N+1 문제
연관 관계가 설정된 엔티티 조회 시 조회된 데이터의 갯수(N)만큼 연관관계의 조회 춰리가 추가로 발생해서 데이터를 읽어오는 현상이다.
처음 이 말을 들었을 때 무슨 말인지 알지 못했다.
하지만 아래의 예시를 들면 이해가 편할 것 같다.
우선 아래와 같은 두 개의 테이블이 존재한다고 가정한다.

CREATE TABLE IF NOT EXISTS school (
school_name VARCHAR(100) PRIMARY KEY
);
CREATE TABLE IF NOT EXISTS student (
stdnt_name VARCHAR(100) PRIMARY KEY,
school_name VARCHAR(100) NOT NULL,
CONSTRAINT FK_SCHL FOREIGN KEY(school_name) REFERENCES school(school_name)
);
INSERT INTO school VALUES
('A'), ('B'), ('C');
INSERT INTO student VALUES
('김', 'A'), ('이', 'A'),
('박', 'B'), ('최', 'B'),
('정', 'C');
student 를 SELECT 해보자. SQL에서라면 그냥 단순하게 한 번의 SQL 만으로 데이터가 추출될 것이다.
SELECT * FROM student;
하지만 JPA에서라면 어떨까?
우선 위 두 개의 테이블에 대한 Domain 클래스와 Repository를 생성했다.
School.java
package com.mwlee.n1test.domain;
import java.util.ArrayList;
import java.util.List;
import javax.persistence.Entity;
import javax.persistence.FetchType;
import javax.persistence.Id;
import javax.persistence.JoinColumn;
import javax.persistence.OneToMany;
import javax.persistence.Table;
import lombok.AllArgsConstructor;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
import lombok.ToString;
@Entity
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
@Table(name="school")
@ToString
public class School {
@Id
private String schoolName;
@OneToMany(fetch = FetchType.EAGER)
@JoinColumn(name="school_name")
private List<Student> students = new ArrayList<>();
}Student.java
package com.mwlee.n1test.domain;
import javax.persistence.Entity;
import javax.persistence.FetchType;
import javax.persistence.Id;
import javax.persistence.JoinColumn;
import javax.persistence.ManyToOne;
import javax.persistence.Table;
import lombok.AllArgsConstructor;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
import lombok.ToString;
@Entity
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
@Table(name="student")
@ToString
public class Student {
@Id
private String stdntName;
@ManyToOne(fetch=FetchType.EAGER)
@JoinColumn(name="school_name")
private School school;
}SchoolRepository.java
package com.mwlee.n1test.repository;
import org.springframework.data.repository.CrudRepository;
import org.springframework.stereotype.Repository;
import com.mwlee.n1test.domain.School;
@Repository
public interface SchoolRepository extends CrudRepository<School, String>{
}StudentRepository.java
package com.mwlee.n1test.repository;
import org.springframework.data.repository.CrudRepository;
import org.springframework.stereotype.Repository;
import com.mwlee.n1test.domain.Student;
@Repository
public interface StudentRepository extends CrudRepository<Student, String> {
}
그리고 JPA가 실행한 SQL이 눈에 보이도록 application.properties에 설정을 추가했다.
spring.jpa.format_sql=true
spring.jpa.show-sql=true
이제 다음 Test를 만들어 돌려본다.
@Autowired SchoolRepository schoolRepo;
@Autowired StudentRepository stdntRepo;
@Transactional // LazyInitializationException 방지
@Test
void contextLoads() {
Iterator<School> itr = schoolRepo.findAll().iterator();
}
보다시피 일반 SQL에서는 한 번의 쿼리로 끝날 것을, N+1(4) 번의 쿼리를 실행해서 데이터를 가져오고 있다.
이 부분은 옛날에 구글링을 하던 중 FetchType을 LAZY로 지정하지 않아서 그렇다는 글을 본 적이 있다.
LAZY 로딩
객체가 실제로 필요할 때 DB에서 로딩되는 기법
그렇다면 FetchType을 LAZY로 두면 해결이 되는 문제일까?
두 도메인 클래스의 FetchType을 LAZY로 두고 실행을 시켜보자.


