옛날부터 궁금한게 한 가지 있었다.
예를 들어, 한 테이블의 col1, col2 칼럼에 동시에 인덱스를 걸어놓았다.
이 떄 인덱스는 따로따로가 아니라 동시에 걸어놓는다.
무슨 말이냐 하면,

위 사진처럼 하나의 인덱스당 하나의 컬럼을 거는 것이 아니라,
아래의 사진처럼 하나의 인덱스에 두 개의 컬럼을 묶어놓는 식이다.
그리고 col2 칼럼을 기준으로 CRUD 쿼리를 실행시키면 과연
"Index가 정상적으로 작동할까?"
궁금한 건 못참으니, 한 번 테스트를 해볼까 한다.
참고로 MariaDB 11.2.2 를 사용했다.
테이블, 프로시저 생성 및 초기 데이터 입력
우선 테이블을 생성한다.
각 테이블은 동일하게 9개의 INT 컬럼으로 구성되어 있으며, 서로 다른 인덱스를 설정해 다섯 개의 테이블을 생성했다.
- 인덱스가 걸려있지 않음
- (col1, col2)로 인덱스가 걸림
- col2에만 인덱스가 걸림
- (col2, col1)로 인덱스가 걸림 (순서변경)
- col1, col2에 따로 인덱스가 걸림
테이블 생성을 위한 쿼리는 아래와 같다.
DROP TABLE IF EXISTS test_tbl_no_index;
DROP TABLE IF EXISTS test_tbl_index1;
DROP TABLE IF EXISTS test_tbl_index2;
DROP TABLE IF EXISTS test_tbl_index3;
DROP TABLE IF EXISTS test_tbl_index4;
CREATE TABLE IF NOT EXISTS test_tbl_no_index (
col1 INT,
col2 INT,
col3 INT,
col4 INT,
col5 INT,
col6 INT,
col7 INT,
col8 INT,
col9 INT
);
CREATE TABLE IF NOT EXISTS test_tbl_index1 (
col1 INT,
col2 INT,
col3 INT,
col4 INT,
col5 INT,
col6 INT,
col7 INT,
col8 INT,
col9 INT,
INDEX idx_col1_col2_1 (col1, col2)
);
CREATE TABLE IF NOT EXISTS test_tbl_index2 (
col1 INT,
col2 INT,
col3 INT,
col4 INT,
col5 INT,
col6 INT,
col7 INT,
col8 INT,
col9 INT,
INDEX idx_col2_2 (col2)
);
CREATE TABLE IF NOT EXISTS test_tbl_index3 (
col1 INT,
col2 INT,
col3 INT,
col4 INT,
col5 INT,
col6 INT,
col7 INT,
col8 INT,
col9 INT,
INDEX idx_col2_col1_3 (col2, col1)
);
CREATE TABLE IF NOT EXISTS test_tbl_index4 (
col1 INT,
col2 INT,
col3 INT,
col4 INT,
col5 INT,
col6 INT,
col7 INT,
col8 INT,
col9 INT,
INDEX idx_col1_4 (col1),
INDEX idx_col2_4 (col2)
);
그리고 테스트를 위해서는 꽤 많은 데이터를 넣어주어야 하는데, 일일이 넣기는 귀찮으므로, 프로시저를 생성한다.
아래 프로시저는 1,000,000 개의 데이터를 넣어주는 프로시저이다.
*테이블별 Insert 시간을 보기 위해 모든 테이블이 아니라 개별 테이블에 실행할 수 있도록 코드를 작성했다.
DELIMITER //
CREATE PROCEDURE insert_data(IN table_name VARCHAR(255))
BEGIN
DECLARE i INT DEFAULT 1;
WHILE i <= 1000000 DO
SET @col_val = i;
SET @query = CONCAT('INSERT INTO ', table_name, ' (col1, col2, col3, col4, col5, col6, col7, col8, col9) VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?)');
PREPARE stmt FROM @query;
EXECUTE stmt USING @col_val, @col_val, @col_val, @col_val, @col_val, @col_val, @col_val, @col_val, @col_val;
DEALLOCATE PREPARE stmt;
SET i = i + 1;
END WHILE;
END;
//
DELIMITER ;
프로시저가 생성되었다면 아래 명령어로 각 테이블에 데이터를 넣어준다.
