Instance segmentation

-물체의 class뿐 아니라 같은 class의 각 객체까지 식별 가능한 모델
Mask R-CNN


-R-CNN과 구조 자체는 비슷하다.
-다만 차이점으로 RoI Align이라는 풀링 레이어를 제안했다.
-R-CNN의 RoI 풀링은 정수 좌표에서만 특징을 추출할 수 있었다.
-하지만 RoI Align은 보간법을 통해 정교화된 subpixel (소수점 픽셀 레벨)의 풀링을 지원한다.
-즉, 소수 좌표에서도 특징을 추출할 수 있게 되었다.
-이를 통재 정교화된 특징을 추출할 수 있게 되었고 성능이 향상되었다.
-기존 Faster R-CNN에서는 풀링된 특징 위에 올라가있던 헤더가 두 개였다.
-Mask R-CNN에서는 기존의 헤더 옆에 Mask branch를 추가했다.
-Mask branch는 14*14로 업샘플링을 하고 채널 수를 256개로 줄였다. 이후 클래스의 개수로 채널 수를
맞추게 되는데, 각 클래스별로 Binary classification을 통해 해당 클래스가 존재하는지 아닌지를 식별한다.
-하나의 바운딩 박스에 대하여 일괄적으로 모든 클래스에 대한 마스크를 전부 생성한다.
그리고 classfication head에서 클래스가 어떤 곳에 모일 것이라는 예측 결과를 이용해
어떤 mask를 참조할 지 결정한다.
-이렇게 참조함으로써 마스크 중 하나를 골라 사용하고 최종 마스크를 반환한다.
YOLACT (You Only Look At CoefficienTs)

-Mask R-CNN과 달리 Single stage 구조이다.
-Real time으로 semantic segmentation이 가능한 single stage network이다.
-특징 피라미드 구조를 사용한다. 고해상도 특징맵을 사용할 수 있다.
-가장 큰 특징은 마스크의 프로토타입을 추출해 사용한다는 것이다.
프로토 타입에서는 마스크는 아니지만 마스크를 합성해낼 수 있는 기본적인 여러 물체의 soft segmentation
components들을 생성할 수 있다.
-즉, 마스크는 아니지만 마스크로 합성될 수 있는 재료들을 제공하는 것이다.
-이후 prediction head에서는 각 detection에 대해 protonet에서 나온 프로토 타입들을 잘 합성하기 위한 Coeffients
(계수)들을 출력해준다.
-그리고 계수들과 프로토타입들을 선형 결합해준다. 각 detection에 적합한 mask response map을 생성해준다.

-위의 예시에서 Detection1은 사람을, Detection2는 라켓을 검출하는 경향이 있다.
-이 프로토 타입들에 계수들을 곱한 (여기서는 덧셈/뺄셈으로 표현)후 더해서 최종적인 Detection Response map
을 만든다.
-여기서 mask를 효율적으로 생성하기 위해서는 프로토 타입 갯수를 객체 갯수에 맞추지 않아도 된다.
-적당하게 작게 설정하는 대신 선형결합으로 다양한 마스크를 생성하는 것이 포인트이다.
YolactEdge

-YOLACT는 빠르지만 소형으로 동작하는 모델은 아니었다.
-그래서 소형화되어 동작하기 위해 YolactEdge가 등장했다.
-YolactEdge는 이전 프레임 중 key 프레임에 해당하는 특징을 다음 프레임으로 전달해 특징맵의 계산량을 획기적으로
줄였다.
-따라서 소형화된 모바일에서도 빠르게 동작 가능하다.
Panoptic segmentation

