개발이 완료된 프로그램이 있다. 해당 프로그램은 필요 이상의 인프라 (DB, RabbitMQ 등)를 요구했고, 이 점으로 인해 설치가 어렵고 프로그램의 복잡도가 높았다.
그래서 해당 프로그램의 인프라 의존도를 낮추기 위한 수정 작업을 수행했다. 그 중 하나는 Redis에 저장하는 정보를 캐시에 저장하여 Redis에 대한 의존성을 없애는 작업이었다.
아래는 해당 작업을 위해 공부한 내용이다.
Cache
캐시는 데이터의 값을 복사해놓는 임시 저장소이다.
주 메모리에 비해 데이터에 접근하는 시간이 짧기 때문에, 자주 사용하는 정보를 임시로 저장해놓고 사용한다.
스프링에서 Cache는 아래의 어노테이션을 사용하면 쉽게 사용할 수 있다.
- @Cacheable
- @CachePut
- @CacheEvict
데이터 준비
실습을 위해 간단한 테이블을 만들었다.

그리고 해당 테이블에 프로시져를 사용하여 10,000개의 데이터를 넣어주었다.
DELIMITER $$
CREATE PROCEDURE insertUntil(max INT)
BEGIN
DECLARE i INT DEFAULT 1;
WHILE (i <= max) DO
INSERT INTO test.test_table VALUE (i, i, i, i, i, i, i, i, i, i, i);
SET i = i+1;
END WHILE;
END$$
DELIMITER ;CALL insertUntil(10000);
프로젝트 생성
이제 프로젝트를 만들어주자. 설정 사항은 아래와 같다.
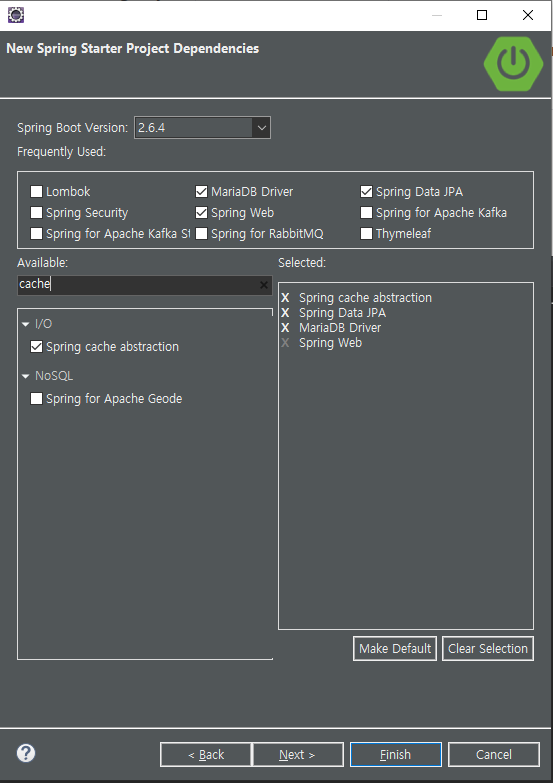
그럼 다음과 같은 캐시 관련 dependency가 pom.xml에 만들어지게 된다.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>위의 디펜던시는 기본적인 cache 기능을 사용할 수 있게 도와주는데, 별도의 선언이 없다면 로컬 메모리에 저장되는 ConcurrentMapCacheManager가 자동으로 빈에 등록되어 사용된다.
물론 이는 별도의 모듈을 선언하여 사용할 수 있다.
대표적인 예시로는 자주 사용되는 ehcache가 있다.
ehcache 사용을 원한다면 다음의 디펜던시를 추가하고 xml과 Configuration 클래스 설정 후
spring.cache.jcache.config=classpath:{filename}.xml 로 설정해주면 된다.