CALL insert_data('테이블명');
각 테이블에 1,000,000 개씩 데이터를 삽입했다. 그러나 index를 걸고 안걸고와 무관하게 insert 성능 차이는 크지 않았다.
이유라면 insert가 순차적이기에 데이터를 중간에 추가하는 것이 아니라 마지막에 추가되어 인덱스 재구성 및 유지 관리 비용이 상대적으로 작기 때문이다. 특히 인덱스 유형을 별도로 걸지 않았기에 인덱스가 B-Tree로 생성되었고, 이로 인한 영향이 커서 인덱스의 유무에 따른 insert 차이가 크지 않았다.
SELECT 실험
초기 데이터가 생성되었으니 CRUD를 차례대로 테스트해서 성능 차이를 확인해보자.
우선 SELECT이다. 무작위로 세 개의 숫자를 정해 = 과 IN 연산을 수행해보았다.
SELECT * FROM 테이블명 WHERE col2=95325;
SELECT * FROM 테이블명 WHERE col2 IN (93123, 23405);
실행 결과는 아래와 같다.
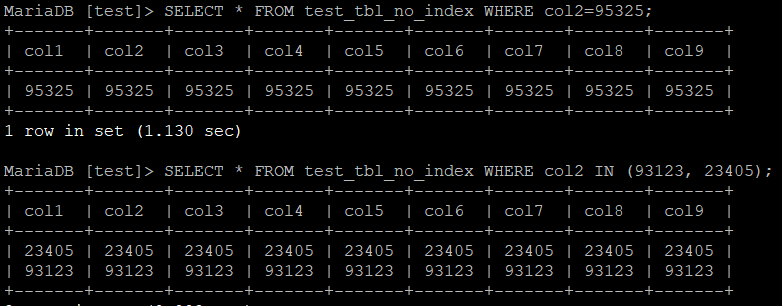
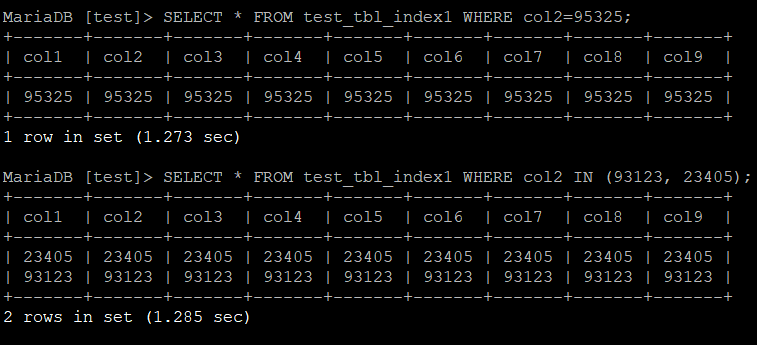
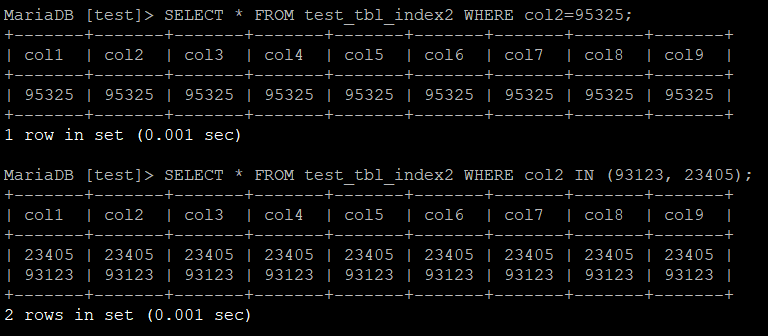
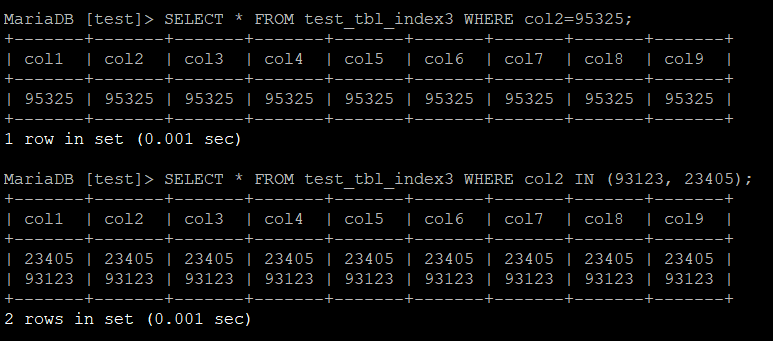
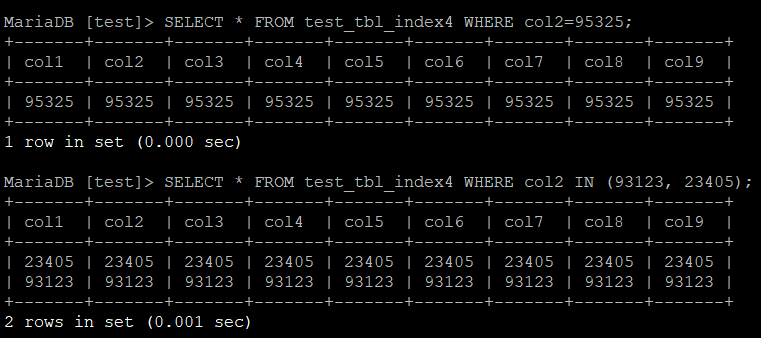
결과는 아래와 같이 집계되었다.
| 인덱스 유형 | 인덱스 없음 | (col1, col2) | col2 | (col2, col1) | col1, col2 |
| 개별 SELECT | 1.130 | 1.273 | 0.001 | 0.001 | 0.000 |
| 다중 SELECT | 0.883 | 1.285 | 0.001 | 0.001 | 0.001 |
col2가 단독으로 Index가 걸린 세 번째와 다섯 번째는 확실히 유의미한 차이를 보여주었다.
그리고 col2가 복합 인덱스의 앞 순서에 온 네 번째도 유의미한 차이를 보여주었다.
그에 반해 col2가 복합 인덱스의 뒷 순서에 온 두 번째 테이블은 크게 인덱스의 효과를 볼 수 없었다.