-기존 Instance Segmentation은 배경에는 관심이 없고 움직이는 물체에만 관심을 가졌다.
-따라서 Instance Segmentation은 배경을 추출하지 않았다.
-Panoptic segmentation은 배경 정보 뿐 아니라 관심을 가질만한 물체의 인스턴스까지 추출해준다.
UPSNet
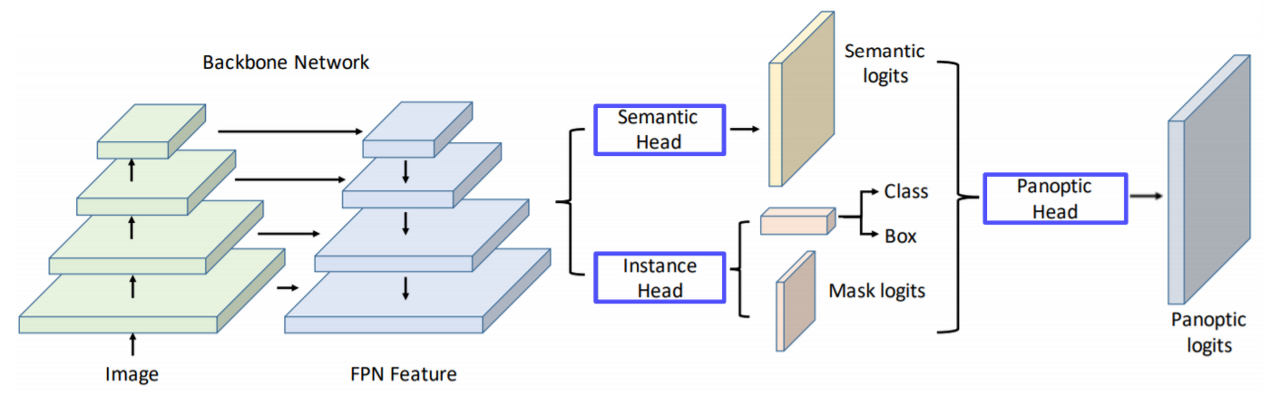
-FPN 구조를 사용하고 head branch를 여러 개로 나눈 구조이다.
-Semantic Head는 FCN 구조로 되어있어 Semantic prediction을 하게 된다.
-Instance Head는 물체의 Detection과 마스크의 logit을 추천하는 작업을 담당한다.
-Panoptic Head는 개별적인 작업들을 모아준다.
-자세히 표현하면 다음과 같다.

VPSNet

-VPSNet은 두 시간차를 가지는 영상 사이에 모션 맵을 사용한다.
-각 프레임에서 나온 특징맵을 모션에 따라 랩핑을 해주게 된다.
-모션맵은 한 영상의 점이 다음 t+1에서 어디로 가는지 (모든 픽셀에 대해) 대응 관계를 가지고 있다.
-즉 t-r에서 추출한 특징을 모션맵을 사용해 현재 타겟 프레임인 t로 옮겨준다.
-그 후 원래 타겟 특징(파란색)과 랩핑된 특징(노란색)을 합쳐준다.
-이렇게 함으로써 타겟 특징에서 추출된 특징만으로 대응하지 못하거나 보이지 않게 가려졌던 부분들을
이전 프레임에서 빌려온 특징 덕분에 더욱 높은 탐지 성공률을 자랑한다.
-다음으로는 Trak head를 통해 기존 ROI들과 현재 ROI들이 어떻게 서로 연관되었는지 연관성을 업로드한다.
-나머지는 UPS와 동일하다.
Landmark localization
-얼굴이나 사람의 pose를 측정하고 트랙킹하는데 사용된다.
-즉 얼굴이나 사람의 몸통 등 특정 물체에 대해 중요하다고 생각하는 특징부분(랜드마크)를 정의하고 추적한다.
-Landmark localization은 Heatmap classification을 사용한다.
-따라서 Landmark localization을 가우시안 히트맵으로 변환하기 위해 다음의 과정이 필요하다.

Hourglass Network

-Landmark 구조에 딱 맞춘 구조이다.
-이미지의 해상도를 작게 만들어, 즉 Receptive field를 크게 만들어 이를 기반으로 랜드마크를 찾는 방법이다.
-Receptive field를 크게 만들어 큰 영역을 보면서도 Skip connection을 통해 low level을 참조해 정확한
위치를 특정하게끔 유도한다.
-이후 스택을 여러 번 쌓아서 detail을 구체화해나가며 결과를 개선한다.