확실히 한 번의 쿼리만 날아감을 확인할 수 있다.
하지만 이는 정말 말 그대로 LAZY라서, 당장 필요하지 않아 Student 데이터를 부르지 않았을 뿐이다.
테스트 코드를 다음과 같이 고쳐 School 안의 Student를 일일히 호출해보자.
@Autowired SchoolRepository schoolRepo;
@Autowired StudentRepository stdntRepo;
@Transactional // LazyInitializationException 방지
@Test
void contextLoads() {
Iterator<School> itr = schoolRepo.findAll().iterator();
// 반드시 STUDENT를 한 번씩 불러오도록 수정
while(itr.hasNext()) {
School schl = itr.next();
for(Student stdnt : schl.getStudents()) {
log.info(stdnt.getStdntName());
}
}
}그리고 결과를 살펴보자.

결국 당장 쿼리를 호출하지 않을 뿐, 결국 데이터를 사용해야 하는 상황에는 쿼리를 불러오기에 N+1 번의 SQL이 일어나고 있다.
그렇다면 어떻게 해야할까?
얼마 전 이력서와 자기소개서 첨삭용으로 결제한 우리의 ChatGPT에게 물어보자.
*자기소개서 첨삭용으로 구매했는데, 내가 질문을 못하는건지 별로... 하지만 결제는 해버려서 돈이 아까우니 이렇게라도 써야지...

우리의 ChatGPT가 세 가지 방안을 제시해줬다.
이제 하나씩 한 번 해보자.
Join Fetch 이용
SchoolRepository에 @Query로 Join Fetch를 이용해 findAll 메소드를 직접 작성한다.
SchoolRepository.java
package com.mwlee.n1test.repository;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.CrudRepository;
import org.springframework.stereotype.Repository;
import com.mwlee.n1test.domain.School;
@Repository
public interface SchoolRepository extends CrudRepository<School, String>{
@Query("SELECT schl FROM School schl JOIN FETCH schl.students ")
Iterable<School> findAll();
}
확실히 한 번의 쿼리만을 이용했다.
하지만 이 방법은 앞서 ChatGPT도 언급했듯, 모든 데이터를 한 번에 가져오기에 데이터가 많은 상황에서는 적합하지 않다.
게다가 필요에 따라 FetchType을 Lazy로 해놓아야 할 때도 분명 존재한다. 하지만 Join Fetch는 설정한 Lazy 같은 것도 결국에는 무시하게 될 수 밖에 없다는 단점도 존재한다.
Batch Size 이용
@BatchSize 어노테이션을 이용하는 방법이다. 사용 방법은 어렵지 않다.
우선 아까 만든 FetchJoin findAll() 함수를 삭제하자.
SchoolRepository.java
package com.mwlee.n1test.repository;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.CrudRepository;
import org.springframework.stereotype.Repository;
import com.mwlee.n1test.domain.School;
@Repository
public interface SchoolRepository extends CrudRepository<School, String>{
/*
@Query("SELECT schl FROM School schl JOIN FETCH schl.students ")
Iterable<School> findAll();
*/
}
그리고 School.java 파일에서 @BatchSize를 추가한다.
School.java
package com.mwlee.n1test.domain;
import java.util.ArrayList;
import java.util.List;
import javax.persistence.Entity;
import javax.persistence.FetchType;
import javax.persistence.Id;
import javax.persistence.JoinColumn;
import javax.persistence.OneToMany;
import javax.persistence.Table;
import org.hibernate.annotations.BatchSize;
import lombok.AllArgsConstructor;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
import lombok.ToString;
@Entity
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
@Table(name="school")
@ToString
public class School {
@Id
private String schoolName;
@OneToMany(fetch = FetchType.LAZY)
@JoinColumn(name="school_name")
@BatchSize(size = 10) // 추가
private List<Student> students = new ArrayList<>();
}*ChatGPT는 클래스에 어노테이션을 붙였지만, 여기서는 students에 붙여야 한다.
참고로 @BatchSize 어노테이션은 하단의
이제 한 번 돌려보자.