이 결과를 통해 index를 통한 WHERE 연산에서 복합 인덱스는 순서에 따라 그 속도가 달라짐을 확인할 수 있었다.
DELETE 실험
사실 SELECT 실험에서 WHERE에 대한 시간 차이가 입증되었으므로 DELETE 실험은 의미는 없지만 이왕 시작한 김에 나머지 연산들에 대한 실험도 진행해보자.
마찬가지로 세 개의 임의의 숫자를 정해 DELETE를 수행하고 연산시간을 비교해보았다.
DELETE FROM 테이블명 WHERE col2=74153;
DELETE FROM 테이블명 WHERE col2 IN (14563, 532);
아래는 결과이다.





마찬가지로 결과를 종합해보자
| 인덱스 유형 | 인덱스 없음 | (col1, col2) | col2 | (col2, col1) | col1, col2 |
| 개별 DELETE | 1.066 | 1.421 | 0.003 | 0.004 | 0.002 |
| 다중 DELETE | 1.076 | 1.413 | 0.003 | 0.002 | 0.002 |
INSERT 실험
다음은 INSERT이다. 방금 전 삭제한 데이터에 추가로 다양한 col1, col2 조합을 INSERT해보았다.
INSERT INTO 테이블명 VALUES (74153, 74153, 74153, 74153, 74153, 74153, 74153, 74153, 74153);
INSERT INTO 테이블명 VALUES
(14563, 14563, 14563, 14563, 14563, 14563, 14563, 14563, 14563),
(532, 532, 532, 532, 532, 532, 532, 532, 532);
INSERT INTO 테이블명 VALUES
(2, 53, 14563, 14563, 14563, 14563, 14563, 14563, 14563),
(68765, 79088, 532, 532, 532, 532, 532, 532, 532),
(68765, 23453, 532, 532, 532, 532, 532, 532, 532);
아래는 결과이다.