-Hourglass 부분을 확대해보면 UNet과 비슷한 구조를 가짐을 알 수 있다.
-다른 점은 UNet은 합치는 과정에서 Concat을 활용하지만 Hourglass는 덧셈을 사용한다. 그래서 차원이 늘지는 않지만
SKIP시에 또다른 합성곱 레이어를 통과하며 전달된다.
DensePose

-신체 모든 부위에 대해서 dense한 Landmark를 수행한다.
-신체 모든 부위에 대해서 Landmark를 알게되면 3D를 알게되는 것과 마찬가지이다.
-위의 사진과 같은 표현법은 UV map이라고 한다.
-UV Map : 표준 3D 모델의 각 부위를 2D로 펼쳐서 UV 좌표 내에 이미지 형태로 만들어놓은 표기법
-UV의 한 점은 3D mesh에서 한 점에 1:1로 대응되는데, 따라서 UV Map은 변화하지 않는다.
-따라서 영상에서의 트래킹이 가능하다.
-DensePose의 구조는 Mask R-CNN과 비슷하다.
-DensePose는 Faster R-CNN에 3D surface regression branch를 추가로 도입해서 만들어졌다.

-위의 patch 부분은 몸의 각 파트의 segmentation 부분이다.
RetinaFace

-기본 FPN 구조에 분류, 회귀, 랜드마크, 3d face 등 다양한 작업을 출력하는 네트워크
-Multi-task를 사용하면 백본 네트워크가 더 강하게 학습된다. 다양한 작업에 대해 여러 기울기가
백본 네트워크로 역전파되기에 많은 상황에 대처 가능한 네트워크가 만들어지기 때문
Detecting objects are key points
-바운딩 박스가 아닌 키포인트의 형태로 감지하는 방법들
CornerNet

-바운딩 박스가 Top-left, Bottom-right 두 개의 점으로 결정되는 방법
-백본 네트워크에서 나온 특징 맵에서 여러가지 헤드를 통해 Heatmap에서 두 개의 코너 점을 추출한다.
-그 후 임베딩 맵(각 포인트가 가진 정보를 표현한 헤드)를 통과하며 같은 객체끼리 같은 임베딩을
출력하게 만든다.
-그리고 임베딩 매칭을 통해 페어 형태로 bounding box를 추출한다.
CenterNet

-CornetNet에서 Center 점을 추가한 구조
Further Question
(1) Mask R-CNN과 Faster R-CNN은 어떤 차이점이 있을까요? (ex. 풀고자 하는 task, 네트워크 구성 등)
- Faster R-CNN에서는 ROI Pooling을 통해서 정수 좌표만을 지원했던 반면에, Mask R-CNN에서는 ROIAlign을 통해서 실수 좌표도 지원했다.
- Mask R-CNN = Faster R-CNN + Mask branch
(2) Panoptic segmentation과 instance segmentation은 어떤 차이점이 있을까요?
- Instance segmentation : 배경에는 관심이 없으며, 움직이는 물체에만 관심이 있었다.
- Semantic segmentation : 배경에도 관심이 있으나, 개체들을 구분할 수 없다.
- Panoptic segmentation : 배경에도 관심이 있으며, 개체들을 구분할 수 있다.
(3) Landmark localization은 human pose estimation 이외의 어떤 도메인에 적용될 수 있을까요?
- Facial landmark localization
- Landmark localization (= keypoint estimation): Predicting the coordinates of keypoints.
'BOOSTCAMP AI TECH > 7주차_Computer Vision' 카테고리의 다른 글
| [BOOSTCAMP AI TECH] 35일차_Multi-modal (0) | 2021.03.12 |
|---|---|
| [BOOSTCAMP AI TECH] 33일차_Object Detection, CNN Visualization (0) | 2021.03.10 |
| [BOOSTCAMP AI TECH] 32일차 (0) | 2021.03.09 |
| [BOOSTCAMP AI TECH] 31일차_Image classification (0) | 2021.03.08 |