두 번의 쿼리가 실행되었다.
그냥 사용할 때와 무슨 차이가 있고 하니,

일일히 조회하던 쿼리를 in 을 사용해서 한 번에 끝난 것이었다. 해당 방법으로 N+1번보다는 적은 쿼리를 통해 데이터를 조회할 수 있다.
그리고 당연한 말이지만, BatchSize의 설정에 유의해야 한다.
*BatchSize가 10이고 School의 수가 3이라 한 번의 쿼리가 추가 실행되었다. 이 말은 즉, School의 수가 11이라면 두 번의 쿼리가 추가 실행된다.
EntityGraph 이용
마지막으로 EntityGraph를 이용한 방법을 알아보자.
Fetch Join의 경우 Join문을 @Query에 넣어주었다. EntityGraph는 굳이 @Query안에 Join문을 넣지 않아도 알아서 Join을 해준다고 생각하면 된다.
설명하자니 왠지 복잡하게 작성했는데, 코드를 보면 이해가 될 것 같다.
School.java의 @BatchSize를 삭제한다.
School.java
package com.mwlee.n1test.domain;
import java.util.ArrayList;
import java.util.List;
import javax.persistence.Entity;
import javax.persistence.FetchType;
import javax.persistence.Id;
import javax.persistence.JoinColumn;
import javax.persistence.OneToMany;
import javax.persistence.Table;
import org.hibernate.annotations.BatchSize;
import lombok.AllArgsConstructor;
import lombok.Getter;
import lombok.NoArgsConstructor;
import lombok.Setter;
import lombok.ToString;
@Entity
@Getter
@Setter
@NoArgsConstructor
@AllArgsConstructor
@Table(name="school")
@ToString
public class School {
@Id
private String schoolName;
@OneToMany(fetch = FetchType.LAZY)
@JoinColumn(name="school_name")
//@BatchSize(size = 1) // 삭제
private List<Student> students = new ArrayList<>();
}
그리고 SchoolRepository.java에서 findAll을 아래와 같이 수정한다.
Fetch Join과의 비교를 위해 Fetch Join 문은 굳이 지우지 않았다.
ShoolRepository.java
package com.mwlee.n1test.repository;
import org.springframework.data.jpa.repository.EntityGraph;
import org.springframework.data.jpa.repository.Query;
import org.springframework.data.repository.CrudRepository;
import org.springframework.stereotype.Repository;
import com.mwlee.n1test.domain.School;
@Repository
public interface SchoolRepository extends CrudRepository<School, String>{
/*
@Query("SELECT schl FROM School schl JOIN FETCH schl.students ")
Iterable<School> findAll();
*/
// 위에서는 JOIN을 @Query 안에 넣었지만, @EntityGraph 사용 시 해당 부분이 생략된다.
@EntityGraph(attributePaths = "students")
@Query("SELECT schl FROM School schl")
Iterable<School> findAll();
}
그러면 이제 실행을 시켜보자.

한 번의 쿼리만이 실행되었음을 확인할 수 있다.
추가로 FetchJoin과의 차이점은 그냥 쿼리문을 안써도 되는 것 뿐인가? 라는 의문이 드는데, 쿼리문을 자세히 보면 EntityGraph는 left outer join을 사용했다.

그리고 FetchJoin은 inner Join을 사용했다.
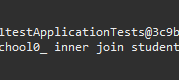
마지막으로 ChatGPT에게 두 가지 방법의 차이점과 장단점을 물어보며 포스팅을 끝마친다.

'실습 > 리눅스 서버 + 스프링 부트' 카테고리의 다른 글
| Spring Batch (0) | 2023.07.19 |
|---|---|
| OSIV (0) | 2023.07.14 |
| Spring Boot + Mybatis (0) | 2023.07.02 |
| Spring Boot + JSP (0) | 2023.07.02 |
| OAuth2.0 + Spring Boot (Google, Kakao, Naver 연동) (2) | 2023.07.01 |