<dependency>
<groupId>net.sf.ehcache</groupId>
<artifactId>ehcache</artifactId>
<version>2.10.6</version>
</dependency>- ehcache 설정 예시 : https://www.baeldung.com/spring-boot-ehcache
그 후에는 application.properties에 기본적인 설정들을 추가한다.
server.address=0.0.0.0
spring.jpa.show-sql=true
spring.jpa.generate-ddl=false
spring.datasource.driverClassName=org.mariadb.jdbc.Driver
spring.datasource.url=jdbc:mariadb://${linuxServer}:3306/test
spring.datasource.username=root
spring.datasource.password=0000
기본 캐시 사용방법
가장 먼저 메인 클래스에 @EnableCaching 어노테이션을 추가한다.
package com.example.demo;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cache.annotation.EnableCaching;
@SpringBootApplication
@EnableCaching
public class CachetestApplication {
public static void main(String[] args) {
SpringApplication.run(CachetestApplication.class, args);
}
}
그리고 domain과 repository 정도를 설정해준다.
package com.example.demo.domain;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.Id;
import javax.persistence.Table;
@Entity
@Table(name="test_table")
public class TestDomain {
@Id
@Column(name="id")
private int id;
@Column(name="col1")
private String col1;
@Column(name="col2")
private String col2;
@Column(name="col3")
private String col3;
@Column(name="col4")
private String col4;
@Column(name="col5")
private String col5;
@Column(name="col6")
private String col6;
@Column(name="col7")
private String col7;
@Column(name="col8")
private String col8;
@Column(name="col9")
private String col9;
@Column(name="col10")
private String col10;
}package com.example.demo.repository;
import java.util.List;
import org.springframework.data.repository.CrudRepository;
import org.springframework.stereotype.Repository;
import com.example.demo.domain.TestDomain;
@Repository
public interface TestRepository extends CrudRepository<TestDomain, Integer> {
// iterable > list 변환을 위해 명시
public List<TestDomain> findAll();
}
다음으로 사용자와 주고받을 컨트롤러를 작성한다.
추후 작성할 CacheService를 불러와, 데이터 전체를 SELECT 한 결과를 받을 것이고, 이에 대한 갯수 정도만 반환한다.
*시간 비교를 위해 조금이라도 더 시간을 끌어보고자 Repository의 count() 메소드를 사용하지 않았다.
*그런데 캐시는 결국 둘다 1ms로 큰 의미는 없는 행동이었다.
package com.example.demo.controller;
import java.util.Date;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import com.example.demo.service.CacheService;
@RestController
public class CacheController {
@Autowired CacheService cacheService;
Logger log = LoggerFactory.getLogger(CacheController.class);
@GetMapping("/cache/read")
public long getCacheCount() {
long now = new Date().getTime(); //millisecond 저장
long count = cacheService.getAllData().size();
long after = new Date().getTime();
log.info("CacheController.getCacheCount() Method done in : {} millisec", after - now);
return count;
}
}
이제 서비스를 작성한다.
가장 먼저 실행할 어노테이션은 @Cacheable이다.
@Cacheable은 파라미터로 value을 받을 수 있는데, 만약 value에 해당하는 값이 캐시에 존재한다면 해당 값을 반환하고, 그렇지 않다면 함수 내용을 수행하여 값을 반환하게 된다.
코드는 아래와 같다.
package com.example.demo.service;
import java.util.Date;
import java.util.List;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.cache.annotation.Cacheable;
import org.springframework.stereotype.Service;
import com.example.demo.domain.TestDomain;
import com.example.demo.repository.TestRepository;
import org.slf4j.Logger;
@Service
public class CacheService {
Logger log = LoggerFactory.getLogger(CacheService.class);
@Autowired TestRepository repo;
@Cacheable(value = "count")
public List<TestDomain> getAllData() {
log.info("CacheService.getCount() INIT");
return repo.findAll();
}
}
추가로 키도 설정이 가능하다. 사용법은 아래 ex와 같으며, 만약 아래처럼 사용 시 입력되는 countKey 별로 Cache가 생성되고, 만약 countKey가 null일 경우 anonymous 키로 생성이 될 것이다.
ex) @Cacheable(value = "도메인명", key="#파라미터명")
@Cacheable(value = "count", key="#countKey ?: 'anonymous'"
public List<TestDomain> getAllData(String countKey) {
}
위 경우는 사용자마다 다르게 사용되는 캐시, 예를 들어 사용자 권한 별 메뉴 접근 권한 같은 것에 유용하게 사용될 수 있다.
이제 해당 URL로 접속을 수행한다면 아래와 같은 로그를 확인할 수 있다.

CacheService 클래스의 getCount() 함수가 실행되었고, 실행 시간은 244밀리초가 소요되었다.
