1) Why was CNN developed?

CNN이전에는 DNN (Deep Neural Networks)가 주로 사용되었다.
하지만 DNN은 1차원 형태의 데이터를 입력값으로 받는 모델로, 2차원 이상의 데이터를 입력값으로 사용하는 경우 반드시 1차원으로 평탄화하는 Flatten 작업이 필요했다.
이미지와 같은 현실 세계의 데이터는 Flatten 작업시 이미지의 공간적, 지역적 정보의 손실이 일어난다. 위의 사진을 보면 이해가 빠를 것이다.
그리고 이러한 손실은 정보 부족을 야기하여 비효율적이고 비정확한 학습을 유도할 수 있다.
*컬러 이미지의 픽셀은 3차원 데이터 (R,G,B), SHAPE은 (height, width, 3)
*흑백 이미지의 픽셀은 1차원 데이터 (R,G,B), SHAPE은 (height, width, 1)
이러한 DNN의 한계에서 벗어나기 위해 CNN이 개발되었다.
CNN은 각 레이어의 입출력 데이터의 형상을 유지하는 형태라 Flatten 작업이 필요없다. 그리고 이에 따라 이미지의 공간 정보의 유지가 가능하고, 복수의 필터를 활용하는 방식으로써 효과적인 이미지의 특징 추출 및 학습이 가능해졌다.
2) Structure of CNN

CNN은 사진과 같이 크게 6개의 구조로 구성되어 있다.
- Input Layer에서는 raw_data를 입력받는다.
- Convolution Layer에서는 필터를 활용해 이미지의 특징을 추출한 특징맵을 만든다.
- Pooling Layer에서는 추출된 특징맵을 축소해 연산 횟수를 줄인다.
- Fully Connected Layer에서는 여러 번의 합성곱과 풀링 과정을 거쳐 식별한 특징들을 신경망에 넣어 분류한다. 이 때 Fully Connected Layer는 DNN 방식이기 때문에 Flatten이 필요하다.
- Dropout Layer는 뉴럴 네트워크가 학습 중일 때 랜덤하게 뉴런을 생략하며 학습을 진행한다.
- Output Layer는 softmax 함수를 사용해 Classification을 진행한다.
위에서 언급했듯 Fully Connected Layer은 DNN과 별반 다를 바가 없다.
그렇기에 CNN에서 개인적으로 가장 중요하다 생각되는 부분은 특징을 추출하는 합성곱층과 연산을 축소하는 풀링층이다.
2-1) Structure of CNN : Convolution Layer

합성곱층은 입력받은 데이터를 순회하며 특징 맵을 출력하는 레이어이다. 필터를 통해 불필요한 정보를 걸러내고 중요한 신호만을 추출하여 패턴을 추출한다.
필터는 이미지의 특징을 찾아내기 위한 파라미터이다. 자주 사용되는 필터로는 sobel-x와 sobel-y가 존재한다.
기존에는 프로그래머가 명시적으로 필터를 지정해야 했다고 들었다.
하지만 CNN의 합성곱 단계에서는 랜덤으로 초기화한 필터를 사용하며, 학습을 거듭하며 알아서 특성에 맞게 조정된 필터를 사용한다. 즉, 프로그래머가 더 이상 필터를 명시해야 할 필요가 없어졌다.
필터는 여러 개를 사용할 수 있으며, n개의 필터를 사용할 경우 n개의 특징맵 채널을 생성한다.
필터의 크기와 Stride (움직이는 간격)의 크기에 따라 특징 맵의 크기가 변화한다.
처음에는 저수준의 특징맵이 생성되고, Convolution이 반복될수록 저수준의 특징맵을 입력받아 고수준의 특징맵이 생성된다.
tflearn에서 conv_2d를 사용하는 법은 다음과 같다.
| tflearn.conv_2d(incoming, nb_filter, filter_size, strides=1, padding='same', activation='linear') tflearn.conv_2d(tflearn.input_data(shape = [None, 20, 20, 1], name = 'input'), 10, 3, activation = 'tanh', padding = 'same') |
|
| incoming | 입력 데이터의 형식 |
| nb_filter | 필터의 수 |
| filter_size | 필터의 크기 (int or list) |
| strides | 이동 값 (기본 1) |
| padding | 패딩 (same : 같은 크기 행렬 출력, valid : 패딩 안함) |
| activation | 활성화 함수 결정 |
*자주 사용하는 파라미터만 남겼을 뿐, 실제로는 훨씬 많은 파라미터가 존재한다.
