현재 재직중인 회사가 빅데이터를 주로 다루는 회사이다보니, 프로그램 구축이 끝나고난 후 해당 프로그램을 통해 모인 데이터를 데이터 마트에 옮겨주는 작업까지 해야할 일이 종종 생겼다.
지난 프로젝트에서는 위의 작업을 Hue UI 내에서 Oozie와 Sqoop, 그리고 Hive의 유틸인 Beeline과 직접 만든 java application을 이용해서 데이터 마트 적재 플로우를 구축했다. 하지만 이번 프로젝트에서는 Hue가 설치되어 있지 않아 위와 같은 방법을 사용할 수 없었다. 그래서 대신 NIFI를 이용해 데이터 마트를 구축하기로 결정했다.
nifi

nifi란 데이터 ETL 툴 중 하나로, 분산환경에서 대량의 데이터를 수집하기에 용이한 프로그램이다.
nifi는 실시간 처리에 적합하고, 웹 UI를 지원하기에 간편한 사용이 가능하다는 장점이 있다. 다만 배치작업의 효율이 떨어지고, 복잡한 연산이 불가능하다는 단점이 있다.
이번 프로젝트에서는 복잡한 연산은 굳이 필요하지 않고 단순하게 데이터를 퍼오기만 하면 되기에 nifi를 이용한 데이터 마트를 구축해도 좋을 것 같다는 결론이 내려졌다.
nifi 설치
우선 nifi를 사용하기 위해서는 설치를 해야 한다.
만약 간편하게 nifi를 설치하고 활용하고 싶다면 아래와 같이 도커 기반으로 설치하면 된다.
docker run \
--name nifi \
-p 8443:8443 \
-d \
-e NIFI_WEB_HTTPS_PORTS='8443' \
-e SINGLE_USER_CREDENTIALS_USERNAME=nifi \
-e SINGLE_USER_CREDENTIALS_PASSWORD=password1234 \
apache/nifi:latest
위 설정에서 포트 설정은 8443이 기본이다. 만약 다른 포트를 원한다면 설정 후 -p 옵션에서 함께 설정한다.
사용자의 패스워드는 12자 이상이어야 하며, 사용자를 설정하지 않을 경우 별도의 로그인 과정 없이 로그인이 가능하다.
도커가 아닌 일반적인 설치를 원한다면 다음과 같이 설치할 수 있다.
우선 다음 사이트에서 버전을 먼저 확인하고 진행한다.
# wget, java 설치
# 굳이 기재하진 않겠지만, JAVA_HOME까지 설정해줘야 원활하게 작동한다. (안해줘도 돌아가긴 함)
yum install -y wget java-1.8.0-devel
# 바이너리 설치파일 다운로드
wget --no-check-certificate https://dlcdn.apache.org/nifi/1.21.0/nifi-1.21.0-bin.zip
# 압축 해제
unzip nifi-1.21.0-bin.zip
여기서 현재 포스팅에서 PostgreSQL을 주로 사용할 예정이므로, PostgreSQL JDBC Driver를 추가로 설치해준다.
cd nifi-1.21.0/lib
wget https://repo1.maven.org/maven2/org/postgresql/postgresql/42.2.24/postgresql-42.2.24.jar
다음으로 nifi를 설정한다.
vim ./../conf/nifi.properties
# IP, Port 설정. 이 때 IP는 사용자가 직접 웹에 입력할 IP를 입력한다.
nifi.web.https.host=172.30.xx.xx
nifi.web.https.port=8443
설정이 완료되었다면 사용자를 생성한다. 비밀번호는 마찬가지로 12자 이상으로 설정한다.
만약 별도의 로그인이 필요하지 않다면 아래 과정은 생략해도 무방하다.
cd ./../bin
./nifi.sh set-single-user-credentials {id} {password}
마지막으로 NIFI의 메모리를 설정한다.
기본적으로 512 mb로 메모리가 설정되어 있는데, NIFI는 메모리를 많이 사용하기에 이 정도 메모리로는 Out of memory 에러가 발생할 확률이 높으므로 메모리를 올려준다.
vim ./../conf/bootstrap.conf
java.arg.2=-Xms2048m
java.arg.3=-Xms4096m
설정 완료되었다면 아래 명령어를 통해 실행한다.
cd ..
# 실행
./bin/nifi.sh start
# 종료
./bin/nifi.sh stop
nifi는 무거운 프로그램이기에 실행되는데 조금 긴 시간이 소요된다.
nifi RDB to RDB 플로우 만들기
우선 다음과 같은 테이블이 존재한다고 가정하자. 해당 테이블은 mart_db 테이블의 mart_scm 스키마 안에도 mart_tbl 이름으로 동일하게 생성되어있다.

https://{IP}:8443/nifi URL로 접속한 후 설정한 ID/PW로 로그인한다.
우선 RDB와 Mart에 접속하는 컨트롤러를 생성한다. 배경화면 우클릭 후 Configure를 선택한다.