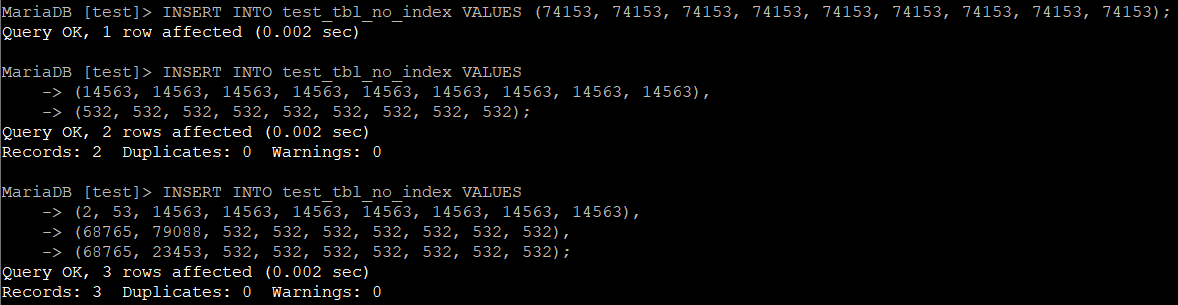
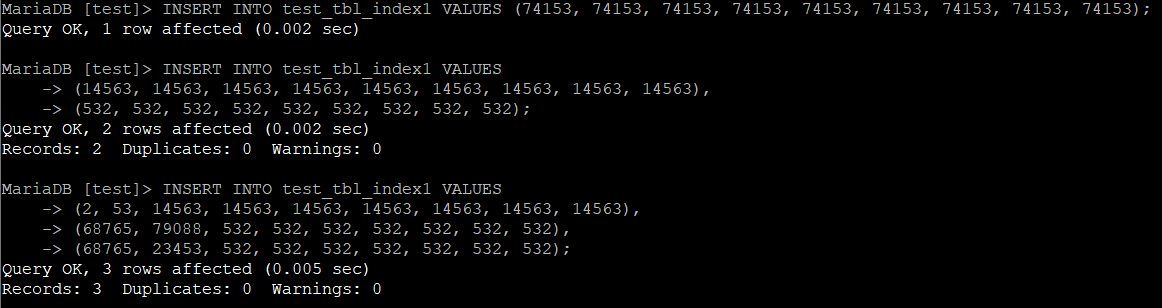
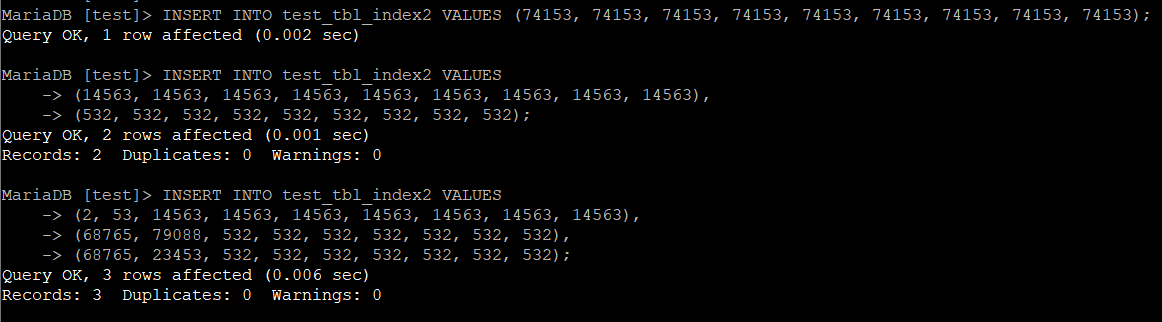
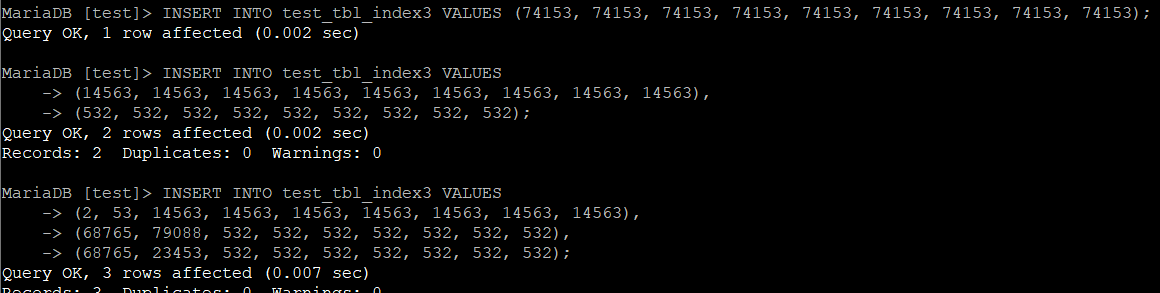
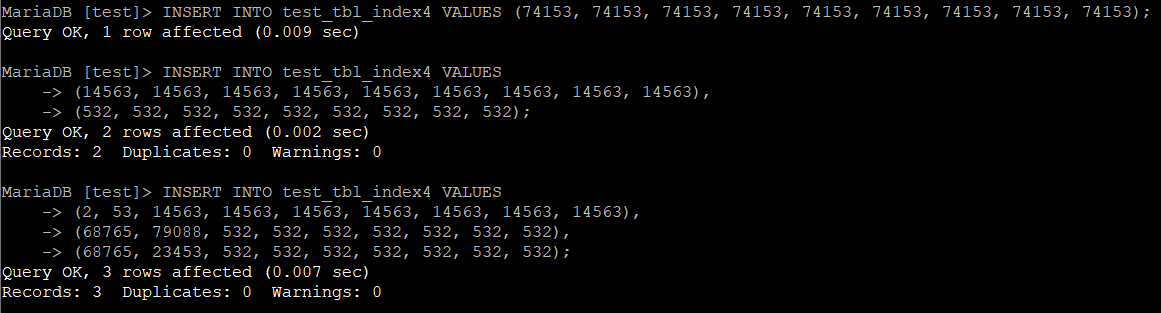
마찬가지로 결과를 집계하면 아래와 같다.
| 인덱스 유형 | 인덱스 없음 | (col1, col2) | col2 | (col2, col1) | col1, col2 |
| 개별 INSERT | 0.002 | 0.002 | 0.002 | 0.002 | 0.009 |
| 다중 INSERT 1 | 0.002 | 0.002 | 0.001 | 0.002 | 0.002 |
| 다중 INSERT 2 | 0.002 | 0.005 | 0.006 | 0.007 | 0.007 |
INSERT의 경우 두 개의 인덱스가 따로 걸린 다섯 번째 테이블이 확연히 낮은 성능을 보여주었다. 이를 토대로 인덱스의 갯수에 따라 INSERT의 시간 소요가 달라짐을 확인할 수 있다.
그리고 인덱스의 유무에 따른 시간 차이는 존재하지만, 인덱스를 어디에 어떻게 걸었느냐에 따른 명확한 차이는 존재하지 않았다.
물론 이는 pk도 없는 너무 간단한 테이블로 1,000,000개의 데이터밖에 넣지 않아 발생한 것일 수도 있고, 보다 복잡하고 많은 데이터로 실험을 한다면 유의미한 결과가 도출될 수 있다.
UPDATE 실험
마지막으로 UPDATE 실험도 해보았다.
UPDATE 테이블명
SET col1=41232
WHERE col2=98632;
UPDATE 테이블명
SET col1=92847
WHERE col2 IN (21345, 75349);
UPDATE 테이블명
SET col3=12345
WHERE col2 IN (952, 12958);
결과는 아래와 같다.