*2는 2차원 데이터를 의미한다. 1d, 3d, 4d 도 존재한다.
*http://tflearn.org/layers/conv/#convolution-2d
2-2) Structure of CNN : Pooling Layer

풀링층은 합성곱층에서 생성된 특징맵의 크기를 줄여 매개 변수를 줄이는 과정이다.
이러한 작업은 특징맵마다 독립적으로 수행된다. 이러한 작업은 지정된 영역에서 가장 특징적인 부분만을 남기기 때문에 계산 복잡도가 줄어들고, 오버피팅이 방지된다는 이점이 생긴다.
풀링의 방식은 여러 개가 존재하지만, 대표적으로 Max Pooling, Average Pooling이 사용된다.
*Max Pooling : 가장 큰 값만 챙기고 이외의 값은 버린다. 중요한 Feature의 값은 크게 나올 수 밖에 없다는 점을 이용했다.
*Average Pooling : 각 영역의 평균을 계산한다.
| tflearn.max_pool_2d (incoming, kernel_size, strides = None, padding = 'same') tflearn.avg_pool_2d (incoming, kernel_size, strides = None, padding = 'same') tflearn.avg_pool_2d( feature_map, 2, strides = 2, padding = 'valid') |
|
| incoming | 입력 데이터의 형식 (특징맵) |
| kernel_size | 커널 사이즈 (int or list) |
| strides | 이동 값 (미입력시 kernel_size) |
| padding | 패딩 설정 (same, valid) |
2-2) Structure of CNN : Dropout Layer
드롭아웃 레이어를 알기 위해서는 오버피팅의 개념을 알아야 한다.
오버피팅은 모델이 너무 학습 데이터에만 맞게 학습되어 현실 세계의 데이터를 제대로 판별할 수 없는 경우를 뜻한다.
예를 들자면, 농구공을 중점적으로 학습 시킨 모델에 사과 사진을 넣으면 색이 비슷하고 모양이 비슷하다는 이유로 농구공을 출력할 수 있다.
이러한 오버피팅을 막기 위해서는 여러 가지 방법들이 존재하는데, 그 중 대표적인 방법 중 하나가 Dropout Layer을 활용하는 것이다.
Dropout Layer에서는 학습이 진행중인 신경망에서 랜덤한 뉴런들을 꺼버린다.
이러한 과정으로 인해서 정해진 하나의 모델이 아니라, 여러 가지 모델들이 완성된다. 그리고 각 모델들을 통합하여 최종적으로는 하나의 모델이 생성한다.
여러 모델을 합쳐 하나의 모델로 만듬으로써, 집단지성을 이용한 학습을 한다. 하나의 모델이 판단을 하는 것이 아닌 여러 모델들이 각자 판단을 하고, 다수결의 원칙에 의해 많은 투표를 받은 판단을 정답으로 인식하여 출력하는 방식이다.
Dropout이 장점만 있는 것은 아닌데, 대표적인 단점으로 신경망의 학습 속도가 느려질 수 있다. 이럴 때는 배치 정규화를 구현하여 드롭아웃을 진행하면 학습 속도가 증가한다.
*드롭아웃은 최종적으로 하나의 모델을 만들기에 여러 모델을 만드는 앙상블 학습과는 다르다.
*배치 정규화 : 활성화 함수의 활성화 값 또는 출력 값을 평균이 0, 분산이 1이 되도록 정규화 한다.
*배치 정규화시 오버피팅이 해결과도, 경사도 손실 문제가 해결되며, 매번 출력값에 정규화를 하기에 초기 가중치 의존도가 떨어진다. 그리고 빠른 학습이 가능해진다.
3) Models of CNN
이미 많은 CNN 모델들이 세상에 출시되었다. 그러나 나 또한 그랬던 것처럼 CNN을 처음으로 접하는 학생이라면 대부분은 여섯 개의 CNN 모델들을 학습하고 시작을 한다.
하지만 DenseNet과 GoogleNet은 제외하고, 나머지 모델들만 설명하겠다.