아래와 같은 창이 나타나면 CONTROLLER SERVICES를 선택하고 우측 상단의 + 버튼을 누른다.

Controller Service 중 DBCPConnectionPool을 선택하고 다음과 같이 입력해준다.

이 작업으로 target_db와 source_db 두 개의 커넥션 풀을 생성하고 enable한다.

*스크린샷에서는 빼먹었는데, AvroReader도 만들어줘야 한다.
다음으로 이제 데이터 플로우를 생성한다.
크게 다음 로직을 따라 수행하도록 설정한다.
- Source DB에 타겟 테이블 존재여부 확인
- Target DB에 타겟 테이블 존재여부 확인
- Source DB로부터 데이터 추출
- Target DB에 추출한 데이터 UPSERT
먼저 테이블 존재 여부는 ExecuteSQL과 RouteOnAttribute를 사용해 구성한다.
추가로 에러, unmatch 내역은 로그 파일에 저장하도록 구성한다.

| Name | Type | Properties |
| source db 테이블 확인 | ExecuteSQL 1.21.0 | Database Connection Pooling Service : source_db SQL select query : SELECT * FROM information_Schema.tables WHERE table_name='test_tbl' AND table_schema='test_scm' AND table_catalog='test_db'; |
| 결과가 1인지 확인 | RouteOnAttribute 1.21.0 | Routing Strategy : Route to 'matched' if any matches checkResult : ${executesql.row.count:equals(1)} |
| 에러 로깅 | PutFile 1.21.0 | Directory : /tmp/rdb/${now():toNumber():minus(864000000):format('yyyy-MM-dd')}/ Conflict Resolution Strategy : replace Create Missing Directories : true |
*checkResult는 직접 만드는 것으로, 결과의 갯수가 1인지 확인한다. (테이블이 존재하지 않으면 0이기 때문)
*target db에 대한 내용은 위를 참고하여 생성하면 되므로 기재하지 않았다.
*에러는 위와 같이 설정할 경우 /tmp/rdb/날짜/ 폴더가 생성되며, 플로우 내용이 기재된다.
다음으로 데이터를 퍼오는 부분은 아래와 같이 설정한다.

| Name | Type | Properties |
| 데이터 퍼오기 | ExecuteSQL 1.21.0 | Database Connection Pooling Service : source_db SQL select query : SELECT * FROM test_scm.test_tbl; |
| 퍼온 데이터 저장 | PutDatabaseRecord 1.21.0 | Record Reader : AvroReader Database Type : PostgreSQL Statement Type : UPSERT Database Connection Pooling Serivce : target_db Schema Name : mart_scm Table Name : mart_tbl |
이대로 실행해도 되지만, 그러면 계속해서 데이터를 받아오므로 스케줄링을 설정하고 실행한다.
물론 Stopped 상태에서는 우클릭을 하면 "Run Once" 기능이 있는데, 이걸 누르면 이름 그대로 단 한 번만 실행된다.
다른 모든 프로세서는 Run 상태로 두고, 시작이 되는 프로세서만 Stopped 상태에서 Run Once 기능을 실행해주면 된다.
하지만 스케줄링을 거는 방법도 기재해놓기 위해 스케줄링을 기반으로 1분에 한 번 실행되도록 설정한다.
스케줄링은 시작이 되는 프로세서에만 걸어주면 되므로, "source db 테이블 확인" 프로세서에 걸어준다.
Cron 기반이며, nifi cron은 "초 분 시 일 월 요일" 이다.