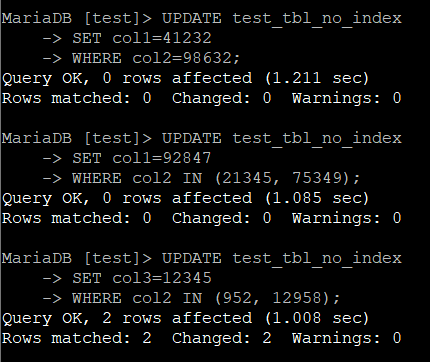
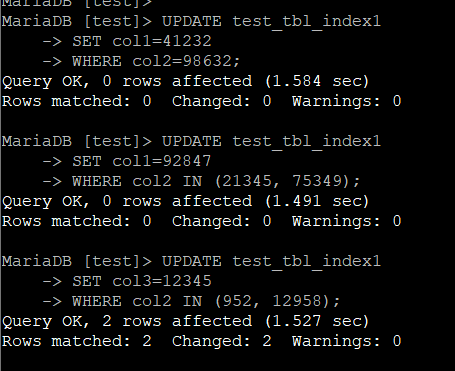
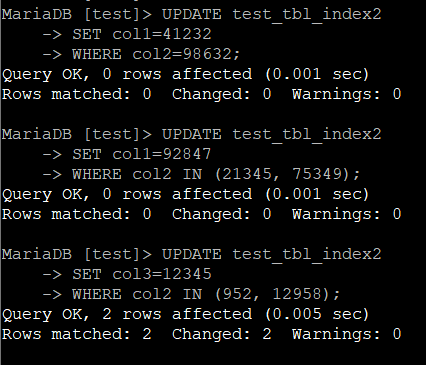
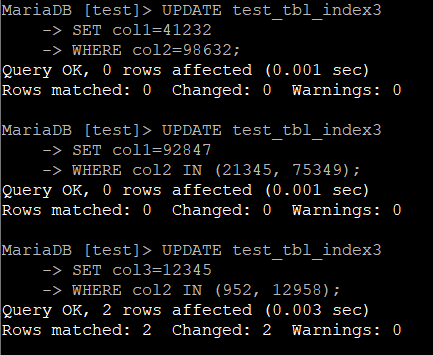
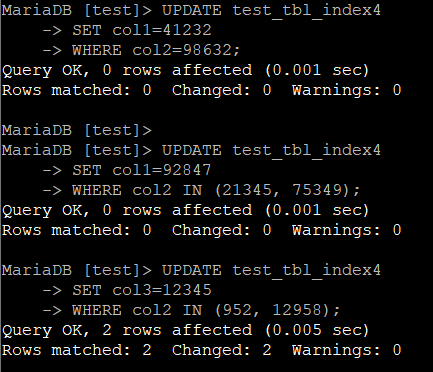
마찬가지로 결과를 집계하면 아래와 같다.
| 인덱스 유형 | 인덱스 없음 | (col1, col2) | col2 | (col2, col1) | col1, col2 |
| 개별 UPDATE | 1.211 | 1.584 | 0.001 | 0.001 | 0.001 |
| 다중 UPDATE 1 | 1.085 | 1.491 | 0.001 | 0.001 | 0.001 |
| 다중 UPDATE 2 | 1.008 | 1.527 | 0.005 | 0.003 | 0.005 |
UPDATE는 SELECT 후 데이터를 수정하고 이를 INDEX 기반으로 재배열을 수행한다. 고로 WHERE 절의 col2 기반 검색이 사용되어 SELECT, DELETE와 마찬가지로 col2 / (col2, col1) / col1, col2 인덱스가 좋은 성능을 보여주었다.
결론
두 개 이상의 컬럼을 하나의 인덱스로 묶어놓고 그 중 하나를 토대로 RUD 연산을 수행했을 때 해당 컬럼의 순서가 앞순서가 아니라면 큰 의미는 없다.
'IT 지식 > 데이터베이스' 카테고리의 다른 글
| ON DELETE(UPDATE) 옵션 (0) | 2024.01.10 |
|---|---|
| [PostgreSQL] 컬럼의 Length를 지정해야 하는 이유 (0) | 2023.07.05 |
| [DB] 격리수준 (0) | 2021.05.30 |
| [DB & BOOT] 트랜잭션 (0) | 2021.05.30 |
| [데이터베이스] JSON과 XML (0) | 2021.04.06 |