3-1) Models of CNN - LeNet-5

LeNet-5는 CNN을 처음으로 개발한 Yann Lecun 연구팀이 1988년에 개발한 알고리즘이다.
가장 널리 알려진 신경망이기도 하다.
Structure
LeNet-5의 구조는 입력값, 3개의 합성곱층, 2개의 서브샘플링층(풀링층), 1개의 완전연결층과 1개의 출력층으로 구성되었다. 각 층별 설명은 다음과 같다.
| 층명 | 층 유형 | 필터 크기 | 이동 거리 | 활성화함수 | 맵 크기 | 맵 개수 |
| | 입력 | - | - | - | 32 x 32 | 1 |
| C1 | 콘볼루션 | 5 x 5 | 1 | tanh | 28 x 28 | 6 |
| A1 | 풀링(평균) | 2 x 2 | 2 | tanh | 14 x 14 | 6 |
| C2 | 콘볼루션 | 5 x 5 | 1 | tanh | 10 x 10 | 16 |
| A2 | 풀링(평균) | 2 x 2 | 2 | tanh | 5 x 5 | 16 |
| C3 | 콘볼루션 | 5 x 5 | 1 | tanh | 1 x 1 | 120 |
| F1 | 완전연결 | - | - | tanh | 84 | - |
| F2 | 완전연결 | - | - | RBF | 10 | - |
-C1 : 입력데이터를 6개의 5*5 필터와 컨볼루션 연산을 해 6개의 28*28 특성 맵 출력
-S2 : 6개의 28*28 특성 맵에 서브샘플링을 진행하여 14*14 특성맵으로 축소 (2*2 필터, 2 STRIDE 사용)
-C3 : 6개의 14*14 특성 맵에 컨볼루션 연산을 수행해 15개의 10*10 특성 맵 출력
-S4 : 16개의 10*10 특성 맵에 서브샘플링을 진행해 16장의 5*5 특성 맵으로 축소
-C5 : 16개의 5*5 특성 맵을 120개 5*5*16 사이즈의 필터와 컨볼루션. 120개의 1*1 특성맵 산출
-F6 : 84개의 유닛을 가진 신경망으로, C5의 결과를 각 유닛에 연결
-OUTPUT : 10개의 RBF 유닛들로, 각각 F6의 84개 유닛으로부터 인풋을 받아 이미지가 속한 클래스 출력
LeNet-5는 활성화 함수로 Tahn 함수가 적용되었고, 풀링으로는 평균 풀링을 활용했다.
*Euclidean Radial basis function (RBF) : 방사형 구조를 기본으로 하는 네트워크. 1개의 은닉층에 확률 가우시안이 적용된다.
Code
import tflearn
# 학습 데이터 적재
import tflearn.datasets.mnist as mnist
X, Y, testX, testY = mnist.load_data(one_hot=True)
X = X.reshape([-1, 28, 28, 1])
testX = testX.reshape([-1, 28, 28, 1])
# LeNet-5 구성
network = tflearn.input_data(shape=[None, 28, 28, 1], name='input')
network = tflearn.conv_2d(network, 6, 5, activation='tanh', padding='same')
network = tflearn.avg_pool_2d(network, 2, strides=2, padding='valid')
network = tflearn.conv_2d(network, 16, 5, activation='tanh', padding='valid')
network = tflearn.avg_pool_2d(network, 2, strides=2, padding='valid')
network = tflearn.conv_2d(network, 120, 5, activation='tanh', padding='valid')
network = tflearn.fully_connected(network, 84, activation='tanh')
network = tflearn.fully_connected(network, 10, activation='softmax')
network = tflearn.regression(network, optimizer='adam', learning_rate=0.01,
loss='categorical_crossentropy', name='target')
# 학습
model = tflearn.DNN(network, tensorboard_verbose=0)
model.fit({'input': X}, {'target': Y}, n_epoch=20, validation_set=({'input': testX}, {'target': testY}),
snapshot_step=100, show_metric=True, run_id='convnet_mnist')
개인적으로 학습을 시켜본 결과, 층의 개수가 적고 완전연결층에서의 노드의 개수가 적은 덕분에 확실히 빠른 학습이 가능했다. 하지만 출시된 지 오래된 모델인 탓에 좋은 정확도를 빠르게 달성하지는 못했다.