이제 전체 프로세서를 실행하면 매 분마다 데이터 플로우가 동작하며, 아래와 같이 타겟 DB에 데이터가 정상적으로 입력됨을 확인할 수 있다.
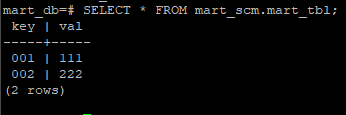
PostgreSQL의 Array 타입은 지원하지 않음!
PostgreSQL에는 Character Varying[] 혹은 Integer[] 같은 Array 형 변수가 존재할 수 있다.
다만 이 부분은 실험 결과 NIFI로 퍼올 때 테이블 구조를 bytes로 퍼오기 때문에, 퍼오는 것은 가능하나 다른 데이터베이스에 삽입할 때는 에러가 발생한다. (Object를 Array로 변환할 수 없다는 에러가 발생)
HIVE to RDB
Hadoop의 DB (Hive, HBase)의 경우 하는 방법은 알아냈으나, 현재 포스팅을 작성중인 집 컴퓨터에는 하둡이 설치되어 있지 않아 회사에서 연습했던 걸 기반으로 그냥 어떻게 하는 지 정도만 기재해놓을까 한다.
우선 Hive에 연결할 컨트롤러를 작성한다.
| Name | Type | Properties |
| hive_db | HiveConnectionPool | Database Connection URL : jdbc:hive://{ip}:{port}/{db} Database User : hadoop Database Password : {password} |
다음으로 데이터 플로우를 작성한다. 순서는 RDB와 마찬가지로 아래와 같이 지정한다. (위와 중복되는 부분은 - 로 기재한다.)
| Name | Type | Properties |
| Hive 테이블 존재여부 확인 | SelectHiveQL | Hive Database Connection Pooling Service : hive_db HiveQL Select Query : SHOW TABLES IN default LIKE '{table_name}' Output Format : Avro Normalize Table/Columns Names : false |
| 결과가 1인지 확인 | RouteOnAttribute | Routing Strategy : Route to 'matched' if any matches checkResult : ${selecthiveql.row.count:equals(1)} |
| RDB 테이블 존재여부 확인 | - | - |
| 결과가 1인지 확인 | - | - |
| Hive 데이터 추출 | SelectHiveQL | Hive Database Connection Pooling Service : hive_db HiveQL Select Query : SELECT * FROM '{table_name}' Output Format : Avro Normalize Table/Columns Names : false |
| 추출한 데이터 저장 | - | - |
| 에러 로깅 | - | - |
HBase to RDB
마지막은 HBase의 데이터를 RDB에 저장하는 작업이다.
개인적으로 Hive/RDB to RDB는 중간에 처리하는 일 없이 그대로 삽입할 수 있었으나, HBase는 그대로 삽입을 할 수가 없어 이 부분이 조금 어려웠던 것 같다.
그래서 떠올린 방법은 ReplaceText로 HBase 양식대로 퍼와진 데이터를 RDB에 삽입할 수 있는 양식으로 변경하는 것이다.
마찬가지로 집 컴퓨터에 하둡이 설치되어 있지 않아 회사에서 한 연습한 내용만 기재한다.
컨트롤러는 아래와 같이 구성한다.
*JsonReader도 필요했던 것으로 기억한다. 굳이 아래에 추가하진 않았다.
| Name | Type | Properties |
| hbase_db | HBase_1_1_2_ClientService | Zookeeper Quorum : {hostname} Zookeeper Client Port : 2181 Zookeeper ZNode Parent : /hbase |
데이터 플로우는 아래와 같이 구성했다.
참고로 테이블 존재 여부 확인은 HBase에서 어떻게 하는지 몰라 제외했다.
| Name | Type | Properties |
| HBase 데이터 추출 | GetHBase | HBase Client Service : HBaseDB Table Name : {table} |
| 결과 Flatten | FlattenJson | - |
| 텍스트 제거 | ReplaceText | Search Value : cells. Replacement Value : "Set empty string" 선택 |
| 추출한 데이터 저장 | - | - |
| 에러 로깅 | - | - |
*결과를 flatten 하면 각 컬럼값이 cells.{column}이 되므로, 텍스트 제거 단계에서 "cells."를 제거했다.
*이 부분은 테이블을 어떻게 구성했느냐에 따라 다르므로, 텍스트 제거 프로세서를 여러 개 두고 데이터 타입에 맞게 작업하면 된다.
'IT 지식 > 빅데이터 & 분석' 카테고리의 다른 글
| Hive와 HDFS (1) | 2024.05.02 |
|---|---|
| Hive의 메타스토어로 MariaDB를 설정했을 때 나는 에러 (1) | 2024.02.26 |
| JAVA-HIVE/HBASE 간 통신_HBase 통신 (0) | 2023.01.22 |
| JAVA-HIVE/HBASE 간 통신_Hive 통신 (0) | 2023.01.22 |
| JAVA-HIVE/HBASE 간 통신_Hadoop/HIVE/HBase 설치 (1) | 2023.01.21 |