그렇다면 한 번 더 해당 서비스를 접속하면 어떨까?
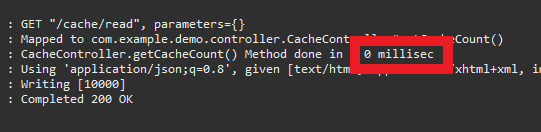
이미 Cache에 데이터가 저장된 상태이기 때문에 함수는 실행되지 않았고, 실행 시간 또한 고작 1 밀리초도 소요되지 않았다.
하지만 이 상태에서 DB에 데이터를 추가로 삽입하면 어떻게 될까?
INSERT INTO test_table VALUES (10001, 10001, 10001, 10001, 10001, 10001, 10001, 10001, 10001, 10001, 10001);위의 SQL을 실행한 후 다시 한 번 위의 URL을 호출해보았다. 하지만 결과는 이전과 같은 10,000 이었다.
이유라면 이미 데이터를 불러와서 캐시에 저장한 상태이고, 갱신 작업은 없었기 때문이다.
그래서 캐시를 주기적으로 갱신하기 위한 작업이 필요한데, 이 때 사용되는 것이 바로 @CachePut 어노테이션이다.
@CachePut은 캐시가 존재하면 실행하지 않는 @Cacheable과 달리 반드시 내부 로직을 실행하며, 캐시 내용을 수정하는 작업을 담당한다.
@CachePut은 다음과 같이 사용할 수 있다. 또한 @Cacheable과 마찬가지로 key도 설정할 수 있다.
@CachePut(value = "count")
public List<TestDomain> getAllDataPut() {
log.info("CacheService.getCountPut() INIT");
return repo.findAll();
}
이제 해당 함수를 호출하는 컨트롤러를 만들어 실행시켜보면, return 값이 10,001로 갱신되었고, 앞서 만든 컨트롤러에 접속해도 마찬가지로 갱신된 10,001이 정상 출력됨을 확인할 수 있다.
다음은 @CacheEvict인데, 이 함수는 캐시의 삭제를 담당한다.
아래와 같이 만들어 한 번 수행해보자.
@CacheEvict(value = "count")
public void getAllDataEvi() {
log.info("CacheService.getAllDataEvi() INIT");
}위의 함수를 실행시킨 뒤 다시 @Cacheable 함수를 실행시켜보면 캐시가 삭제되어 다시 한 번 DB에서 데이터들을 불러오는 것을 확인할 수 있다.
+) 갑자기 생긴 궁금증
어차피 프로그램이 종료되면 삭제되는 데이터이니, 변수로 만들면 속도 차이가 어떨까?
궁금증 해결을 위하여 생성 후 모든 데이터를 불러와 변수로 저장하는 새로운 서비스를 만들어주었다.
package com.example.demo.service;
import java.util.List;
import javax.annotation.PostConstruct;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import com.example.demo.domain.TestDomain;
import com.example.demo.repository.TestRepository;
@Service
public class LocalService {
Logger log = LoggerFactory.getLogger(LocalService.class);
@Autowired TestRepository repo;
List<TestDomain> testDomainList;
@PostConstruct
public void setTestDomainList() {
this.testDomainList = repo.findAll();
}
public List<TestDomain> getTestDomainList() {
log.info("LocalService.getTestDomainList() INIT");
return testDomainList;
}
public List<TestDomain> updateTestDomainList() {
log.info("LocalService.updateTestDomainList() INIT");
this.testDomainList = repo.findAll();
return testDomainList;
}
}
결과는 캐시를 사용할 때와 다르지 않았다.
*데이터가 적어서 그런가 싶어 1,000,000 개까지 데이터를 늘려보아도 결과는 다르지 않았다.

+) 주의점 : 동일 클래스 내에서 Cacheable 함수 호출 시 해당 함수는 항상 수행된다.
'실습 > 리눅스 서버 + 스프링 부트' 카테고리의 다른 글
| Redis In Java_자료구조 (0) | 2022.03.20 |
|---|---|
| Spring Cloud Config (0) | 2022.03.13 |
| httpd (아파치 웹 서버) (0) | 2022.03.06 |
| Filter, Interceptor, AOP (0) | 2022.02.01 |
| ntp를 이용한 타임서버 구축 (0) | 2022.01.22 |