3-2) Models of CNN - AlexNet
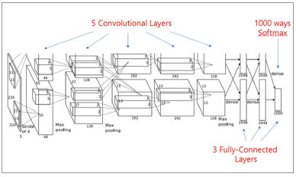
AlexNet은 ILSVRC 2012 대회에서 우승을 차지한 캐나다의 토론토 대학팀의 모델이다. 논문의 첫 저자명인 Alex Khrizevsky의 이름을 따 AlexNet이라 명명했다.
구조적 관점에서는 LeNet-5와 크게 다르지 않다. 하지만 성능 향상을 위해 여러 가지를 요소들이 추가되었다.
일단 LeNet-5에 비해 층의 수가 더 깊어졌다. 또한 컨볼루션층과 풀링층이 번갈아 오지 않고, 컨볼루션층이 연속적으로 나오는 구조가 되었다.
마지막에는 한 개의 완전연결층이 아닌 세 개의 완전연결층으로 구성했는데, 각각 4096, 4096, 1000개의 뉴런으로 구성했다. 이 덕분에 더 정확성이 높아졌지만, 더 많은 학습시간이 소요된다.
또한 AlexNet은 LeNet-5가 Tanh 함수를 사용한 것에 대해 ReLU함수를 사용했다. ReLU 함수는 Tanh 함수와 같은 정확도를 보이나 6배 가량 빠름이 입증되었다.
과적합을 막기 위해 드롭아웃을 사용하기 시작했으며, Overlapping pooling과 Data Augmentation을 사용했다.
그리고 GPU를 활용해 좋은 효과를 보였다. 2개의 GPU를 병렬적으로 사용해 학습을 진행했고, 이는 이후의 CNN 개발자들이 모델 개발에 GPU를 활용하게 하는 계기가 되었다.
*Overlapping pooling : stride를 커널 사이즈보다 작게 함으로써 중복해서 풀링을 진행하는 것.
*Data Augmentation : 하나의 이미지를 활용해 미러링, 자르기 등으로 여러 학습 이미지를 만드는 것.
Structure
| 층명 | 층 유형 | 필터 크기 | 이동거리 | 패딩 | 활성화함수 | 맵 크기 | 맵 개수 |
| | 입력 | - | - | - | - | 227 x 227 | 3 |
| C1 | 콘볼루션 | 11 x 11 | 4 | valid | relu | 55 x 55 | 96 |
| M1 | 풀링(max) | 3 x 3 | 2 | valid | - | 27 x 27 | 96 |
| C2 | 콘볼루션 | 5 x 5 | 1 | same | relu | 27 x 27 | 256 |
| M2 | 풀링(max) | 3 x 3 | 2 | valid | - | 13 x 13 | 256 |
| C3 | 콘볼루션 | 3 x 3 | 1 | same | relu | 13 x 13 | 384 |
| C4 | 콘볼루션 | 3 x 3 | 1 | same | relu | 13 x 13 | 384 |
| C5 | 콘볼루션 | 3 x 3 | 1 | same | relu | 13 x 13 | 256 |
| M3 | 풀링(max) | 3 x 3 | 2 | valid | - | 6 x 6 | 256 |
| F1 | 완전연결 | - | - | - | relu | 4096 | - |
| F2 | 완전연결 | - | - | - | relu | 4096 | - |
| F3 | 완전연결 | - | - | - | softmax | 1000 | - |
Code
import tflearn
import tflearn.datasets.oxflower17 as oxflower17
X, Y = oxflower17.load_data(one_hot=True, resize_pics=(227, 227))
# 망 구성
network = tflearn.input_data(shape=[None, 227, 227, 3])
network = tflearn.conv_2d(network, 96, 11, strides=4, activation='relu', padding='valid')
network = tflearn.max_pool_2d(network, 3, strides=2, padding='valid')
network = tflearn.local_response_normalization(network)
network = tflearn.conv_2d(network, 256, 5, activation='relu', padding='same')
