3D 상의 포인트들의 집합으로 표현 => (x, y, z) * n
5) Mesh (Graph CNN) : 여러 가지 Mesh 중 Triangle Mesh가 가장 흔하게 사용됨.
(x,y,z)로 표현되는 3D 포인터들을 삼각형으로 이어가며 그래프로 그림을 표현
6) Implicit shape : 흔하게 사용되지 않았지면 최근 들어 곽광받고 있음.
3D를 고차원의 함수로 표현하고, 해당 함수가 0과 교차하는 부분들을 추출하면 3D가 표현된다.
3D Dataset
1) ShapeNet

-55 카테고리로 이루어진 51,300개의 가상의 3D 이미지 데이터셋
2) PartNet

-ShapeNet의 보완된 버전
-Fine-grained 데이터셋이다.
-객체에 대한 주석이 포함된 데이터셋이라는 이야기인데, ShapeNet과 달리 각 객체들을 부품 단위로 세분화하고
각 부품에 대한 전문적인 주석을 달았다.
-26,671개의 데이터셋으로 이루어져 있고, 573,585개의 부품으로 구분할 수 있다.
-디테일이 나누어져 있기 때문에 Segmentation에 사용하기 좋다.
3) SceneNet

-500만 개의 RGB-Depth 실내 이미지들이다.
-시뮬레이션 데이터를 RGB와 Depth로 렌더링해서 가지고 있는 데이터셋
-랜덤하게 렌더링해서 가구들이 난잡하게 배열되어 있다.
4) ScanNet

-250만 개의 RGB-Depth 데이터셋
-SceneNet과 달리 시물레이션 데이터가 아니라 실제 데이터이다.
-조금 깨진 부분들이 존재하는데, 스캔이 되지 않은 부분들이다. (실제 데이터라서)
5) Outdoor 3D Scene datasets

-위에서 소개한 데이터 셋들은 인도어 데이터 셋이고, 아웃도어에 대한 3D 데이터셋들은 다음과 같다.
-대부분은 무인 자동차를 위한 데이터셋들이다.
5-1) KITTI : LiDAR 데이터이고 3D 바운드 박스로 라벨링이 되어있다.
5-2) Semantic KITTI : LiDAR 데이터이고, 각 포인트마다 라벨링이 되어있다.
5-3) Waymo Open Dataset : LiDAR 데이터이고 3D 바운드 박스로 라벨링이 되어있다.
*LiDAR (라이다) : 레이저를 이용하여 거리를 측정하여 정확한 x, y, z를 추출하는 기술
3D Task
-CNN을 활용해 2D 이미지를 처리하는 것과 마찬가지로, 3D 이미지에 대해서도 여러 작업 수행이 가능하다.
3D Object Recognition

-Classification 작업.
-Volumetric CNN을 통해 3D 이미지에 대한 분류를 수행한다.
3D Object Detection

-Detection 같은 경우에는 무인 자동차 분야에서 유용하게 사용되며, 3D 이미지 속 객체들의
위치를 탐지하는 기술이다.
3D Semantic segmantation

-3D 이미지에 대한 각 부분들을 식별한다.
Conditional 3D Generation Task
-Generitive 모델까지는 아니고, 입력 이미지를 바탕으로 3D를 만들어 주는 작업.
Mesh R-CNN

-3D Generation Task에 사용되는 알고리즘으로, 2D 이미지를 입력받으면 객체의 위치를 찾아 3D로 만들어준다.
-Mesh R-CNN은 Mask R-CNN의 수정 버전이다.
-기존의 Mask R-CNN은 아래와 같았다.

-Mask R-CNN은 box, box에 대한 class, mask 세 개의 branch로 이루어져 있다.
-각 branch는 output을 추론할 때 하나의 ROI를 공유하며 그 특징으로부터 각각의 출력을 예측한다.
-Mesh R-CNN에는 Mask R-CNN에서 3D branch가 추가된 구조이다.

-3D branch는 객체를 3D로 mesh한다.
More complex 3D Reconstruction models
-3D 객체를 여러 문제로 분해하며 더 정교한 3D를 구성하기 위한 방법으로 더 많은 3D Reconstuction models들이
있다.

-2D 이미지가 주어지면 Multi-task head CNN을 이용해 DEPTH, 실루엣, 서피스 노말을 추출한 후 합성을 통해 3D
이미지를 만들게 된다.
-이러한 sub-problem들은 물리적으로 의미가 있는 분리를 수행하는 형태이다.

-또 다른 방법으로는 RGB 이미지에 대해 Depth를 표현하고, 이 Depth를 Spheical Map으로 바꾸어준다.
-이는 물체의 중앙에서 방사형 방향으로 바라보는 형태라 보이지 않는 부분들이 존재한다.
-보이지 않는 부분들을 채워준 후 3D Space로 옯겨 3D로 구성한다.
3D application example (실습)
Defocusing a photo using depth map
-Depth map을 통해 이미지의 초점을 맞추는 것.
-핸드폰에 내장된 기능이다. (portrait mode in camera app)
-Depth map은 Depth Sensor나 NN으로 추정이 가능하다.

1) Focus를 맞추고 싶은 Depth_threshold의 범위인 [D_{min}, D_{max}]를 결정한다.

-D_{min} ~ D_{max}를 제외한 모든 이미지의 포커스를 날리겠다는 의미.
-이 예제에서 D_{min}은 고려하지 않는다. => 맨 앞에 Focus를 줄거라 min을 정하는 의미가 없음.
2) Depth map을 thresholding해서 mask를 만든다.

-즉, max를 넘어가는 영역은 defocusing area, max 내의 영역은 focusing area로 나눈다.
-위의 코드는 논리식을 이용해 각 이미지 픽셀을 True (1)와 False (0)로 나누어준다.
3) 입력 이미지에 대한 블러 버전으로 만든다.

-depth에 따라 만들 수도 있고, 그냥 블러 필터로 만들 수도 있다.
-커널 사이즈가 높아질수록 블러가 심해져서 모자이크처럼 된다.
4) Masked focused image와 Masked defocused image를 생성한다.

-이미지에서 focus_mask는 focus를 둘 픽셀에 1을, 아닌 픽셀에 0을 두니까 focus를 둘 픽셀을 제외한
모든 픽셀을 0으로 만들어버린다. 즉, focus 부분을 제외한 모든 부분을 없애버린다.
5) 위에서 생성한 두 이미지를 섞어 refocused image를 생성한다.

-덧셈 연산으로 0인 부분에 서로의 이미지가 채워짐으로 이미지가 완성된다.
'BOOSTCAMP AI TECH > 7주차_Computer Vision' 카테고리의 다른 글
| [BOOSTCAMP AI TECH] 34일차_Instance/Panoptic segmentation (0) | 2021.03.11 |
|---|---|
| [BOOSTCAMP AI TECH] 33일차_Object Detection, CNN Visualization (0) | 2021.03.10 |
| [BOOSTCAMP AI TECH] 32일차 (0) | 2021.03.09 |
| [BOOSTCAMP AI TECH] 31일차_Image classification (0) | 2021.03.08 |