network = tflearn.max_pool_2d(network, 3, strides=2, padding='valid')
network = tflearn.local_response_normalization(network)
network = tflearn.conv_2d(network, 384, 3, activation='relu', padding='same')
network = tflearn.conv_2d(network, 384, 3, activation='relu', padding='same')
network = tflearn.conv_2d(network, 256, 3, activation='relu', padding='same')
network = tflearn.max_pool_2d(network, 3, strides=2, padding='valid')
network = tflearn.local_response_normalization(network)
network = fully_connected(network, 4096, activation='tanh')
network = dropout(network, 0.5)
network = fully_connected(network, 4096, activation='tanh')
network = dropout(network, 0.5)
network = fully_connected(network, 17, activation='softmax')
network = regression(network, optimizer='momentum',
loss='categorical_crossentropy', learning_rate=0.001)
# 학습
model = tflearn.DNN(network, checkpoint_path='model_alexnet',
max_checkpoints=1, tensorboard_verbose=2)
model.fit(X, Y, n_epoch=1000, validation_set=0.1, shuffle=True,
show_metric=True, batch_size=64, snapshot_step=200,
snapshot_epoch=False, run_id='alexnet_oxflowers17')
3-3) Models of CNN - VGGNet
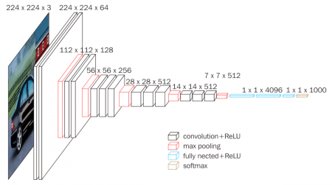
VGGNet은 ILSVRC 2014에서 준우승한 모델이다. 해당 대회에는 GoogleNet이 우승을 거머쥐었는데, 오히려 우승한 GoogleNet보다 VGGNet이 더 각광을 받았다.
이유라면 GoogleNet은 너무 어렵기 때문이다.
그에 반해 VGGNet은 구글넷보다 훨씬 간단한데, 그렇기에 코드를 이해하기 쉽고 변형이 좋아 구글넷보다 많이 사용된다.
VGGNet은 AlexNet과 유사하다. 하나 혹은 여러 개의 컨볼루션층 이후에 풀링층이 온다는 점이나, 끝단에 각각 4096, 4096, 1000개의 노드를 탑재한 완전연결층이 온다는 점이 유사하다.
하지만 AlexNet과의 차이점도 당연히 존재하는데, 알렉스넷의 경우 8레이어인데 반해 VGGNet은 그것보다 깊어졌고 컨볼루션에 사용되는 필터를 3*3 사이즈로 고정한 것이다.
그러나 학습을 진행하다보면 3*3 사이즈의 필터 외 다른 사이즈의 필터를 사용해야 하는 경우가 생길 수 있다. 그럼에도 VGGNet이 3*3 필터를 고집하는 것은 해당 필터를 겹치면 다른 사이즈의 필터 효과를 주기 때문이다. 이론적으로 3*3 필터 세 개를 쌓으면 5*5 필터의 효과가 나고, 세 개를 쌓으면 7*7의 효과가 일어난다.
그리고 이렇게 큰 필터를 사용하는 것보다 작은 필터를 겹쳐서 사용하게 된다면 패러미터의 수를 줄여 빠른 학습이 가능해지고, 층의 개수가 깊어져 선형성이 증가해 더 유용한 특징 추출의 가능성이 높다.
*VGGNet은 층의 깊이에 따라 VGG-11, 13, 16, 19로 구분된다.
*층의 갯수는 합성곱층과 완전연결층만 셈한다.
*세 개의 완전연결층으로 인해 알렉스넷과 마찬가지로 학습 속도가 느리다.
Structure
| 층명 | 층 유형 | 필터 크기 | 이동거리 | 패딩 | 활성화함수 | 맵 크기 | 맵 개수 |
| | 입력 | - | - | - | - | 224 x 224 | 3 |
| C1 | 콘볼루션 | 3 x 3 | 1 | same | relu | 224 x 224 | 64 |
| C2 | 콘볼루션 | 3 x 3 | 1 | same | relu | 224 x 224 | 64 |
| M1 | 풀링(max) | 2 x 2 | 2 | same | - | 112 x 112 | 64 |
| C3 | 콘볼루션 | 3 x 3 | 1 | same | relu | 112 x 112 | 128 |
| C4 | 콘볼루션 | 3 x 3 | 1 | same | relu | 112 x 112 | 128 |
| M2 | 풀링(max) | 2 x 2 | 2 | same | - | 56 x 56 | 128 |
| C5 | 콘볼루션 | 3 x 3 | 1 | same | relu | 56 x 56 | 256 |
| C6 | 콘볼루션 | 3 x 3 | 1 | same | relu | 56 x 56 | 256 |
| C7 | 콘볼루션 | 3 x 3 | 1 | same | relu | 56 x 56 | 256 |
| C8 | 콘볼루션 | 3 x 3 | 1 | same | relu | 56 x 56 | 256 |
| M3 | 풀링(max) | 2 x 2 | 2 | same | - | 28 x 28 | 256 |
| C9 | 콘볼루션 | 3 x 3 | 1 | same | relu | 28 x 28 | 512 |
| C10 | 콘볼루션 | 3 x 3 | 1 | same | relu | 28 x 28 | 512 |
| C11 | 콘볼루션 | 3 x 3 | 1 | same | relu | 28 x 28 | 512 |
| C12 | 콘볼루션 | 3 x 3 | 1 | same | relu | 28 x 28 | 512 |
| M4 | 풀링(max) | 2 x 2 | 2 | same | - | 14 x 14 | 512 |
| C13 | 콘볼루션 | 3 x 3 | 1 | same | relu | 14 x 14 | 512 |
| C14 | 콘볼루션 | 3 x 3 | 1 | same | relu | 14 x 14 | 512 |
| C15 | 콘볼루션 | 3 x 3 | 1 | same | relu | 14 x 14 | 512 |
| C16 | 콘볼루션 | 3 x 3 | 1 | same | relu | 14 x 14 | 512 |
| M5 | 풀링(max) | 2 x 2 | 2 | same | - | 7 x 7 | 512 |
| F1 | 완전연결 | - | - | - | relu | 4096 | - |
| F2 | 완전연결 | - | - | - | relu | 4096 | - |
| F3 | 완전연결 | - | - | - | softmax | 1000 | - |
Code
Import tflearn
import tflearn.datasets.oxflower17 as oxflower17
X, Y = oxflower17.load_data(one_hot=True)
# Building 'VGG Network'
input = tflearn.input_data(shape=[None, 227, 227, 3])
c1= tflearn.conv_2d(input, 64, 3, activation='relu')
c2= tflearn.conv_2d(c1, 64, 3, activation='relu')
m1 = tflearn.max_pool_2d(c2, 2, strides=2)
c3 = tflearn.conv_2d(m1, 128, 3, activation='relu')
c4 = tflearn.conv_2d(c3, 128, 3, activation='relu')
m2 = tflearn.max_pool_2d(c4, 2, strides=2)
c5 = tflearn.conv_2d(m2, 256, 3, activation='relu')
c6 = tflearn.conv_2d(c5, 256, 3, activation='relu')
c7 = tflearn.conv_2d(c6, 256, 3, activation='relu')
m3 = tflearn.max_pool_2d(c7, 2, strides=2)
c8 = tflearn.conv_2d(m3, 512, 3, activation='relu')
c9 = tflearn.conv_2d(c8, 512, 3, activation='relu')
c10 = tflearn.conv_2d(c9, 512, 3, activation='relu')
m4 = tflearn.max_pool_2d(c10, 2, strides=2)
c11 = tflearn.conv_2d(m4, 512, 3, activation='relu')
c12 = tflearn.conv_2d(c11, 512, 3, activation='relu')
c13 = tflearn.conv_2d(c12, 512, 3, activation='relu')
m5 = tflearn.max_pool_2d(c13, 2, strides=2)
f1 = tflearn.fully_connected(m5, 4096, activation='relu')
d1 = tflearn.dropout(f1, 0.5)
f2 = tflearn.fully_connected(d1, 4096, activation='relu')
d2 = tflearn.dropout(f2, 0.5)
f3 = tflearn.fully_connected(d2, 17, activation='softmax')
network = tflearn.regression(f3, optimizer='rmsprop', loss='categorical_crossentropy',
learning_rate=0.0001)
# 학습
model = tflearn.DNN(network, checkpoint_path='model_vgg',
max_checkpoints=1, tensorboard_verbose=0)
model.fit(X, Y, n_epoch=500, shuffle=True, show_metric=True, batch_size=32, snapshot_step=500, snapshot_epoch=False, run_id='vgg_oxflowers17')
3-4) Models of CNN - ResNet

ResNet은 ILSVRC 2015에서 우승한 모델이다. GoogleNet에 비해 2배 가량 향상된 정확도를 보여주었다.
ResNet은 층의 깊이가 매우 깊다. VGGNet이 19층이고, GoogleNet이 20층인데 반해 ResNet은 152층이나 된다. 그런데 모델에서 층이 많다고 학습 효과가 좋은 것이냐? 그건 또 아니다.
일반 신경망층은 층이 깊어질수록 출력이 0인 층들이 생겨 역전파 학습 시 이 층들의 가중치가 변경되지 않는 현상이 발생한다. 이는 학습의 정확도를 떨어뜨리는 요인이 된다.
조금 쉽게 설명하자면 시험으로 예를 들자. 시험범위가 입력값으로 주어지면 학습을 통해 범위 내의 중요한 것들을 기억해낸다. 그런데 학습이 너무 길다면? 더 확실하게 기억하는 것들도 존재하겠지만, 오히려 망각하거나 다른 유사한 개념과 혼동되어 헷갈리는 것들이 발생할 수 있다.
층이 깊어진다는 것은 이와 마찬가지이다. 층이 깊어지면 깊어질수록, 오히려 기억하고 있던 특징들이 사라질 수 있다.

ResNet은 이러한 문제점을 알기에, 층을 깊게하는 대신 잔차 유닛 (Residual Unit)을 발명했다.
잔차 유닛은 입력과 출력층이 skip connection으로 연결되어 있다. 결국 입력값을 토대로 얻은 학습값에 원래의 입력값을 그대로 갖고 있는 꼴이다.
위의 예시로 들자면, 학습을 통해 얻은 기억 외에도 시험에 교과서까지 그대로 들고가는 셈이 된다.

추가로 ResNet-34 이후에 등장한 ResNet-50, 101, 152는 잔차 유닛이 아닌 Bottleneck 유닛을 활용했다.
BottleNet 유닛은 3*3 네트워크를 1*1, 3*3, 1*1 세 개의 층으로 변형한 것이다.
처음 1*1 층은 입력의 차원을 감소시켜 채널 수를 줄인다. 그리고 3*3 층에서 연산을 한 다음 1*1 층에서 채널을 복구시킨다. 이러한 과정은 연산 시간 감소의 효과를 준다.
Structure

Code
import tflearn.datasets.mnist as mnist
X, Y, testX, testY = mnist.load_data(one_hot=True)
X = X.reshape([-1, 28, 28, 1])
testX = testX.reshape([-1, 28, 28, 1])
# 잔차 네트워크 구성
net = tflearn.input_data(shape=[None, 28, 28, 1])
net = tflearn.conv_2d(net, 64, 3, activation='relu', bias=False)
# 잔차 블록
net = tflearn.residual_bottleneck(net, 3, 16, 64)
net = tflearn.residual_bottleneck(net, 1, 32, 128, downsample=True)
net = tflearn.residual_bottleneck(net, 2, 32, 128)
net = tflearn.residual_bottleneck(net, 1, 64, 256, downsample=True)
net = tflearn.residual_bottleneck(net, 2, 64, 256)
net = tflearn.batch_normalization(net)
net = tflearn.activation(net, 'relu')
net = tflearn.global_avg_pool(net)
net = tflearn.fully_connected(net, 10, activation='softmax')
net = tflearn.regression(net, optimizer='momentum',
loss='categorical_crossentropy', learning_rate=0.1)
# 학습
model = tflearn.DNN(net, checkpoint_path='model_resnet_mnist',
max_checkpoints=10, tensorboard_verbose=0)
model.fit(X, Y, n_epoch=100, validation_set=(testX, testY),
show_metric=True, batch_size=256, run_id='resnet_mnist')
'IT 지식 > 인공지능_딥러닝' 카테고리의 다른 글
| [논문] DenseNet (0) | 2021.03.07 |
|---|---|
| [논문] ResNet (0) | 2021.03.02 |
| [논문] AlexNet (0) | 2021.02.27 |
| 자연어 처리 : 트랜스포머 (0) | 2021.02.22 |



